[
哪个地方做什么的哪家靠谱?
地名词库
行业、业务词库
]
苏州做网络推广的公司哪家靠谱?
苏州镭射机维修哪家最专业?
昆山做账的公司哪家比较好
广州称重灌装机生产厂家哪家口碑比较好
[
含有专家知识
]
郑州律师哪个好,如何判断合同是否有效?
[
哪个地方有做什么的?
]
广东哪里有专业的全铝书柜定制?
苏州吴中越溪哪里有通过率较高的会计培训班?
[
2-gram
]
行业 属性 通过 “2-gram”实现,“动词+名词”
昆山注册公司哪家专业?
注册公司
{'words': '大型 雕铣机 哪个 牌子 好 ?', 'postags': 'b n r n a wp', 'parser': '2:ATT 4:ATT 4:ATT 5:SBV 0:HED 5:WP', 'netags': 'O O O O O O', 'role': [{4: 'A0:(0,3)'}]}
feature ATT SBV HED 相邻
{'words': '深圳市 东荣 纯水 设备 有限公司 有 什么 产品 , 电话 是 多少 ?', 'postags': 'ns nz n n n v r n wp n v r wp', 'parser': '5:ATT 3:ATT 4:ATT 5:ATT 6:SBV 0:HED 8:ATT 6:VOB 6:WP 11:SBV 6:COO 11:VOB 6:WP', 'netags': 'B-Ni I-Ni I-Ni I-Ni E-Ni O O O O O O O O', 'role': [{5: 'A0:(0,4) A1:(6,7)'}, {10: 'A0:(9,9) A1:(11,11)'}]}
feature
[[正规|靠谱]|便宜|价格优惠|价格低]公司
含有ns
{'words': '武汉 哪里 有 织发补发店 ?', 'postags': 'ns r v n wp', 'parser': '3:SBV 3:SBV 0:HED 3:VOB 3:WP', 'netags': 'S-Ns O O O O', 'role': [{2: 'A0:(0,0) A0:(1,1) A1:(3,3)'}]}
地点-[哪里有做]-业务-[的][正规|靠谱]-公司?
{'words': '江西 塑料 厂家 有 哪些 ?', 'postags': 'ns n n v r wp', 'parser': '3:ATT 3:ATT 4:SBV 0:HED 4:VOB 4:WP', 'netags': 'S-Ns O O O O O', 'role': [{'3': 'A0:(0,2) A1:(4,4)'}]}
地点-[做]-业务-[的][正规|靠谱]-公司[有哪些]?
{'words': '龙江 附近 金色 年华 教育 中心 到底 怎么样 ?', 'postags': 'ns nd n n v n v r wp', 'parser': '2:ATT 6:ATT 4:ATT 6:ATT 6:ATT 7:SBV 0:HED 7:VOB 7:WP', 'netags': 'S-Ns O O O O O O O O', 'role': [{6: 'A0:(0,5) A1:(7,7)'}]}
地点-业务-[靠谱吗?到底怎样?]
{'words': '南充 最 好 的 化妆 学校 是 哪家 ?', 'postags': 'ns d a u v n v r wp', 'parser': '6:ATT 3:ADV 6:ATT 3:RAD 6:ATT 7:SBV 0:HED 7:VOB 7:WP', 'netags': 'S-Ns O O O O O O O O', 'role': [{'2': 'ADV:(1,1)'}, {'6': 'A0:(0,5) A1:(7,7)'}]}
地点-[最好的|靠谱的]业务-[是哪家?]
{'words': '昆山 铣刀 厂家 联系 方式 是 多少 ?', 'postags': 'ns n n v n v r wp', 'parser': '3:ATT 3:ATT 5:ATT 5:ATT 6:SBV 0:HED 6:VOB 6:WP', 'netags': 'S-Ns O O O O O O O', 'role': [{'5': 'A1:(6,6)'}]}
地点-[做]-业务-[的][正规|靠谱]-公司[的联系方式是什么?|哪家口碑好值得信赖?]
