一、熵、条件熵、信息增益
数学概念:https://zhuanlan.zhihu.com/p/41134986
二、决策树分类
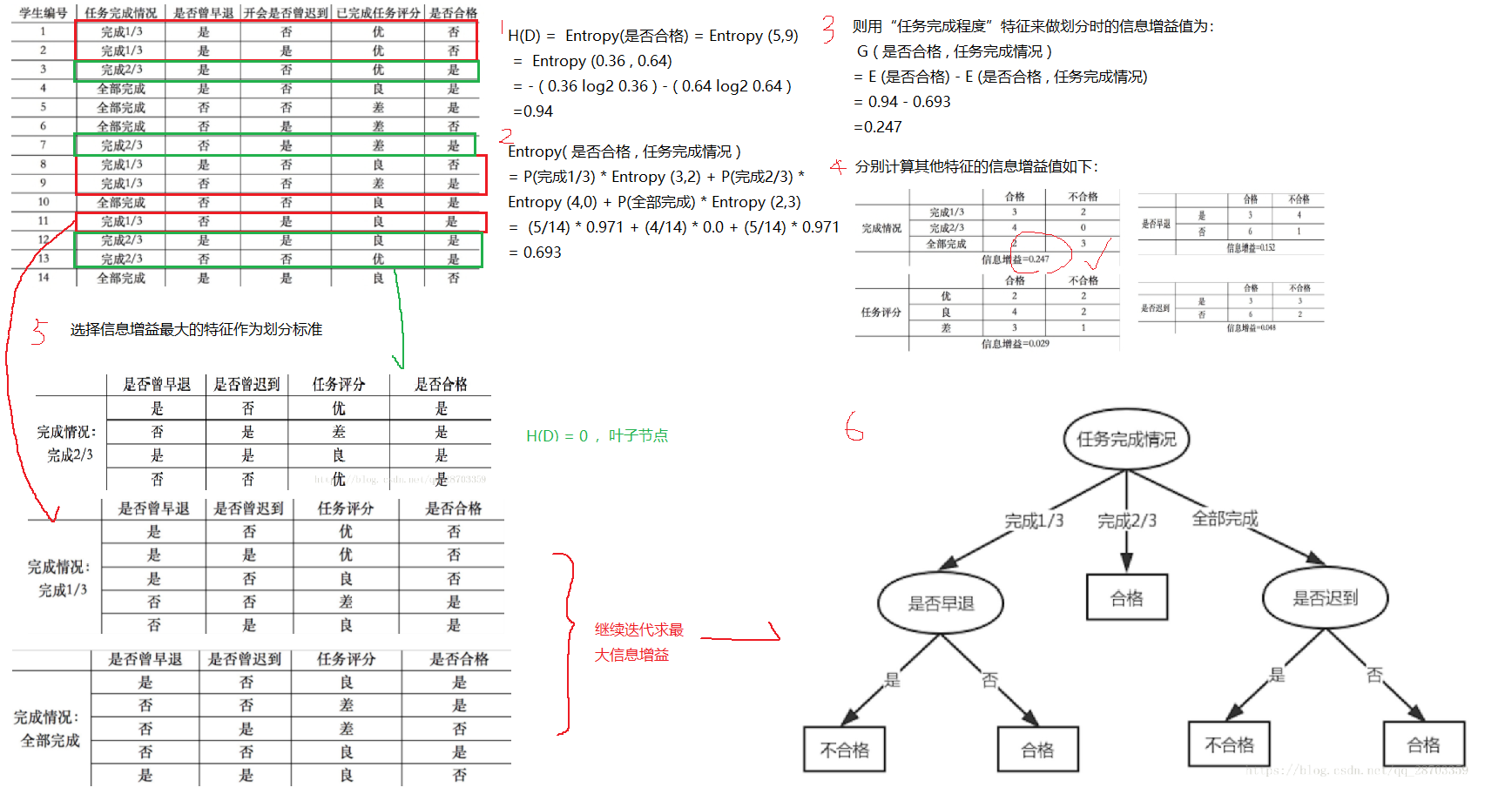
我们在构造决策树的时候,会基于纯度来构建。而经典的 “不纯度”的指标有三种,分别是信息增益(ID3 算法)、信息增益率(C4.5 算法)以及基尼指数(Cart 算法)。
信息增益:加入的某种特征可以减少的信息熵
计算公式,是父亲节点的信息熵减去所有子节点的信息熵
1.ID3:使用的分类标准是信息增益
缺点:
- ID3 没有剪枝策略,容易过拟合 (过拟合/欠拟合解释:https://blog.csdn.net/xuaho0907/article/details/88649141)
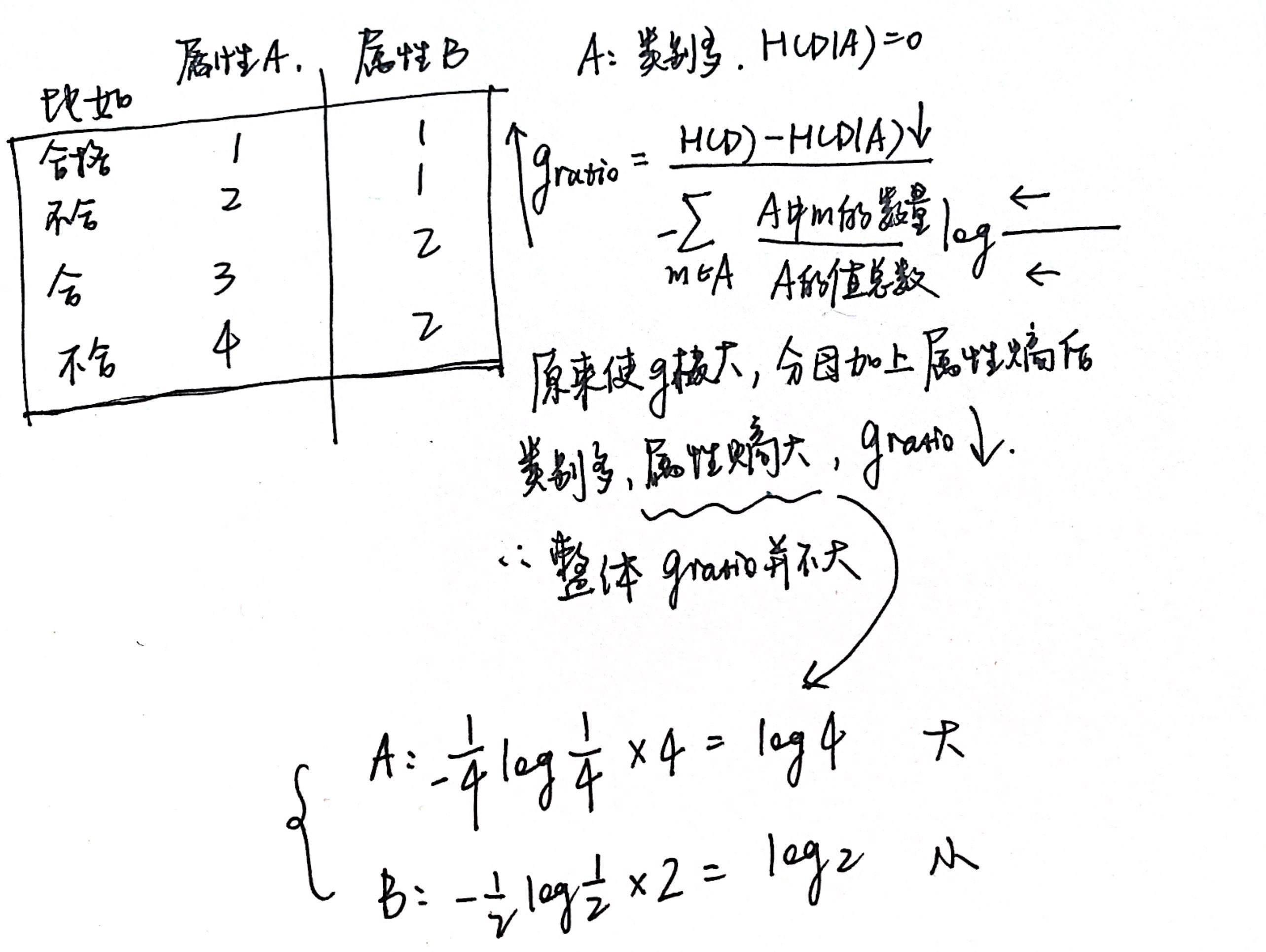
- 信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1。因为每一个样本的编号都是不同的,也就是说,来了一个预测样本,你只要告诉我编号,其它特征就没有用了,这样生成的决策树显然不具有泛化能力。
- 只能用于处理离散分布的特征;
- 没有考虑缺失值。
https://www.cnblogs.com/yonghao/p/5096358.html 中写道:
对于连续型数据,ID3原本是没有处理能力的,只有通过离散化将连续性数据转化成离散型数据再进行处理。可以直接采用等距离数据划分的离散化方法。该方法先对数据进行排序,然后将连续型数据划分为多个区间,并使每一个区间的数据量基本相同
举例:
Q1:为什么“对可取值数目较多的特征有所偏好”?

2. C4.5
C4.5 算法最大的特点是克服了 ID3 对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。
但是,增益率可能对取值较小的属性有所偏好。因此,C4.5不是直接用增益率最大的作为划分属性,而是用启发式:先从候选划分属性中找出【信息增益】高于平均水平的属性,再从中选择【信息增益率】最高的。
Q2:为什么可以 "克服了 ID3 对特征数目的偏重" 这一缺点?
更详细可以参考:https://blog.csdn.net/u013164528/article/details/44359677
特点:
- 信息增益率
- 悲观剪枝
- 可以对连续属性进行处理
- 可以处理缺失值
3. CART分类树:基尼系数
