1.
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。
举例来说,数值0x2211使用两个字节储存:高位字节是0x22,低位字节是0x11。
大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
小端字节序:低位字节在前,高位字节在后,即以0x1122形式储存。
同理,0x1234567的大端字节序和小端字节序的写法如下图。
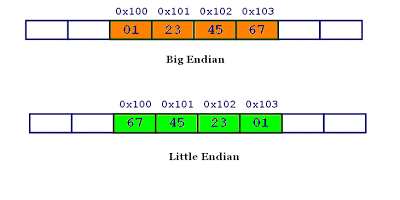
2.
我一直不理解,为什么要有字节序,每次读写都要区分,多麻烦!统一使用大端字节序,不是更方便吗?
上周,我读到了一篇文章,解答了所有的疑问。而且,我发现原来的理解是错的,字节序其实很简单。
3.
首先,为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
4.
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。
理解这一点,才能理解计算机如何处理字节序。
5.
字节序的处理,就是一句话:
"只有读取的时候,才必须区分字节序,其他情况都不用考虑。"
处理器读取外部数据的时候,必须知道数据的字节序,将其转成正确的值。然后,就正常使用这个值,完全不用再考虑字节序。
即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
6.
字节序转换的例子
不同cpu平台上字节序通常也不一样,下面写个简单的C程序,它可以测试不同平台上的字节序。
1 #include <stdio.h> 2 #include <netinet/in.h> 3 int main() 4 { 5 int i_num = 0x12345678; 6 printf("[0]:0x%x ", *((char *)&i_num + 0)); 7 printf("[1]:0x%x ", *((char *)&i_num + 1)); 8 printf("[2]:0x%x ", *((char *)&i_num + 2)); 9 printf("[3]:0x%x ", *((char *)&i_num + 3)); 10 11 i_num = htonl(i_num); 12 printf("[0]:0x%x ", *((char *)&i_num + 0)); 13 printf("[1]:0x%x ", *((char *)&i_num + 1)); 14 printf("[2]:0x%x ", *((char *)&i_num + 2)); 15 printf("[3]:0x%x ", *((char *)&i_num + 3)); 16 17 return 0; 18 }
在80X86CPU平台上,执行该程序得到如下结果:
[0]:0x78
[1]:0x56
[2]:0x34
[3]:0x12
[0]:0x12
[1]:0x34
[2]:0x56
[3]:0x78
分析结果,在80X86平台上,系统将多字节中的低位存储在变量起始地址,使用小端法。htonl将i_num转换成网络字节序,可见网络字节序是大端法。