{'words': '苏州 装修 别墅 怎么 能 省 钱 ?', 'postags': 'ns v n r v v n wp', 'parser': '3:ATT 3:ATT 6:SBV 6:ADV 6:ADV 0:HED 6:VOB 6:WP', 'netags': 'S-Ns O O O O O O O', 'role': [{'5': 'A0:(0,2) ADV:(3,3) A1:(6,6)'}]}
地点-[做]-业务-[怎么能省钱?|费用是多少?|需要注意什么?|有哪些流程?]
from pyltp import *
import os
import re
import json
d_dir = '/usr/local/ltp_data_v3.4.0/'
segmentor = Segmentor()
s = '%s%s' % (d_dir, "cws.model")
segmentor.load(s)
postagger = Postagger()
s = '%s%s' % (d_dir, "pos.model")
postagger.load(s)
parser = Parser()
s = '%s%s' % (d_dir, "parser.model")
parser.load(s)
recognizer = NamedEntityRecognizer()
s = '%s%s' % (d_dir, "ner.model")
recognizer.load(s)
labeller = SementicRoleLabeller()
s = '%s%s' % ('/usr/local/ltp_data_v3.3.0/ltp_data/srl/', '')
labeller.load(s)
def gen_all(paragraph, split_join_tag=' '):
r = {}
# 分词 其他分析依赖于该数据
sentence = SentenceSplitter.split(paragraph)[0]
# segmentor = Segmentor()
# s = '%s%s' % (d_dir, "cws.model")
# segmentor.load(s)
words = segmentor.segment(sentence)
r['words'] = split_join_tag.join(words)
# print(" ".join(words))
# 词性标注
# postagger = Postagger()
# s = '%s%s' % (d_dir, "pos.model")
# postagger.load(s)
postags = postagger.postag(words)
r['postags'] = split_join_tag.join(postags)
# print(" ".join(postags))
# 依存句法关系
# parser = Parser()
# s = '%s%s' % (d_dir, "parser.model")
# parser.load(s)
arcs = parser.parse(words, postags)
r['parser'] = split_join_tag.join("%d:%s" % (arc.head, arc.relation) for arc in arcs)
# print(" ".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
# 命名实体识别
# recognizer = NamedEntityRecognizer()
# s = '%s%s' % (d_dir, "ner.model")
# recognizer.load(s)
netags = recognizer.recognize(words, postags)
r['netags'] = split_join_tag.join(netags)
# print(" ".join(netags))
# 语义角色类型
# labeller = SementicRoleLabeller()
# s = '%s%s' % ('/usr/local/ltp_data_v3.3.0/ltp_data/srl/', '')
# labeller.load(s)
roles = labeller.label(words, postags, netags, arcs)
r['role'] = []
for role in roles:
d = {}
d[role.index] = split_join_tag.join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments])
# print(role.index, "".join(
# ["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
r['role'].append(d)
return r
ori_f = 'list_b_only_title.txt'
r_f = '%s%s' % (ori_f, '.run.txt')
