取得第一个做样板,然后与第二个字符串比较,看它们是否有共同前缀,没有那么将前缀的缩短一点,从后面砍掉一个字符再比较,有了前缀就再与第三,第四个比较
function longestCommonPrefix(strs) {
if (strs.length == 0) return "";
var prefix = strs[0];
for (var i = 1; i < strs.length; i++) {
while (strs[i].indexOf(prefix) != 0) {
prefix = prefix.substring(0, prefix.length - 1);
if (!prefix) return "";
}
}
return prefix;
}
垂直扫描法,也是拿第一个字符串做样板,然后取其第一个字符,与剩下的所有字符串的第一个字符来比较,没问题就开始 比较第二个字符
function longestCommonPrefix(strs) {
if (!Object(strs).length) {
return "";
}
var first = str[0]
for (var i = 0; i < first.length; i++) {
var c = first[i];
for (var j = 1; j < strs.length; j++) {
if (i == strs[j].length || strs[j][i] != c)
return first.substring(0, i);
}
}
return first
}
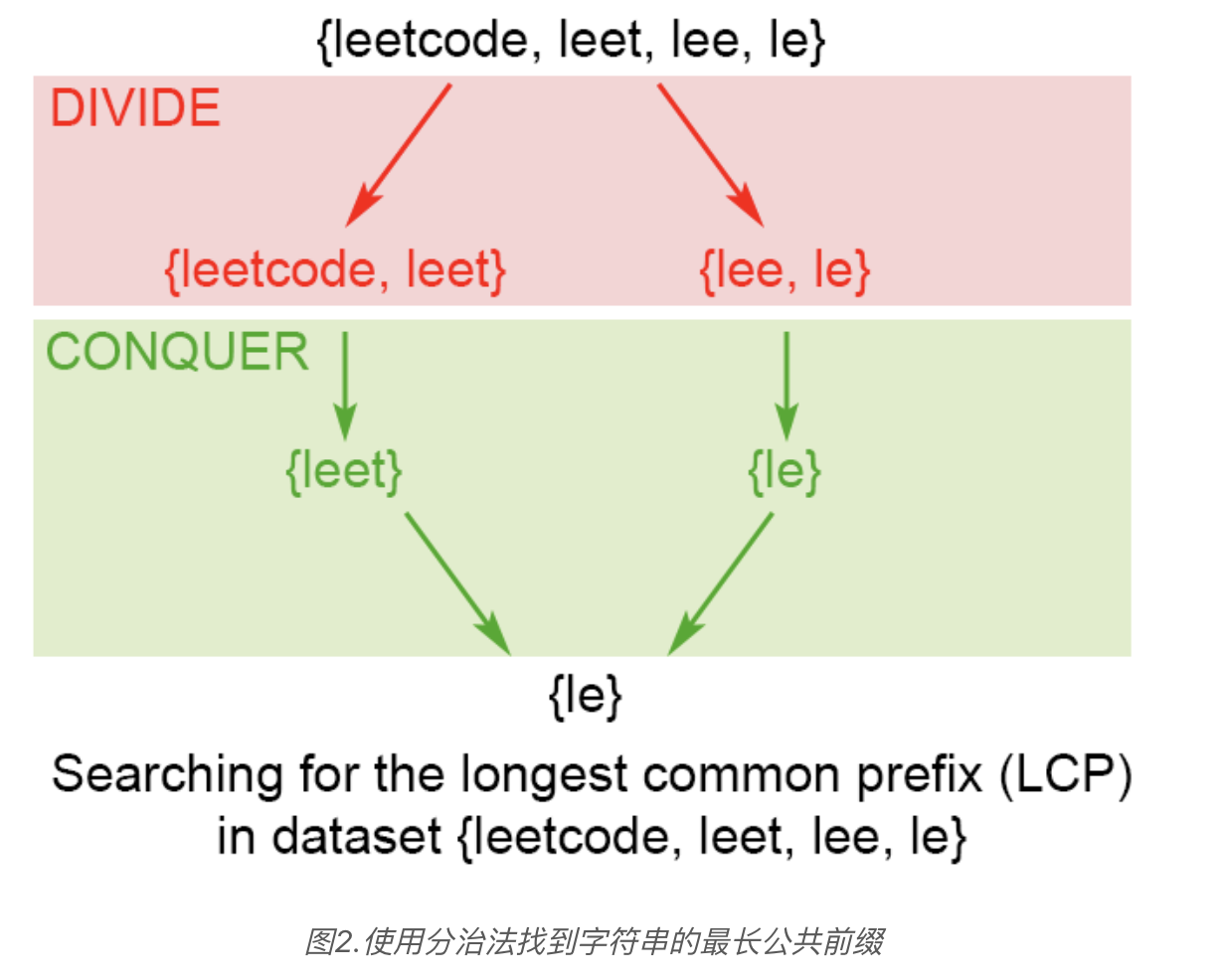
分治法
function longestCommonPrefix(strs) {
if (strs == null || strs.length == 0) return "";
return helper(strs, 0, strs.length - 1);
}
function helper(strs, l, r) {
if (l == r) {
return strs[l];
} else {
var mid = (l + r) >> 1
var lcpLeft = helper(strs, l, mid);
var lcpRight = helper(strs, mid + 1, r);
return commonPrefix(lcpLeft, lcpRight);
}
}
function commonPrefix(left, right) {
var min = Math.min(left.length, right.length);
for (var i = 0; i < min; i++) {
if (left.charAt(i) != right.charAt(i))
return left.substring(0, i);
}
return left.substring(0, min);
}
先求出最短的字符长度,然后通过二分法求与其他的共同前缀
function longestCommonPrefix(strs) {
if (strs == null || strs.length == 0)
return "";
var minLen = Number.MAX_VALUE;//找到最短的字符串长度
for (let str of strs) {
minLen = Math.min(minLen, str.length);
}
var low = 1;
var high = minLen;
while (low <= high) {
