https://www.zhihu.com/question/39593108
链接:https://www.zhihu.com/question/39593108/answer/250480994
1.
一般的Web开发框架(比如Java的Struts2、SpringMVC,dotNet的WebForm和MVC,NodeJS的Express、Koa),在基于Web Server(比如Tomcat、IIS、Apache、Nginx)处理HTTP Request的时候,都倾向于采用类似流水线的请求处理机制(新式框架多叫Web处理中间件)。
HTTP Request从被接收开始,作为一个整体一层层穿过不同的Middleware进行处理,最终输出HTTP Response就算处理完一个请求了。这样的处理方式更高效,可配置、可扩展性也更强。
但是这样就要求在流水线的最开始,就要完整地接收整个HTTP Request,并封装为一个可解析的对象,依次往下级传递,这实际上就是要把HTTP Request放在内存里面。
一般的页面请求或Ajax请求还好,因为都是文本,再大也没多大。许多Web Server的默认设置都是可以为一个请求最多分配20M的服务器内存,一般情况下是足够的,想想看一个20MB大小的txt文件得有多长?
2.
但是如果HTTP Request中不是正常文本,而是带着上传的文件,这个时候就尴尬了。
比如这种情况下我要上传一个最大100M的文件。
一种简单的方式是还用流水线处理的方式。需要把Web Server的配置从20M提高到100M,就能上传成功了。但是问题是这时候网站只要有一个人在上传100M的文件,就需要占用服务器100M的内存,如果有10个人同时上传1个G的内存可就没了。
如果你的网站需要上传最大1G的文件呢?你还舍得你的内存吗?而且如果把这个设置提高,网站的安全性可就不好说了,随便制造几个文件上传的HTTP Request就分分钟可以把你服务器搞到内存100%,你还怎么愉快地玩耍?
题主问题中提到的FileNet以Web Service的方式上传一般不能超过100MB,估计就是属于以上情况,默认配置是最大占用100M内存,尽管理论上还可以往上配更大的,但是处于安全角度,人家直接告诉你不能再大了。
3.
另外一种方式,就是放弃流水线的处理方式,为文件上传单独设置一条VIP通道,特殊处理。获取到HTTP Request Stream,以数据流的方式去处理,这样就不需要等到整个请求都接收完成,而是接收一点就处理一点。
好处是终于不那么费内存了,也不用改Web Server内存配置了,坏处是实现起来会麻烦些,一般的Web开发框架会留给你单独开口子的方式,由你自己在底层自行处理HTTP Request的原始内容,包括通过流的方式获取请求内容。
题主问题中提到的FileNet使用EJB(IIOP)的方式,本质上应该就是属于这种情况,所以可以支持更大的文件。
至于为什么采用这种方式依然还有2G大小的限制呢?真的是由于HTTP的限制吗?这就引出了下一个问题。
4.
基础知识:
我们在程序里面使用的整形数字,一般是Int类型,这个类型一般指代Int32,也就是用4个字节来表示一个整数。
而用4个字节来记录一个有符号的整数(可正可负),其最大值用16进制表示是 ,折合成10进制是
。
而
所以,Int32的最大值 =
结论是,如果用4个字节的有符号整型来表示文件的长度,最多能表示大约2GB,再长就可能使长度变成负数了……
所以你知道2GB这个Magic Number是怎么来的了吧……
事实上,有相当多的系统在建设的时候都没有考虑大文件的问题,都是使用Int32来表示文件长度。而只要在文件发送、接收、处理、分析、存储的任意一个环节没有处理好这个问题,甚至只是一个外部依赖库的问题,都会导致整个软件系统不支持2GB以上的文件。
另外,如果使用4个字节来表示一个无符号的整数(只有正数),那么其最大值加倍,也就是最多能表示4GB文件的长度。
所以,这里分享一个小Tip,如果想验证一个系统是否真的支持大文件,先拿一个2.5GB文件试试第一道坎,如果通过的话,再拿一个4.5G的文件试试第二道坎。
5.
那么我们再来看看HTTP协议对请求大小有限制吗?
目前广泛使用HTTP协议1.1版本的标准定义在RFC2616中有完整表述。
14.13 Content-Length
The Content-Length entity-header field indicates the size of the
entity-body, in decimal number of OCTETs, sent to the recipient or,
in the case of the HEAD method, the size of the entity-body that
would have been sent had the request been a GET.
