哈啰推荐引擎搭建实战 https://mp.weixin.qq.com/s/MGP2UkZZg0nrDJNLEZGtmw
哈啰推荐引擎搭建实战

导读:逛逛是哈啰APP推出的内容社区,旨在为用户提供优质的生活攻略。本次分享以逛逛为例,介绍一下逛逛业务的推荐升级之路。
什么是推荐引擎
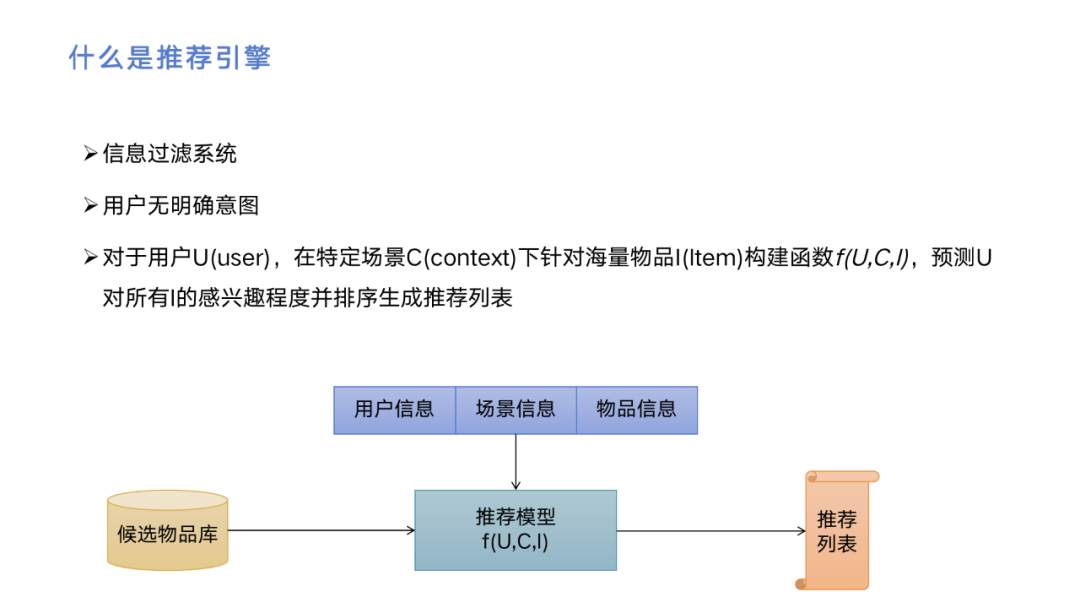
推荐引擎本质上是一种信息过滤系统,特点是用户无明确意图。它跟搜索不一样,用户搜索的时候明确知道自己想看什么,比如说会输入一个关键词,或者是有一些特定的条件,而推荐是希望挖掘出用户感兴趣的东西,然后推给用户。所以,推荐的定义是对于用户,在特定场景下针对海量物品构建函数,预测用户对所有物品的感兴趣程度并排序生成推荐列表。
如何构建推荐引擎
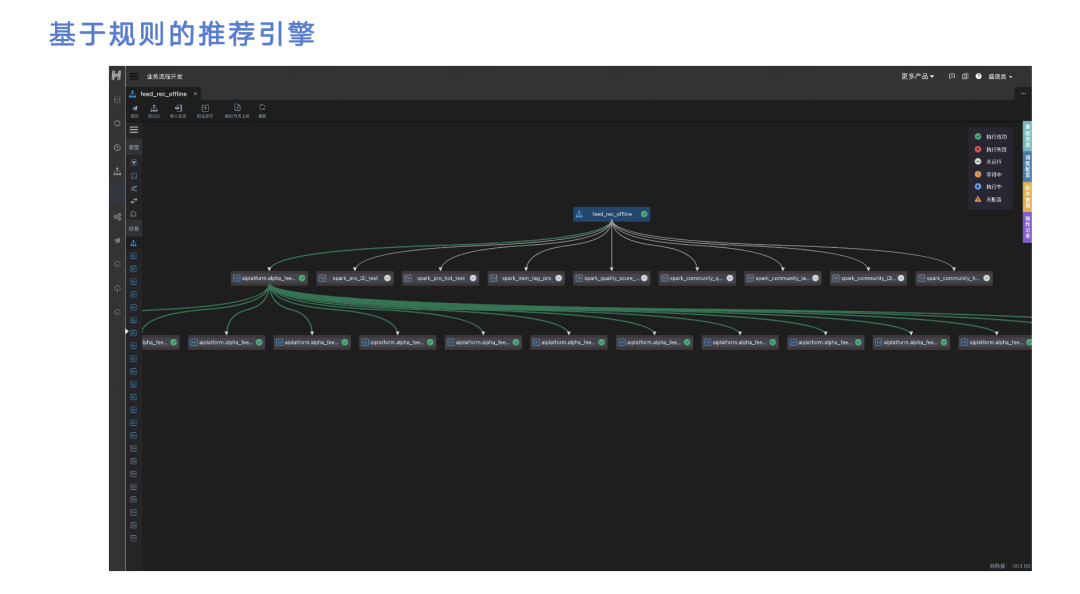
推荐要解决的问题是在一个场景下给用户推荐他感兴趣的物品。对于逛逛业务来说,在我负责前原先使用的推荐服务是基于dataman的业务流程开发,非常复杂,需要将逛逛业务的帖子数据、用户行为数据或用户本身的数据导入到hive里,通过各个hive任务的依赖去计算出推荐的表。