 It took Ruby some time to go from an infant research project by Matz to a language we've all come to know so well. Now, another Japanese developer (Mikio Hirabayashi) has all the potential to repeat this cycle with his new database project: Tokyo Cabinet. Developed and sponsored byMixi Inc. (Japanese Facebook), it is an incredibly fast, and feature rich database library. In fact, given the maturity of the project, it is surprising how little information is available on it outside of Japan. Let's take a quick tour!
It took Ruby some time to go from an infant research project by Matz to a language we've all come to know so well. Now, another Japanese developer (Mikio Hirabayashi) has all the potential to repeat this cycle with his new database project: Tokyo Cabinet. Developed and sponsored byMixi Inc. (Japanese Facebook), it is an incredibly fast, and feature rich database library. In fact, given the maturity of the project, it is surprising how little information is available on it outside of Japan. Let's take a quick tour!
Speed and efficiency are two consistent themes for Tokyo Cabinet. Benchmarks show that it only takes 0.7 seconds to store 1 million records in the regular hash table and 1.6 seconds for the B-Tree engine. To achieve this, the overhead per record is kept at as low as possible, ranging between 5 and 20 bytes: 5 bytes for B-Tree, 16-20 bytes for the Hash-table engine. And if small overhead is not enough, Tokyo Cabinet also has native support for Lempel-Ziv or BWT compression algorithms, which can reduce your database to ~25% of it's size (typical text compression rate). Oh, and did I mention that it is thread safe (uses pthreads) and offers row-level locking?
For a full feature list, take a look at the overview presentation, as well as the project specifications. However, while the technical details are nothing short of impressive, it is the collection of underling database engines that really makes the project stand out!
 Hash database engine is a direct competitor to BerkeleyDB, and other key-value stores: one key, one value, no duplicates, and crazy fast. However, being faster is one thing, and innovating on the idea is another, and this is where other Tokyo Cabinet engines break away from the pack.
Hash database engine is a direct competitor to BerkeleyDB, and other key-value stores: one key, one value, no duplicates, and crazy fast. However, being faster is one thing, and innovating on the idea is another, and this is where other Tokyo Cabinet engines break away from the pack.
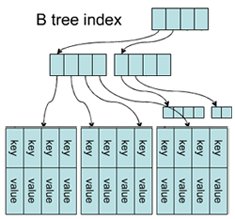
Functionally, the B-Tree database engine is equivalent to the Hash database. However, because of its underlying structure, the keys can be ordered via a user-specified function, which in turn allows us to do prefix and range matching on a key, as well as, traverse the entries in order. (Think Ruby 1.9 ordered hash). Let's look at some examples:
require "rubygems" require "tokyocabinet" include TokyoCabinet bdb = BDB::new # B-Tree database; keys may have multiple values bdb.open("casket.bdb", BDB::OWRITER | BDB::OCREAT) # store records in the database, allowing duplicates bdb.putdup("key1", "value1") bdb.putdup("key1", "value2") bdb.put("key2", "value3") bdb.put("key3", "value4") # retrieve all values p bdb.getlist("key1") # => ["value1", "value2"] # range query, find all matching keys p bdb.range("key1", true, "key3", true) # => ["key1", "key2", "key3"]
Next up, we have the 'fixed length' engine, which is best understood as a simple array. There is absolutely no hashing and access is done via natural number keys, which also means no key overhead. If you're looking for speed, you can't get any faster.
Saving best for last, we have the Table engine, which mimics a relational database, except that it requires no predefined schema (in this, it is a close cousin to CouchDB, which allows arbitrary properties on any object). Each record still has a primary key, but we are allowed to declare arbitrary indexes on our columns, and even perform queries on them:
require "rubygems" require "rufus/tokyo/cabinet/table" t = Rufus::Tokyo::Table.new('table.tdb', :create, :write) # populate table with arbitrary data (no schema!) t['pk0'] = { 'name' => 'alfred', 'age' => '22', 'sex' => 'male' } t['pk1'] = { 'name' => 'bob', 'age' => '18' } t['pk2'] = { 'name' => 'charly', 'age' => '45', 'nickname' => 'charlie' } t['pk3'] = { 'name' => 'doug', 'age' => '77' } t['pk4'] = { 'name' => 'ephrem', 'age' => '32' } # query table for age >= 32 p t.query { |q| q.add_condition 'age', :numge, '32' q.order_by 'age' } # => [ {"name"=>"ephrem", :pk=>"pk4", "age"=>"32"}, # {"name"=>"charly", :pk=>"pk2", "nickname"=>"charlie", "age"=>"45"}, # {"name"=>"doug", :pk=>"pk3", "age"=>"77"} ] t.close
While Tokyo Cabinet is best thought of as an API to the native database routines, you'll be happy to know that you can, in fact, run Tokyo Cabinet in stand alone mode with the help of Tokyo Tyrant - a high concurrency network interface to the underlying database. Backup, replication, and failover are all part of the package.
Ah, but what about the supporting access libraries, right? Well, there is an alpha MySQL Engine by Brian Krow, and it also understands the memcached protocol. Specify the Tokyo Tyrant server IP as your memcached server, and you're up and ready to go. And if that's not enough, just to seal the deal, here is my favorite: it is also fully RESTful!
require "rubygems" require "rest_client" # Interacting with TokyoTyrant via HTTP! db = RestClient::Resource.new("http://localhost:1978") db["key"].put "value 1" # insert via HTTP db["key"].put "value 2" # update via HTTP puts db["key"].get # get via HTTP # => "value 2" db["key"].delete # delete via HTTP puts db["key"].get rescue RestClient::ResourceNotFound
 Excluding the memcached and HTTP access methods, there are currently three Ruby alternatives methods for interacting with Tokyo Cabinet and Tokyo Tyrant. Hirabayashi-san, the author of the project, is actively maintaining the Tokyo Cabinet(rdoc) and Tokyo Tyrant (rdoc) libraries. John Mettraux is working on a FFI-backed, and arguably much more Ruby friendly version: rufus-tokyo, and Makoto Inoue has a prototype DataMapper adapter.
Excluding the memcached and HTTP access methods, there are currently three Ruby alternatives methods for interacting with Tokyo Cabinet and Tokyo Tyrant. Hirabayashi-san, the author of the project, is actively maintaining the Tokyo Cabinet(rdoc) and Tokyo Tyrant (rdoc) libraries. John Mettraux is working on a FFI-backed, and arguably much more Ruby friendly version: rufus-tokyo, and Makoto Inoue has a prototype DataMapper adapter.
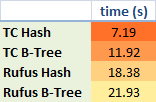
Not surprisingly, the FFI bindings in rufus-tokyo can't keep up with the native interface (benchmarks for inserting, reading, and scanning 1 million records), but relatively speaking, the gem is still very fast and offers the added benefits of portability across all Ruby implementations and a much friendlier interface.
Still not convinced? Take a look at the source code, it's a pleasure to work with.