一、BeautifulSoup四大对象
1.Tag
(1)对应的就是Html中的标签;
(2)可以通过soup,tag_name
(3)tag里面有两种重要的属性
name:用于打印标签的名字
attrs:用于打印属性(返回一个字典)
contents:打印内容(返回一个列表)
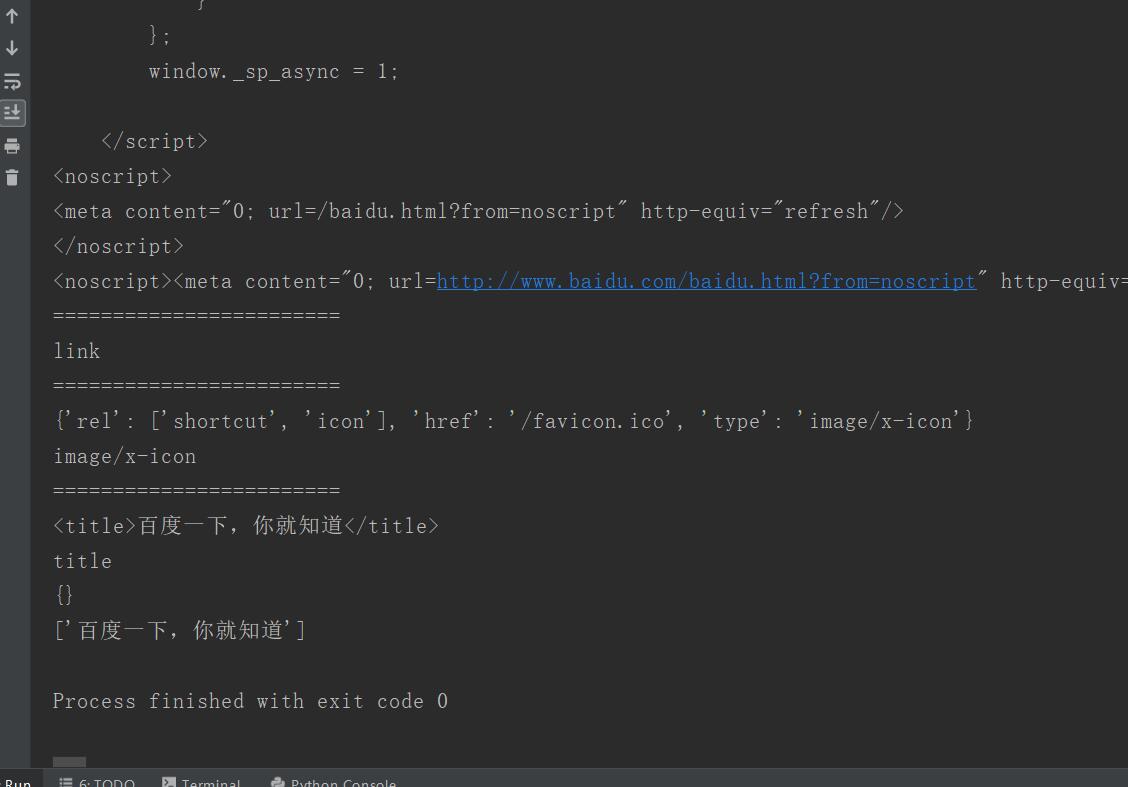
from bs4 import BeautifulSoup from urllib import request url = "http://www.baidu.com" rsp = request.urlopen(url) content = rsp.read() soup = BeautifulSoup(content) #bs自动转码 content = soup.prettify() print(content) print("==" *12) print(soup.head) print("=="*12) print(soup.link.name) print("=="*12) print(soup.link.attrs) print(soup.link.attrs["type"]) print("=="*12) print(soup.title) print(soup.title.name)#打印标签 print(soup.title.attrs) print(soup.title.contents)#打印内容,返回一个列表
2.NavigableString
对应内容值
3.BeautileSoup
(1)表示的是一个文档的内容,大部分可以把它当作是tag对象
(2)一般可以使用soup来表示
4.Comment
(1)特殊类型的NavagableString对象
(2)对其输出,则内容不包括注释符号
二、遍历文档对象
1.contents:tag的子节点以列表的方式给出
2.children:子节点以迭代器的方式返回
3.decendants:所有的孙子节点
4.string
三、搜索文档对象
find_all(name,attrs,recursive,text,**kwargs)
name:按照哪个字符串搜索,可以传入的内容:
(1)字符串;(2)正则表达式;(3)列表
kewwortd参数,可以用来表示属性
text:对应tag的文本值
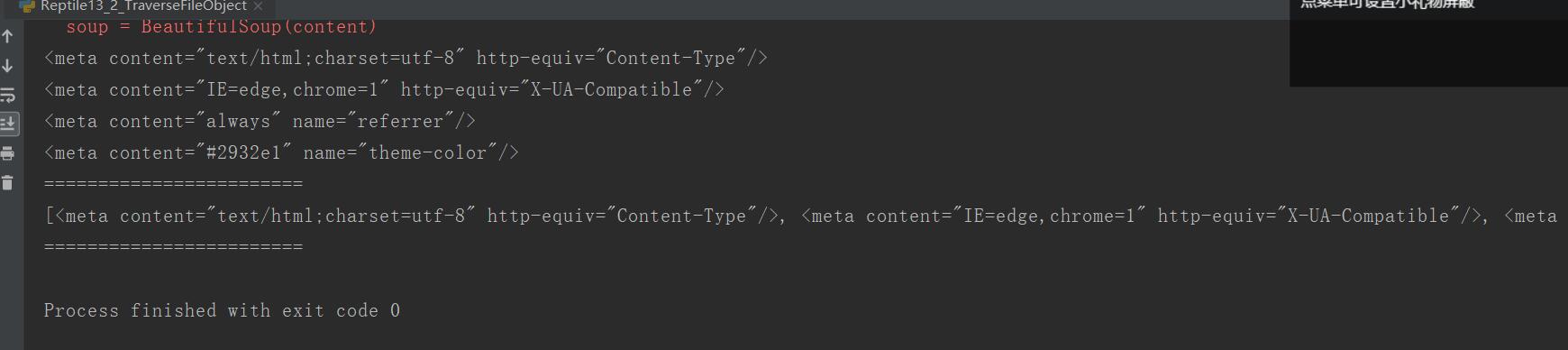