如图,最下面的表用来建推荐的,比如需要给用户推过去7天内看过的一些帖子,或用户看过的关注过的人发过的帖子。通过这种方式生成若干个任务,每个任务会生成一个hive表,最终业务会把这些hive表导入到业务的MySQL或者pg里。这其实是一种基于规则的推荐引擎。
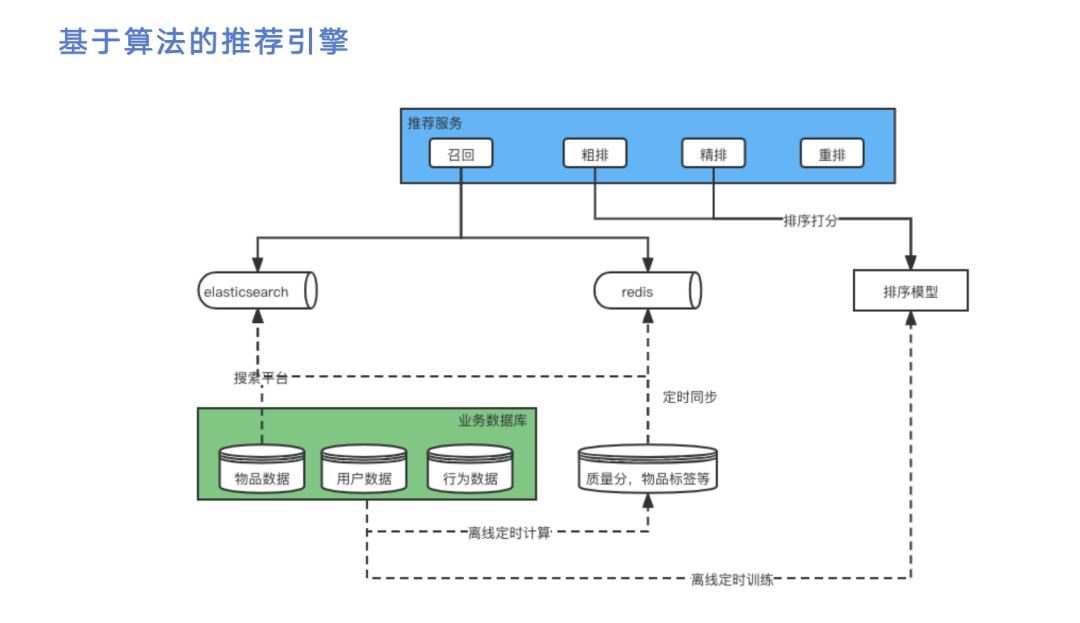
为了引入算法能力,我们构建了一个新的基于算法的推荐引擎,其中最核心的部分在于推荐服务。推荐服务用来接收用户请求并生成推荐结果,里面需要用到一些数据源,我们目前使用的是es和redis。其次,引入算法需要有排序模型,本质上是部署在决策流平台上的。如上图,黑线的实线可以认为是请求的流转过程,虚线可以认为是数据的流转过程。数据可以是物品数据、用户数据或行为数据,这三个数据存储在业务的数据库里面。由于我们最终推的是物品,所以需要把物品数据导入到数据源里面。为什么使用es和redis两个数据源,这里是有权衡考虑的。es可以支持比较复杂的搜索条件和排序需求,redis比较简单,但es的缺点在于性能相对较差。我们会根据不同的召回需求选用不同的数据源存储,物品数据我们目前存储在es。除了物品数据,我们还需要考虑用户数据和行为数据,把这些数据拿到后需要做离线定时计算,生成物品的质量分或标签。此外还需要做离线定时训练,训练出排序模型,由于每隔一段时间用户的行为模式会发生变化,所说这个模型本身也需要变化。