Content-Length = "Content-Length" ":" 1DIGIT
An example is
Content-Length: 3495
其中表示消息体长度的字段 Content-Length 的类型规定为Decimal,同时也并没有对这一字段的长度进行逻辑上的限制。Decimal类型是用16个字节表示有符号整数,它能表示的最大值我们就不用算了,大到没朋友。
所以先贤们在制定HTTP协议标准的时候已经充分考虑这个问题了,把2GB大小限制的锅推给HTTP协议,W3C组织表示这锅我们不背。
6.
那么IBM为什么不能把FileNet的这个问题改一改,直接让FileNet支持2GB以上的文件呢?
而是如题主所说,推荐用户体外循环,集成FTP、QuickFile或者Aspera等第三方服务来解决2GB以上文件的上传问题呢?这就又引出了另外一个问题。
很重要的一个因素是,如果支持了2GB以上的大文件上传,还会引来更多的新问题。
想象一下,如果一个用户使用FileNet正在上传一个3GB的文件,好不容易到传到99%的时候,一不小心手欠把网页关了或者网络断了,回过头来发现没有断点续传功能,还得从头开始上传,用户会不会精神崩溃,会不会组织起来抗议?
所以,一旦支持了2G以上的大文件,是不是就应该得有断点续传?上传这么大的文件,如果传到最后内容出错怎么办?是不是至少还得有文件校验啊?校验如果不对的话要不要自动重传啊?这么大的文件要不要考虑分块上传?要不要考虑并发控制?如果传的文件多了要不要考虑排队?……想想都没头,唉……
如果这样,实际上就是逼着IBM把FileNet这么一个内容管理系统,活生生地做成一个传输管理系统。
所以,即便如IBM这般拥有强大技术实力的厂家,也会理智地划清界限,如果有大文件需求,宁可集成第三方服务,也不再造一遍锤子。更何况推荐的QuickFile和Aspera都是IBM自家产品,何乐而不为呢?
7.
至于题主在问题中提到的Ftrans的CUTP超高速传输协议,以及Aspera对于TCP协议瓶颈的描述,这些是传输协议以及协议加速方面的问题,其实与本题“大文件传输技术瓶颈”的关联性不大。
我只想说:实际上,无论是Ftrans还是Aspera,都是先解决了大文件传输场景下的众多技术问题,然后再叠加上更高效的传输协议来提升传输效率;而不是试图只是通过一种特殊的传输协议来解决大文件传输问题。
利益相关:Ftrans.cn CTO
————————华丽的广告分割线——————————
Ftrans 飞驰传输 一直致力于解决企业级场景下的文件大数据高速传输的问题。
仅从内容的角度来说,文件大数据至少包括大文件和海量文件。我们一直专注于解决这些场景所带来的新挑战,甚至包括TB级巨型文件以及百万级海量文件传输的极端场景。
我们非常欢迎与对此方面感兴趣的同学进行技术交流。
另外,与本题中提到的场景类似,企业中很现有的业务系统(如ERP、内容管理系统、媒资管理系统等),在涉及到大文件传输的场景时,通过自身升级改造来支持的方式在很多情况下是得不偿失的。Ftrans也支持作为第三方的传输服务,快速集成到企业现有系统当中,使得企业可以迅速具备完善的文件大数据传输能力。
分片上传流程
分片上传的基本流程如下:
- 将要上传的文件按照一定的大小分片。