var middle = (low + high) >> 1;
if (isCommonPrefix(strs, middle)) {
low = middle + 1;
} else {
high = middle - 1;
}
}
return strs[0].substring(0, (low + high) >> 1);
}
function isCommonPrefix(strs, len) {
var str1 = strs[0].substring(0, len);
for (var i = 1; i < strs.length; i++) {
if (!strs[i].startsWith(str1))
return false;
}
return true;
}
使用前缀树
function Node(value) {
this.value = value
this.isEnd = false
this.children = {}
this.passCount = 0;
this.endCount = 0
}
class Trie {
constructor() {
this.root = new Node(null)
}
insert(word) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word[i];
var node = cur.children[c];
if (!node) {
node = cur.children[c] = new Node(c)
}
cur = node;
cur.passCount++ ////有N个字符串经过它
}
cur.endCount++; //这个字符串重复添加的次数
}
longestCommonPrefix(n) {
var cur = this.root, lcp = '', wordsCount = 0
while (true) {
var count = 0
var kids = cur.children;
for (var i in kids) {
if (kids.hasOwnProperty(i)) {
count++
}
}
//如果这父节点只有一个孩子,说明没有分叉
if (count == 1) {
cur = kids[i];
//根节点的独生子的passCount,就是插入的字符串的总数量, 只计算一次
if (!wordsCount) {
wordsCount = cur.passCount
}
if (cur.passCount == wordsCount) {//由于是共同前缀,因此保证所有字符串都经过这节点
lcp += cur.value
continue //继续搜索下一个节点
}
}
return lcp;
}
return lcp
}
}
function longestCommonPrefix(words) {
var trie = new Trie;
for (let word of words) {
if (word == '') {
return ''
}
trie.insert(word);
}
return trie.longestCommonPrefix()
}
console.log(longestCommonPrefix(["flower", "flow", "flight"]))
console.log(longestCommonPrefix(["aa", "a"]))
console.log(longestCommonPrefix(["aaa", "aa", 'aac']))