数据源准备好后,我们整个推荐服务分为四步。第一步是召回,也就是从这两个数据源中捞取数据,这部分后面会详细介绍。第二步和第三步叫粗排和精排,粗排的性能比较好但效果会比较差,精排的性能较差但效果较好。接着我们拿到比较好的结果列表进行重排,再返回给业务后端,这里没有把业务后端画出来。业务后端把这个结果透传给前端,这样就得到了用户的推荐列表。
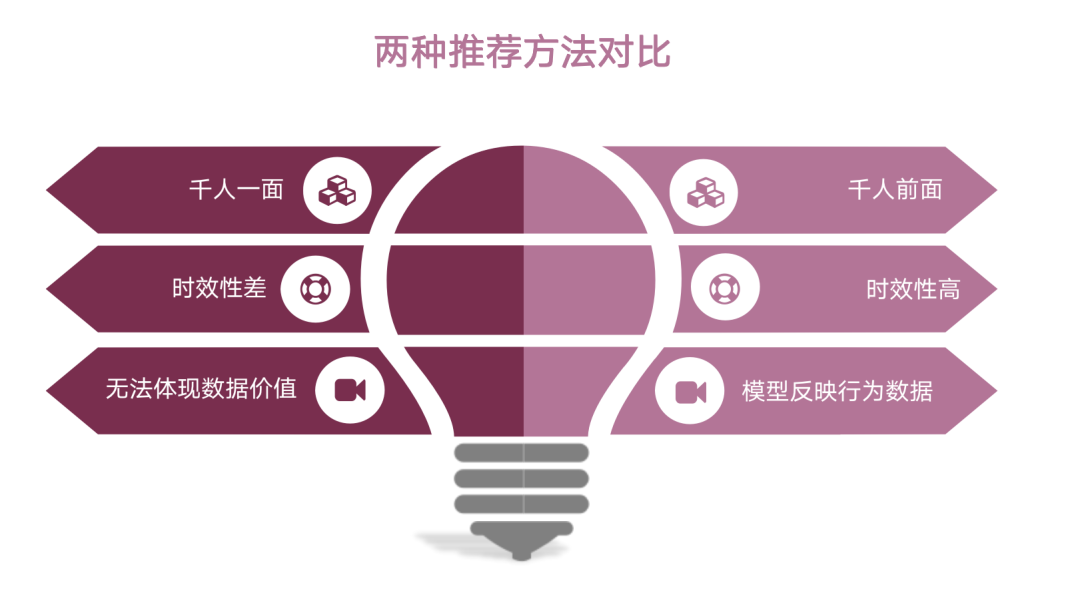
接下来,我们对比一下两种推荐方法。第一,原来基于规则的推荐会造成千人一面,即每个人看到的推荐页面第一页都是一样的。对于基于算法的推荐,由于引入了一些用户的特征,因此可以达到千人千面的效果。
从时效性上,基于规则的推荐由于所有的调度任务都放在dataman上,它可能是定时的处理,所以时效性较差。基于算法的推荐是基于flink任务的实时性开发,所以时效性较高,用户的行为数据可以马上影响到下一页的推荐结果。
第三,基于规则的推荐无法体现数据的价值,因为它是根据产品的需求,产品会拍脑袋认为符合某种模式的帖子效果比较好,并作为需求提出,写一个固定的Hive SQL语句。基于算法的推荐主要通过模型做数据的排序,所以它会通过模型来反映用户的行为数据,能更好体现行为数据的价值。