- 初始化一个分片上传任务(InitiateMultipartUpload)。
- 逐个或并行上传分片(UploadPart)。
- 完成上传(CompleteMultipartUpload)。
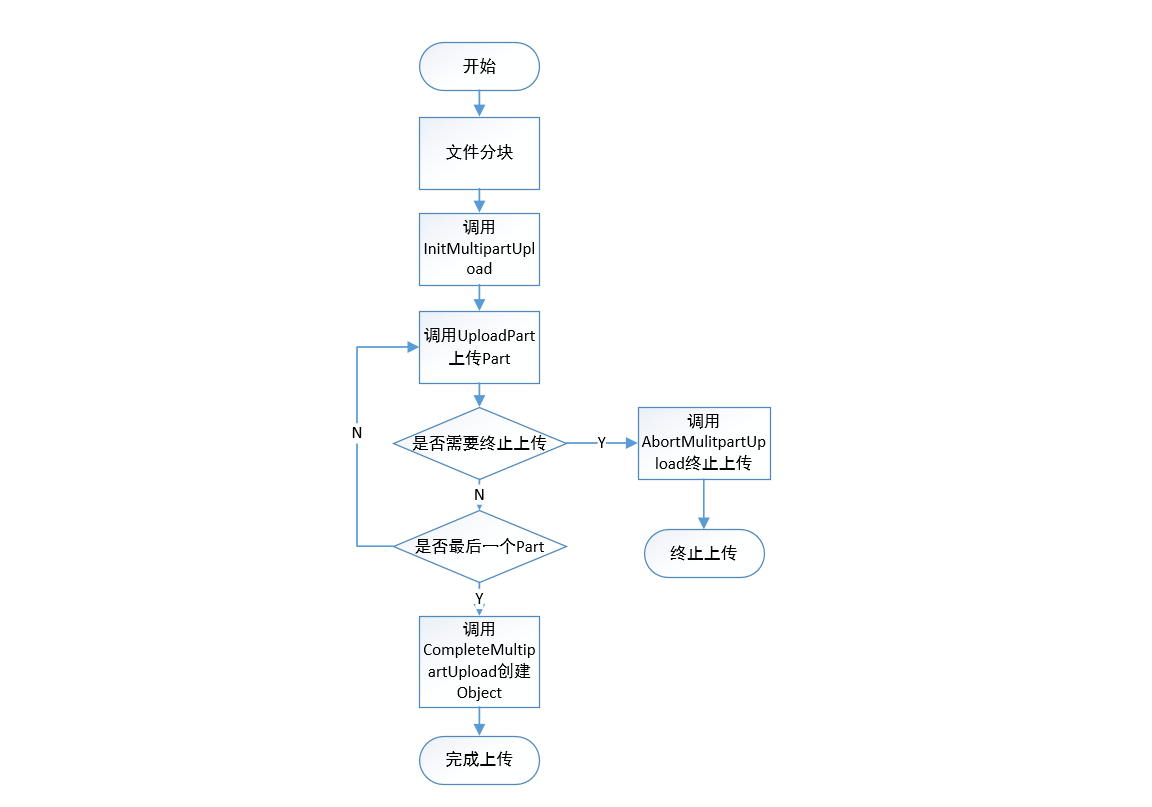
本文介绍如何使用分片上传。
分片上传(Multipart Upload)分为以下三个步骤:
- 初始化一个分片上传事件。
调用bucket.init_multipart_upload方法返回OSS创建的全局唯一的uploadId。
- 上传分片。
调用bucket.upload_part方法上传分片数据。
说明- 对于同一个uploadId,分片号(partNumber)标识了该分片在整个文件内的相对位置。如果使用同一个分片号上传了新的数据,那么OSS上这个分片已有的数据将会被覆盖。
- OSS将收到的分片数据的MD5值放在ETag头内返回给用户。
- OSS计算上传数据的MD5值,并与SDK计算的MD5值比较,如果不一致则返回InvalidDigest错误码。
- 完成分片上传。
所有分片上传完成后,调用bucket.complete_multipart_upload方法将所有分片合并成完整的文件。
https://help.aliyun.com/document_detail/31852.html
适用场景
在典型的C/S系统架构中,服务器端负责接收并处理客户端的请求。那么考虑一个使用OSS作为后端的存储服务,客户端将要上传的文件发送给服务器端,然后服务器端再将数据转发上传到OSS。在这个过程中,一份数据需要在网络上传输两次,一次从客户端到服务器端,一次从服务器端到OSS。当访问量很大的时候,服务器端需要有足够的带宽资源来满足多个客户端的同时上传的需求,这对架构的伸缩性提出了挑战。
为了解决这种场景带来的挑战,OSS提供了授权给第三方上传的功能。使用这个功能,每个客户端可以直接将文件上传到OSS而不是通过服务器端转发,节省了自建服务器的成本,并且充分利用了OSS的海量数据处理能力,无需考虑带宽和并发限制等,可以让客户专心于业务处理。
目前授权上传有两种实现方式:URL签名和临时访问凭证。
https://cloud.tencent.com/document/product/436/34282
分块操作
| API | 操作名 | 操作描述 |
|---|---|---|
| List Multipart Uploads | 查询分块上传 | 查询正在进行中的分块上传信息 |
| Initiate Multipart Upload | 初始化分块上传 | 初始化 Multipart Upload 上传操作 |
| Upload Part | 上传分块 | 分块上传对象 |
| Upload Part - Copy | 复制分块 | 将其他对象复制为一个分块 |
| List Parts | 查询已上传块 | 查询特定分块上传操作中的已上传的块 |
| Complete Multipart Upload | 完成分块上传 | 完成整个对象的分块上传 |
| Abort Multipart Upload | 终止分块上传 | 终止一个分块上传操作并删除已上传的块 |