Kafka
Kafka 1
kafka中的数据单位也被称为message, 如果你以数据库的方式理解kafka的话, 你也许会以为message类似于数据库中的行或者记录. message在kafka看来仅仅不过是一系列的字节, 所以对于kafka来说message中的data并没有特别的格式, 也没有特别的意义. 当然message还是有一些元数据的, 代表message的key. Key同样也是字节序列, 同message一样, 对于kafka来说也没有特别的含义. Key被用于以一种可控的方式将message写入到分区(partitions)中. 最简单的模式就是将分区视为一个hash环, 保证相同的key会被写到相同的分区. Key的使用将在第三章中完整的讨论
考虑到效率, 消息一般以batch(batch)的方式写入到kafka中. 一个batch就是生产到同一个topic和partition的一系列消息的集合.
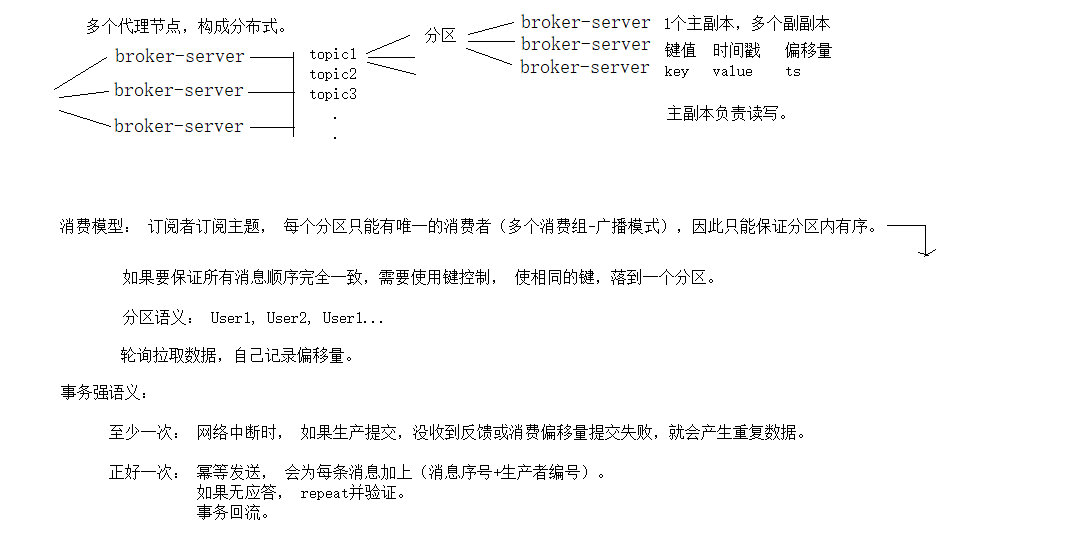
Topic被划分为多个partitions.回到”commit log”的描述, 一个partition就是一个单独的log文件. 消息以append-only的方式写入到log文件中, 并且以从开始到结束的方式顺序读. 一般topic通常会有多个分区,消费在单个分区保证有序, 但是在多个分区间是不能保证的.
Kafka在每个消息产生时添加offset。给定分区中的每个消息都有唯一的偏移量。通过在Zookeeper或Kafka本身中存储每个分区的最后消费的消息的偏移,消费者可以停止并重新启动,而不会丢失它的最后消费位置。
consumer作为consumer group的一部分运行. 一个或多个consumer共同运行以消费一个topic. consumer group确保每个分区只会被这个consumer group中的一个consumer消费. 在图1-6中, 在这个consumer group中有3个普通consumer, 其中的两个consumer各自消费一个partition, 另外一个consumer独自消费两个partition. 我们一般将consumer和partition的映射称为consumer对partition的ownership(所有权).
这样, 消费者能够水平扩展以消费一个拥有大量消息的topic. 另外, 如果一个消费者挂掉的话, consumer group中其他消费者会自动平衡partition的消费分配以取代挂掉了的consumer. 在第4章中会对consumer和consumer group进行进一步的探讨.
Kafka 2
Kakfa broker被设计成作为kafka集群的一部分. 在borker集群中, 有一个会作为整个集群的controller(从当前存活broker中选取). 这个controller负责管理性的操作, 包括分配partition给broker和监控broker故障. 在集群中, 一个partition被一个broker所有, 这个broker被称为该分区的leader. 一个分区会被分配给多个broker, 这就是分区的副本集(Figure 1-7). 这对分区消息提供了冗余, 如果出现broker故障, 其他的broker就能接管leadership.
但是对一个分区的所有消费和生产操作, 都必须与leader连接. 集群操作, 包括分区复制
消费者消费数据流程:
consumer订阅消息时,会连接上任一个可用的broker,并获取topic中leader partition的元数据metadata信息,这样consumer就可以直接与leader partition通信,获取消息。
在kafka中的每一个partition中 ,kafka会为每一条消息记录分配一个数值型的offset。offset值唯一标识了partition中的一条消息,也表示消费者在分区的消费位置。也就是说,一个消费者Consumer的消费position为5,说明已经消费了offset为0,1,2,3,4的消息,下一个要消费的消息的offset为5。
一个消费者Comsumer只能属于一个consumer group ,通过subscribe API 可以动态设置topic列表。kafka会将topic中的每一条消息发送给consumer group中的一条进程。为了使topic partition分区与consumer group中的进程达到平衡,每一个partition只会有consumer group中的一个消费者来消费。
Kafka3
生产者数据流程:
从创建一个ProducerRecord开始,ProducerRecord包含消息要发送到哪个Topic,消息的值,也可以声明一个key和partition。一旦将ProducerRecord发送,producer要做的就是序列化key和value对象为二进制数组,这样才可以通过网络发送。
接着,producer将这个消息加入到一个消息批次中,这个消息批次中的消息会发送到相同的topic和partition。此时会开辟一个独立的线程负责发送这批消息到合适的kafka broker。
当broker收到消息,会发回一个响应信息。如果这个消息成功写入kafka,broker会响应一个RecordMetadata对象(包括topic、partition、以及消息在partition中的offset)。如果broker没有将消息写入kafka,将会响应一个错误。当producer收到这个错误,可以尝试重发指定次数的消息,直到放弃