二叉查找树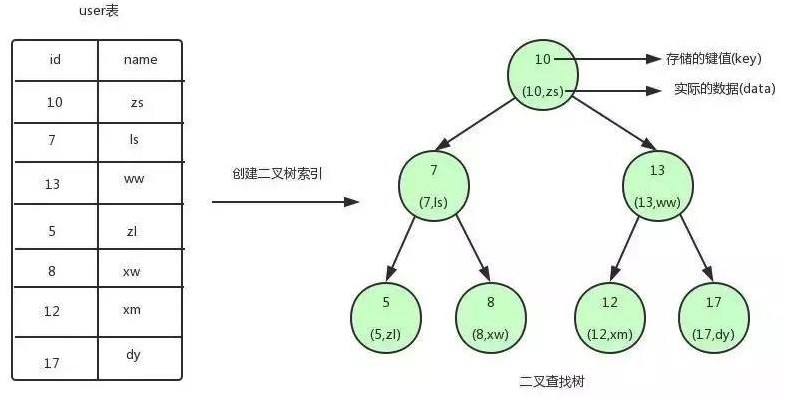
从从上图可以看出user表建立了一个二叉查找树的索引。
图中的圆为二叉查找树的节点,节点中存储了键(key)和数据(data)。键对应 user 表中的 id,数据对应 user 表中的行数据。
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
如果我们需要查找 id=12 的用户信息,利用我们创建的二叉查找树索引,查找流程如下:
1.将根节点作为当前节点,把 12 与当前节点的键值 10 比较,12 大于 10,接下来我们把当前节点>的右子节点作为当前节点。
2.继续把 12 和当前节点的键值 13 比较,发现 12 小于 13,把当前节点的左子节点作为当前节点。
3.把 12 和当前节点的键值 12 对比,12 等于 12,满足条件,我们从当前节点中取出 data,即 id=12,name=xm。
平衡二叉树
上面我们讲解了利用二叉查找树可以快速的找到数据。但是,如果上面的二叉查找树是这样的构造: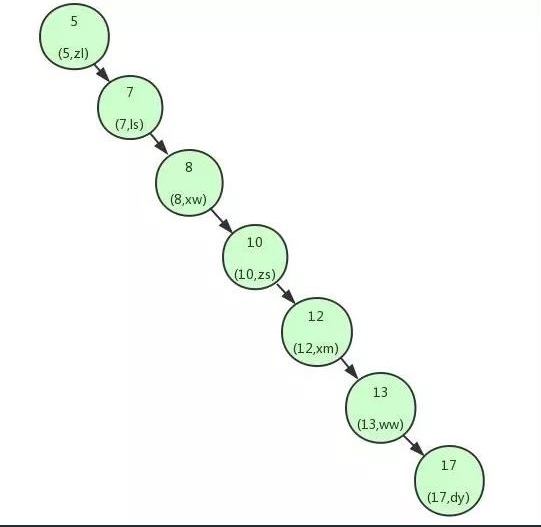
这个时候可以看到我们的二叉查找树变成了一个链表。如果我们需要查找 id=17 的用户信息,我们需要查找 7 次,也就相当于全表扫描了。 导致这个现象的原因其实是二叉查找树变得不平衡了,也就是高度太高了,从而导致查找效率的不稳定。
为了解决这个问题,我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树了。平衡二叉树又称 AVL 树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过 1。
下面是平衡二叉树和非平衡二叉树的对比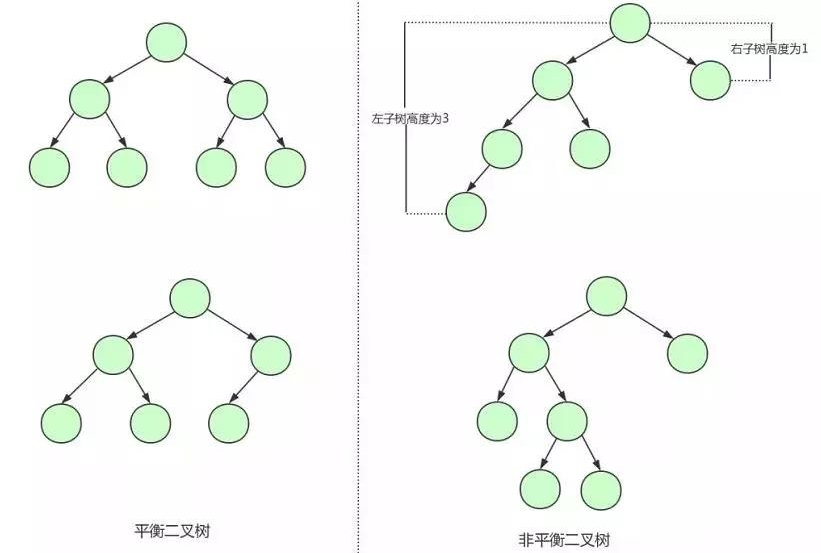
B树
