Overview of Checkpoints
A checkpoint is a crucial mechanism in consistent database shutdowns, instance recovery, and Oracle Database operation generally. The term checkpoint has the following related meanings:
■A data structure that indicates the checkpoint position, which is the SCN in the redo stream where instance recovery must begin.The checkpoint position is determined by the oldest dirty buffer in the database buffer cache. The checkpoint position acts as a pointer to the redo stream and is stored in the control file and in each data file header.
■The writing of modified database buffers in the database buffer cache to disk
检查点在数据库一致性关闭、实例恢复以及数据库一般性操作的过程是至关重要的机制。检查点有以下几个相关的含义:
■一个声明检查点位置的数据结构,是指SCN在重做日志流中的位置,即实例恢复的起点。这个检查点位置由数据库缓存中最旧的脏块来决定。检查点位置是一个指向重做日志流的指针,存储在控制文件中和每个数据文件的头部。
■把被修改过的数据库缓存写入到磁盘中的写的操作。
Purpose of Checkpoints
Oracle Database uses checkpoints to achieve the following goals:
■Reduce the time required for recovery in case of an instance or media failure
■Ensure that dirty buffers in the buffer cache are written to disk regularly
■Ensure that all committed data is written to disk during a consistent shutdown
数据库使用检查点达到以下几个目标:
■减少实例故障或介质故障所需要的恢复时间
■确保脏缓存定期地被写入到磁盘中
■确保所有提交的数据在一致性关闭的时候被写入到磁盘中
When Oracle Database Initiates Checkpoints
The checkpoint process (CKPT) is responsible for writing checkpoints to the data file headers and control file. Checkpoints occur in a variety of situations. For example, Oracle Database uses the following types of checkpoints:
检查点进程(CKPT)负责把检查点写入到数据文件头部和控制文件中。在不同的情况下会发生不同的检查点,在Oracle数据库就有以下几种类型的检查点:
■Thread checkpoints
The database writes to disk all buffers modified by redo in a specific thread before a certain target. The set of thread checkpoints on all instances in a database is a database checkpoint. Thread checkpoints occur in the following situations:
–Consistent database shutdown
–ALTER SYSTEM CHECKPOINT statement
–Online redo log switch
–ALTER DATABASE BEGIN BACKUP statement
线程检查点:在某个确切的目标前数据库在一个指定的线程中把所有重做日志修改的缓存写入到磁盘中。在一个数据库的所有实例上的线程检查点集合称为一个数据库检查点。线程检查点在以下情况会发生:
--数据库一致性关闭
--ALTER SYSTEM CHECKPOINT语句
--在线重做日志切换
--ALTER DATABASE BEGIN BACKUP语句
■Tablespace and data file checkpoints
The database writes to disk all buffers modified by redo before a specific target. A tablespace checkpoint is a set of data file checkpoints, one for each data file in the tablespace. These checkpoints occur in a variety of situations, including making a tablespace read-only or taking it offline normal, shrinking a data file, or executing ALTER TABLESPACE BEGIN BACKUP.
■Incremental checkpoints
An incremental checkpoint is a type of thread checkpoint partly intended to avoid writing large numbers of blocks at online redo log switches. DBWn checks at least every three seconds to determine whether it has work to do. When DBWn writes dirty buffers, it advances the checkpoint position, causing CKPT to write the checkpoint position to the control file, but not to the data file headers.
Other types of checkpoints include instance and media recovery checkpoints and checkpoints when schema objects are dropped or truncated.
■表空间和数据文件检查点
数据库在一个指定的目标前将所有重做日志修改的缓存写入到磁盘中。一个表空间的检查点是一个数据文件检查点的集合,对表空间中的每一个数据文件来说的一个检查点。这些检查点会在多个情形下发生,包括把一个表空间设置为只读,或者把表空间offline,收缩数据文件,或者执行ALTER TABLESPACE BEGIN BACKUP.
■增量检查点
一个增量检查点是线程检查点的一个类型,是线程检查点一定程度上为了防止当在线重做日志切换的时候一次性写太多数据。DBWn每三秒会决定是否有工作要做。当DBWn写脏缓存的时候,它会推进检查点的位置,促使CKPT在控制文件中写检查点位置,但是没有在数据文件头部写。
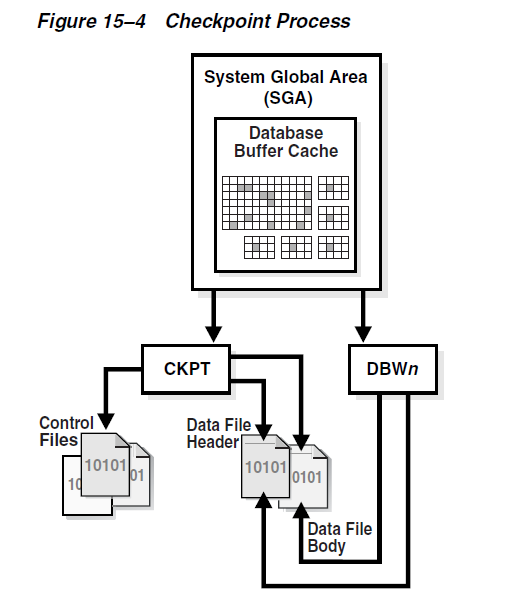
Checkpoint Process (CKPT)
The checkpoint process (CKPT) updates the control file and data file headers with checkpoint information and signals DBWn to write blocks to disk. Checkpoint information includes the checkpoint position, SCN, location in online redo log to begin recovery, and so on. As shown in Figure 15–4, CKPT does not write data blocks to data files or redo blocks to online redo log files.
检查点进程在控制文件和数据文件的头部更新检查点信息并且通知DBWn进程把块写到磁盘中。检查点信息包括检查点位置、SCN、以及实例恢复开始时在在线重做日志中的位置,以及其它。如图15-4中所示,CKPT进程并不会把数据块写到数据文件中和重做日志块到重做日志文件中。
--根据11G官方文档翻译,如有翻译不当,请不吝指正。