基本概念
按照惯例,研究一个新东西要由浅入深,先进行一个简单介绍,这一块就直接引用菜鸟教程的
Redis概述
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis与其他key-value存储有什么不同?
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
对于上面的一些特性和概念在后面的文章会一个个去分析的。
安装
还是一贯的风格---懒,直接去hub.docker.com找镜像文件来安装,有官方提供的镜像
在Ubuntu中运行命令
docker run --name some-redis -d redis
很容易就得到一个Redis实例了。上面简介中有提到Redis能读的速度是110000次/s,写的速度是81000次/s ,Redis安装好了我们就先测试一下我们的redis的性能。
首先进入容器
docker exec -it {容器Id} /bin/bash
执行Redis的性能测试命令,我设定检测set,lpush,get三种命令,将请求数设定为1W,10W,100W,结果如图
redis-benchmark -t set,lpush,get -n 10000 -q
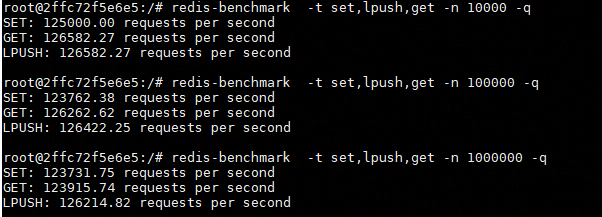
可以看到都是在12W+,相当不错了
可视化管理工具
还是懒,肯定要用可视化的管理工具才行,推荐两款自己在用的工具 Redis Desktop Manager 和 AnotherRedisDesktopManager,都是不错的工具。
为什么这么快
-
完全基于内存,Redis绝大部分请求是存粹的内存操作,非常快速。跟硬盘存储相比,不会受到硬盘I/O的速度限制,而另一方面内存的存储是基于晶体管的电流有无状态来标示信息的,所以当断电之后信息就不会保存下来,也就是无法持久化。
-
使用多路I/O复用模型(一个线程就可以管理很多socket连接)来保证在多连接的时候,系统的吞吐量。具体的可以参考这一篇文章
-
单线程实现,不需要创建/销毁线程,避免上下文切换,无并发资源竞争的问题。
关于这一点可能会有人有疑惑了,多线程的定义就是能利用多核CPU来提高响应速度,为什么抛弃多线程而使用单线程还是能提高速度呢? 这一点是一个权衡问题,我们应该考虑的是 “为什么Redis要用单线程” 而不是“Redis不用多线程”。一方面,Redis的性能瓶颈是在内存和网络而不是在CPU,多核CPU对于Redis的性能提升没有多大的用处,我们用多线程是因为一些耗时操作阻塞了我们的线程所以我们需要创建新的线程来执行耗时操作从而让主线程不阻塞,而Redis大部分都是内存操作不存在阻塞线程的情况,另一方面多线程的创建/销毁/切换,并发的问题还会有多余的资源占用,所以Redis采用了单线程。当然Redis也有一些耗时的操作比如集合的并集交集之类的,如果这些请求影响到了响应速度可以考虑启动多个实例组成集群,让多个实例来一起处理请求,当然这也带来数据一致性的问题,后续文章会去研究。
我们可以用Redis干什么
- 分布式缓存: 这是Redis的初衷,能很大的提升服务器的响应速度和性能。
- 计数: Redis中原子性的自增/自减操作(increment,decrement),可以统计类似用户点赞,访问数等高频读写操作,会对数据库产生相当大压力。
- 排行榜:Sorted Sets的每个元素都会关联一个分数,Redis会通过分数来对集合中的成员进行排序,元素的分数可以随时更新,天生就可以用来做排行榜。
- 消息队列:Redis自带发布/订阅模式可以实现消息队列。
- 硬盘数据库:Redis有持久化功能,可以当作一个硬盘数据库使用。