from bs4 import BeautifulSoup from urllib import request import re url = "http://www.baidu.com" rsp = request.urlopen(url) content = rsp.read() soup = BeautifulSoup(content) #bs自动转码 content = soup.prettify() for node in soup.head.contents: if node.name == "meta": print(node) print("=="*12) tags = soup.find_all(name=re.compile("meta"))#可以使用正则,返回了一个列表,找的是含有meta属性的所有标签 print(tags) print("=="*12)
四、CSS选择器
1.使用soup.select,返回一个列表
2.通过标签名称:soup.select("title")
3.通过类名:soup.select(".content")
4.通过id名:soup.select("#name_id")
5.组合查找:soup.select("div #input_content")
6.属性查找:soup.select("img[class="photo"])
7.获取tag内容:tag.get_text
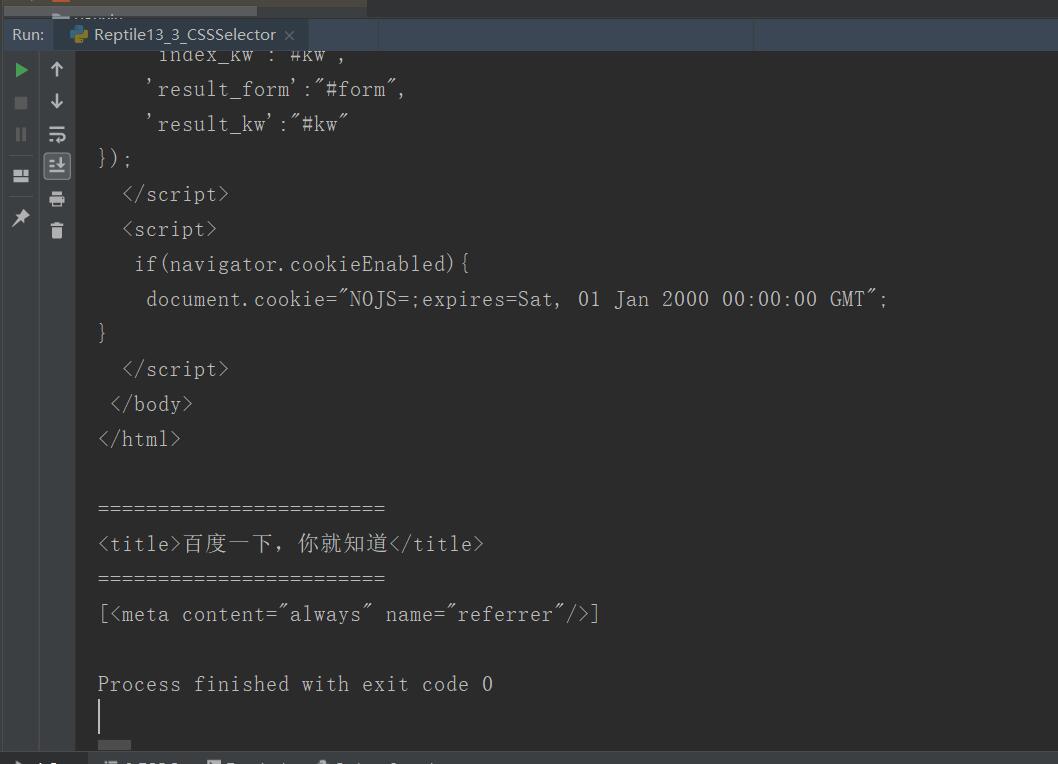
from bs4 import BeautifulSoup from urllib import request import re url = "http://www.baidu.com" rsp = request.urlopen(url) content = rsp.read() soup = BeautifulSoup(content) print(soup.prettify()) print("=="*12) titles = soup.select("title") print(titles[0]) print("=="*12) metas = soup.select("meta[content='always']") print(metas)
五、源码
Reptile13_1_BeautifulSoupFourComponent.py
Reptile13_2_TraverseFileObject.py
Reptile13_3_CSSSelector.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile13_1_BeautifulSoupFourComponent.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile13_2_TraverseFileObject.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile13_3_CSSSelector.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料
