HTTP The Definitive Guide
Early web pioneers tried using the IP address of the client as a form of identification. This scheme
works if each user has a distinct IP address, if the IP address seldom (if ever) changes, and if the web
server can determine the client IP address for each request. While the client IP address typically is not
present in the HTTP headers,
[1]
web servers can find the IP address of the other side of the TCP
connection carrying the HTTP request.
[1]
As we'll see later, some proxies do add a Client-ip header, but this is not part of the HTTP standard.
For example, on Unix systems, the getpeername function call returns the client IP address of the
sending machine:
status = getpeername(tcp_connection_socket,...);
Unfortunately, using the client IP address to identify the user has numerous weaknesses that limit its
effectiveness as a user-identification technology:
•
Client IP addresses describe only the computer being used, not the user. If multiple users
share the same computer, they will be indistinguishable.
•
Many Internet service providers dynamically assign IP addresses to users when they log in.
Each time they log in, they get a different address, so web servers can't assume that IP
addresses will identify a user across login sessions.
•
To enhance security and manage scarce addresses, many users browse the Internet through
Network Address Translation (NAT) firewalls. These NAT devices obscure the IP addresses
of the real clients behind the firewall, converting the actual client IP address into a single,
shared firewall IP address (and different port numbers).
•
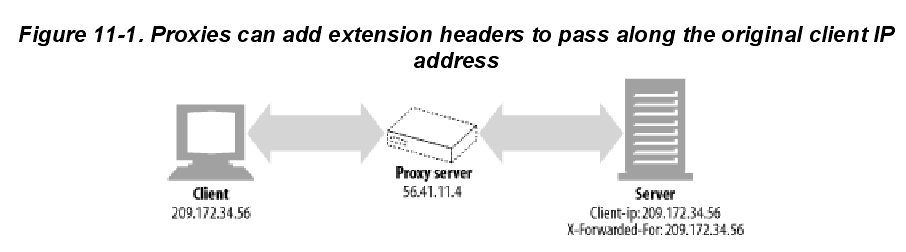
HTTP proxies and gateways typically open new TCP connections to the origin server. The
web server will see the IP address of the proxy server instead of that of the client. Some
proxies attempt to work around this problem by adding special Client-ip or X-Forwarded-For
HTTP extension headers to preserve the original IP address (Figure 11-1). But not all proxies
support this behavior.

Some web sites still use client IP addresses to keep track of the users between sessions, but not many.
There are too many places where IP address targeting doesn't work well.
A few sites even use client IP addresses as a security feature, serving documents only to users from a
particular IP address. While this may be adequate within the confines of an intranet, it breaks down in
the Internet, primarily because of the ease with which IP addresses are spoofed (forged). The presence
of intercepting proxies in the path also breaks this scheme. Chapter 14 discusses much stronger
schemes for controlling access to privileged documents.