AdaBoost是adaptive boosting的缩写,其运行过程如下:
1.训练数据中得每个样本,并赋予其一个权重,这些权重构成了向量D。
一开始,这些权重都初始化成相等值。
2.首先再训练数据上训练出一个弱分类器并计算改分类器的错误率,然后在同一数据集上再次训练弱分类器。
3.在分类器的第二次训练中,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。
为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。其中,错误率ε定义为:
ε = 未正确分类的样本数目/所有样本数目
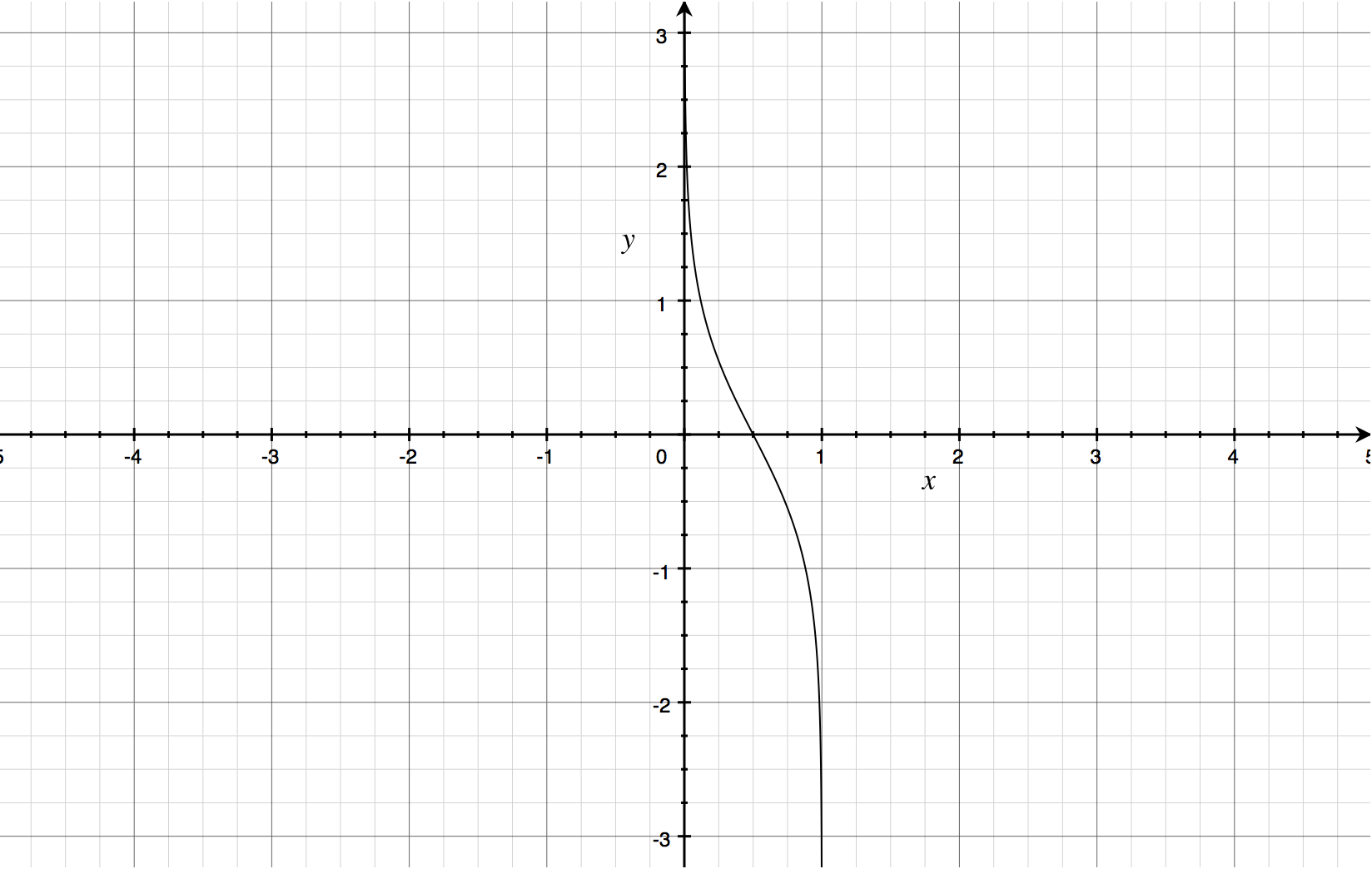
而alpha的计算公式如下:α = 1/2 * ln((1-ε)/ε)
4.计算出alpha值之后,可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而错分样本的权重升高。D的计算方法如下。
如果某个样本被正确分类,那么该样本的权重更改为:
D (t+1)=D(t)e-α/Sum(D)
而如果某个样本被错分,那么该样本的权重更改为:
D (t+1)=D(t)eα/Sum(D)
5.在计算出D之后,AdaBoost又开始进入下一轮迭代。直到错误率为0或者弱分类器的数目达到用户的指定值为止。