redis这个内存数据库,它的高性能、稳定性都是不用怀疑的,但我们塞进redis的数据过多,内存过大,那如果出问题,那它可能会带给我们的就是灾难性。
- 作者:程超来源:网络|2016-05-23 09:54
这几年的线上业务表明,redis这个内存数据库,它的高性能、稳定性都是不用怀疑的,但我们塞进redis的数据过多,内存过大,那如果出问题,那它可能会带给我们的就是灾难性(我想很多公司都遇到过) 这里列举一下,我们遇到的一些问题:
1 主库宕机
先来看一下主库宕机容灾过程:如下图
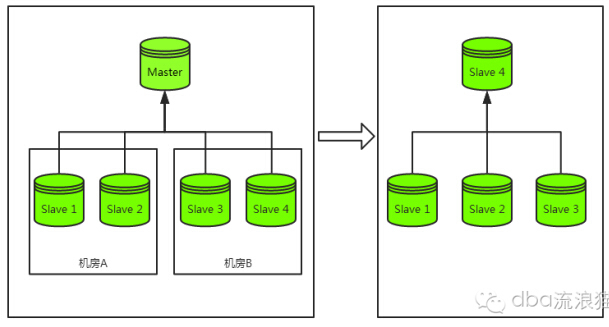
在主库宕机的时候,我们最常见的容灾策略为“切主”。具体为从该集群剩余从库中选出一个从库并将其升级为主库,该从库升级为主库后再将剩余从库挂载至其下成为其从库,最终恢复整个主从集群结构。
以上是一个完整的容灾过程,而代价最大的过程为从库的重新挂载,而非主库的切换。
这是因为redis无法像MySQL、mongodb那样基于同步的点位在主库发生变化后从新的主库继续同步数据。 在redis集群中一旦从库换主,redis的做法是将更换主库的从库清空然后从新主库完整同步一份数据再进行续传。
整个从库重做流程是这样的:
- 主库bgsave自身数据到磁盘
- 主库发送rdb文件到从库
- 从库开始加载
- 加载完毕开始续传,同时开始提供服务
很明显,在这个过程中redis的内存体积越大以上每一个步骤的时间都会被拉长,实际测试的数据如下(我们自认我们的机器性能比较好):

可以看到,当数据达到20G的时候,一个从库的恢复时间已经被拉长到了将近20分钟,如果有10个从库那么如果依次恢复则共需200分钟,而如果此时该从库承担着大量的读取请求你能够忍受这么长的恢复时间吗?
看到这里你肯定会问:为什么不能同时重做所有从库?这是因为所有从库如果同时向主库请求rdb文件那么主库的网卡则立即跑满从而进入一个无法正常提供服务的状态,此时主库又死了,简直是雪上加霜。
当然,我们可以批量恢复从库,例如两两一组,那么全部从库的恢复时间也仅仅从200分钟降低到了100分钟,这不是五十步笑百步吗?
另一个重要问题在于第四点中的标红位置,续传可以理解为一个简化的mongodb的oplog,它是一个体积固定的内存空间,我们称之为“同步缓冲区”。
redis主库的写入操作都会在该区域存放一份然后发送给从库,而如果在上文中1,2,3步耗时太久那么很可能这个同步缓冲区就被重写,此时从库无法找到对应的续传位置它会怎么办?答案是重做1,2,3步!
但因为我们无法解决1,2,3步的耗时因此该从库会永远的进入恶性循环:不停的向主库请求完整数据,结果对主库的网卡造成严重影响。
2 扩容问题
很多时候会出现流量的突发性增长,通常在找到原因之前我们的应急做法就是扩容了。
而根据场景一中的表格,一个20G的redis扩容一个从库需要将近20分钟,在这个紧急的时刻20分钟业务能够容忍吗?可能还没扩好就死翘翘了。
3 网络不好导致从库重做最终引发雪崩
该场景的最大问题是主库与从库的同步中断,而此时很可能从库仍然在接受写入请求,那么一旦中断时间过长同步缓冲区就很可能被复写。此时从库上一次的同步位置已丢失,在网络恢复后虽然主库没有发生变化但由于从库的同步位置丢失了从库必须进行重做,也就是问题一中的1,2,3,4步。如果此时主库内存体积过大那么从库重做速度就会很慢,而发送到从库的读请求就会受到严重影响,同时由于传输的rdb文件的体积过大,主库的网卡在相当长的一段时间内都会受到严重影响。
4 内存越大,触发持久化的操作阻塞主线程的时间越长
Redis是单线程的内存数据库,在redis需要执行耗时的操作时,会fork一个新进程来做,比如bgsave,bgrewriteaof。 Fork新进程时,虽然可共享的数据内容不需要复制,但会复制之前进程空间的内存页表,这个复制是主线程来做的,会阻塞所有的读写操作,并且随着内存使用量越大耗时越长。例如:内存20G的redis,bgsave复制内存页表耗时约为750ms,redis主线程也会因为它阻塞750ms。
解决办法
解决办法当然就是极力减少内存的使用了,一般情况下,我们都是这么做的:
1 设置过期时间
对具有时效性的key设置过期时间,通过redis自身的过期key清理策略来降低过期key对于内存的占用,同时也能够减少业务的麻烦,不需要定期清理了
2 不存放垃圾到redis中
这简直就是废话,但是,有跟我们同病相怜的人么?
3 及时清理无用数据
例如一个redis承载了3个业务的数据,一段时间后有2个业务下线了,那你就把这两个业务的相关数据清理了呗
4 尽量对数据进行压缩
例如一些长文本形式的数据,压缩能够大幅度降低内存占用
5 关注内存增长并定位大容量key
不管是DBA还是开发人员,你用redis,你就必须关注内存,否则,你其实就是不称职的,这里可以分析redis实例中哪些key比较大从而帮助业务快速定位异常key(非预期增长的key,往往是问题之源)
6 pika
如果实在不想搞的那么累,那就把业务迁移到新开源的pika上面,这样就不用太关注内存了,redis内存太大引发的问题,那也都不是问题了。
最后祈祷线上5000个redis实例都不要异常~~~