如果我们有海量的数据,可以想象到二叉树的节点将会非常多,高度也会极其高,我们查找数据时也会进行很多次磁盘IO,我们查找数据的效率将会很低,为了解决平衡二叉树的这个弊端,我们应该寻找一种单个节点可以存储多个键值和数据的平衡树。也就是我们接下来要说的 B 树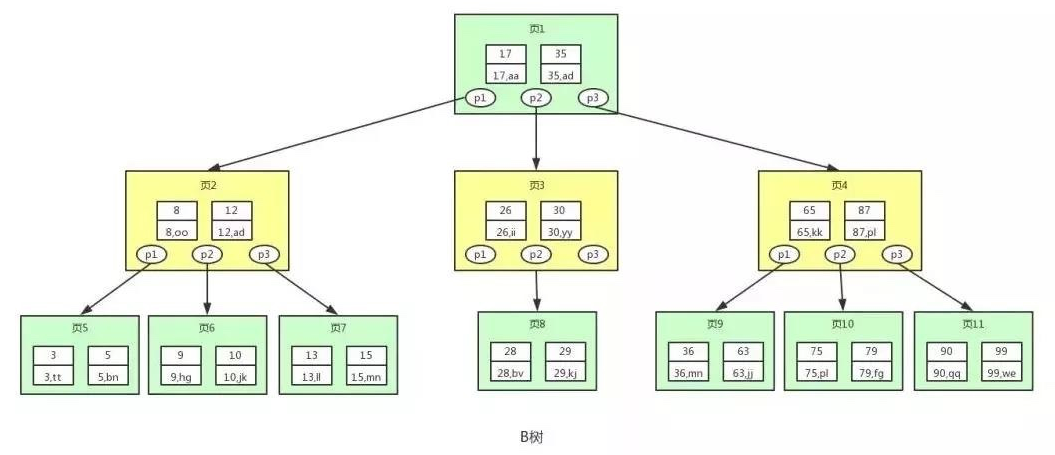
图中的每个节点称为页,页就是我们上面说的磁盘块,在 MySQL 中数据读取的基本单位都是页,所以我们这里叫做页更符合 MySQL 中索引的底层数据结构。
从上图可以看出,B 树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的 B 树为 3 阶 B 树,高度也会很低。
基于这个特性,B 树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。
假如我们要查找 id=28 的用户信息,那么我们在上图 B 树中查找的流程如下:
1.先找到根节点也就是页 1,判断 28 在键值 17 和 35 之间,那么我们根据页 1 中的指针 p2 找到页 3。
2.将 28 和页 3 中的键值相比较,28 在 26 和 30 之间,我们根据页 3 中的指针 p2 找到页 8。
3.将 28 和页 8 中的键值相比较,发现有匹配的键值 28,键值 28 对应的用户信息为(28,bv)
B+树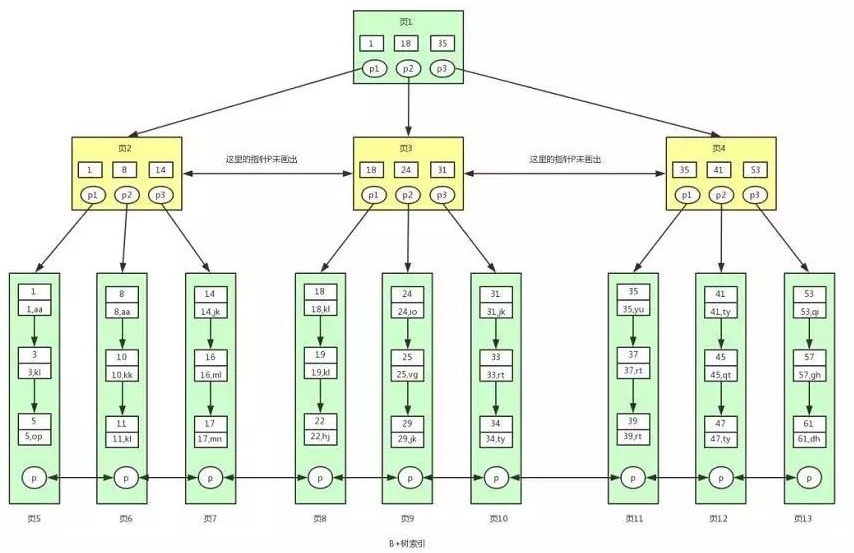
B+ 树和 B 树的区别:
①B+ 树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。之所以这么做是因为在数据库中页的大小是固定的,InnoDB 中页的默认大小是16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的 IO 次数又会再次减少,数据查询的效率也会更快
②因为 B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而 B 树因为数据分散在各个节点,要实现这一点是很不容易的。