with open(r_f, 'w', encoding='utf-8') as fow:
with open(ori_f, 'r', encoding='utf8') as fo:
for i in fo:
p = i.replace('
', '').replace('"', '')
try:
a = gen_all(p)
except Exception as e:
print(p, ' ', e)
continue
ws = '%s%s' % (json.dumps(a, ensure_ascii=False), '
')
fow.write(ws)
segmentor.release()
postagger.release()
parser.release()
recognizer.release()
labeller.release()
时间占比
特征提取(话术 句术 文本陈述方式 词组织/搭配方式 方式 文法 语义 ) 写正则表达式
import re
import json
ori_f = 'list_b_only_title.txt'
r_f = '%s%s' % (ori_f, '.run.txt')
# {'words': '昆山 注册 公司 找 哪家 比较 好 ?', 'postags': 'ns v n v r d a wp', 'parser': '3:ATT 3:ATT 4:SBV 0:HED 4:VOB 7:ADV 4:CMP 4:WP', 'netags': 'B-Ni I-Ni E-Ni O O O O O', 'role': [{3: 'A0:(0,2) A1:(4,4)'}, {6: 'A0:(0,2) ADV:(5,5)'}]}
select_l = []
reg_l = ['ATT\td+:SBV\td+:HED\td+:VOB\td+']
reg_l = ['HED\td+:VOB\td+:WP']
reg_l = ['HED\td+:VOB\td+:(WP|ADV\td+:CMP)']
c = 0
with open(r_f, 'r', encoding='utf-8') as fowr:
for iii in fowr:
a = json.loads(iii)
a_postags = a['postags']
if 'ns' not in a_postags:
continue
for ii in reg_l:
a_parser = a['parser']
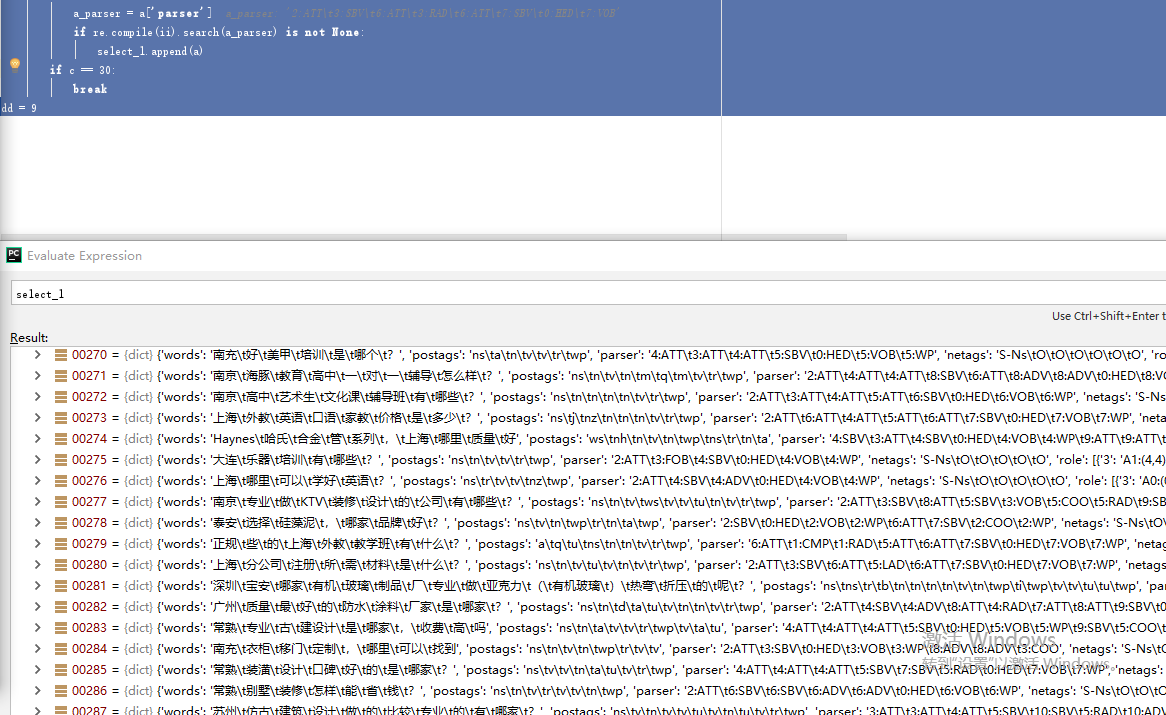
if re.compile(ii).search(a_parser) is not None:
select_l.append(a)
if c == 30:
break
dd = 9
"""
地点-哪里有做-业务-的(正规|靠谱)-公司?
地点-做-业务-的(正规|靠谱)-公司(有哪些?|的联系方式是什么?|哪家口碑好值得信赖?)
地点-做-业务-(怎么能省钱?|费用是多少?|需要注意什么?|有哪些流程?)
地点-业务-(靠谱吗?到底怎样?)
地点-(最好的|靠谱的)业务-是哪家?
"""
p, b = '深圳市', ['广告设计', '网络推广']
ltp_model = ['地点-哪里有做-业务-的(正规|靠谱)-公司?', '地点-做-业务-的(正规|靠谱)-公司(有哪些|的联系方式是什么|哪家口碑好值得信赖)?',
'地点-做-业务-(怎么能省钱|费用是多少|需要注意什么|有哪些流程|靠谱吗|到底怎样)?', '地点-(最好的|靠谱的)业务-是哪家?']
r_l = []
for s in ltp_model:
s = s.replace('地点', p).replace('-', '')
for i in b:
r_l.append(s.replace('业务', i))
def deal_first_splittag_str(i):
s_l_1 = []
psl, psr = i.find('(', 0), i.find(')', 0)
sl, sm, sr = i[0:psl], i[psl + 1:psr], i[psr + 1:]
l = sm.split('|')
for ii in l:
s_l_1.append('%s%s%s' % (sl, ii, sr))
return s_l_1
def deal_first_splittag(s_l_0):
s_l_1 = []
for i in s_l_0:
psl, psr = i.find('(', 0), i.find(')', 0)
if psl == -1:
s_l_1.append(i)
else:
sl, sm, sr = i[0:psl], i[psl + 1:psr], i[psr + 1:]
l = sm.split('|')
for ii in l:
s_l_1.append('%s%s%s' % (sl, ii, sr))
return s_l_1
while True:
f = 0
for i in r_l:
if '(' in i:
f = 1
del r_l[r_l.index(i)]
l = deal_first_splittag_str(i)
r_l += l
if f == 0:
break
d = 9