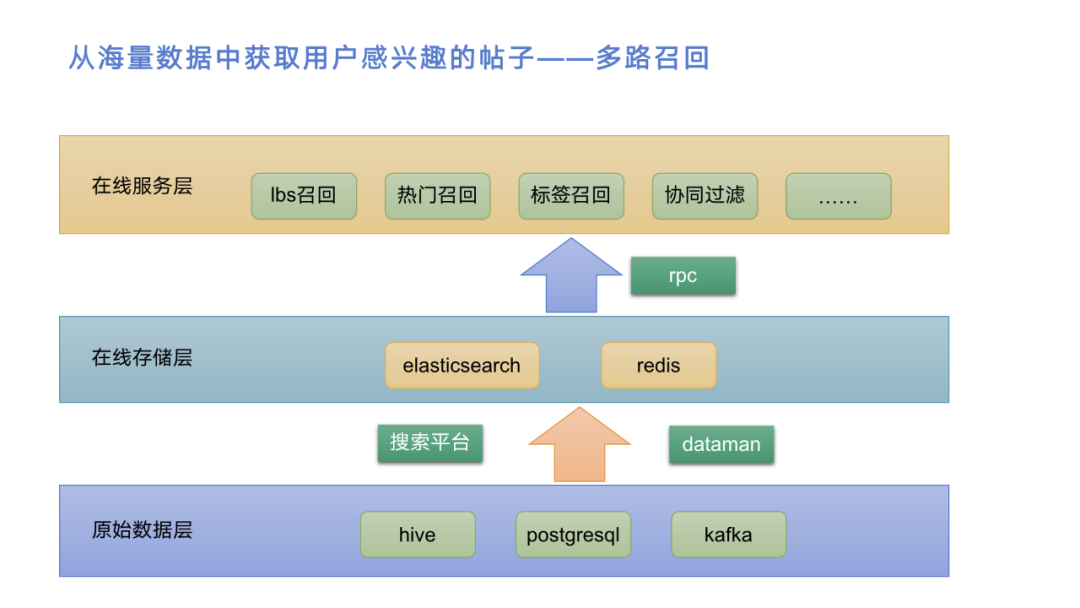
接着我们讲一下召回,就是从海量数据中获取用户感兴趣的帖子。上图是我们召回的分层结构,原始数据在最下面,包括pg、hive和kafka。hive是归档数据,各种依赖全,方便计算;pg是实时业务数据,及时反映业务变化;kafka主要是用户行为数据,及时反映用户行为。接着,通过搜索平台和dataman两个产品将这些数据导入到在线存储的es和redis中,再通过这两个数据存储去支持在线服务进行多路召回。在线服务层和在线存储层间用中间件做,如rpc服务去调用。
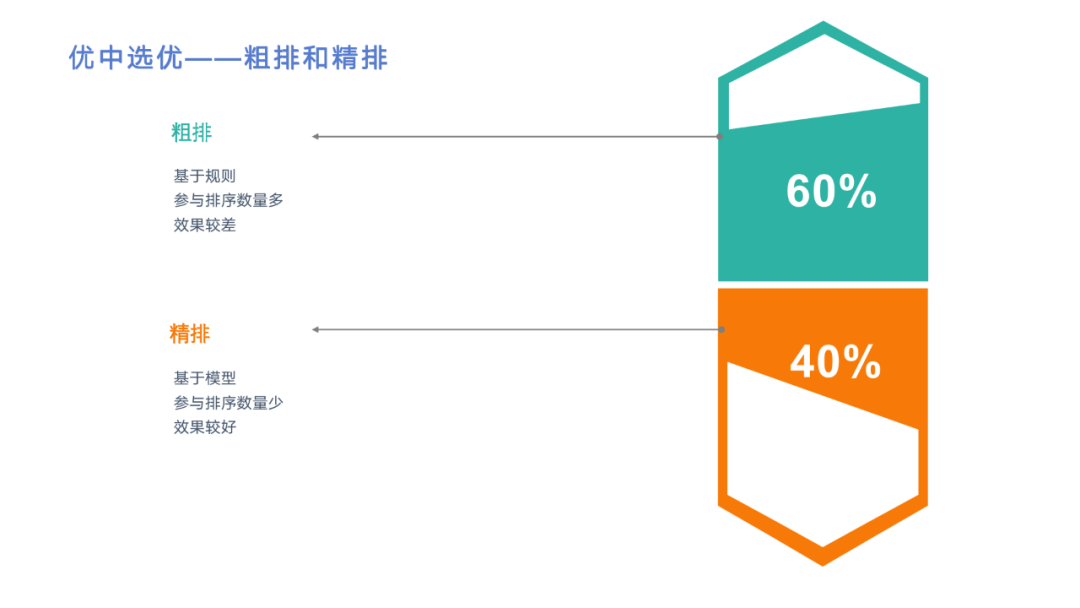
召回后我们需要通过两轮排序进行优中选优,也就是粗排和精排。在之前的架构图中提到粗排和精排都走的模型,但实际算法同学只训练一个模型,所以我们目前粗排是基于规则的。最重要的区别在于粗排要参与排序的数量多,效果较差。精排要参与排序的数量较少,但效果更好。之所以两轮排序,是在性能和效果间取得平衡。当然如果有需求,也可以引入更多轮排序,但这样可能 rpc调用的耗时占比会更高,可能得不偿失。
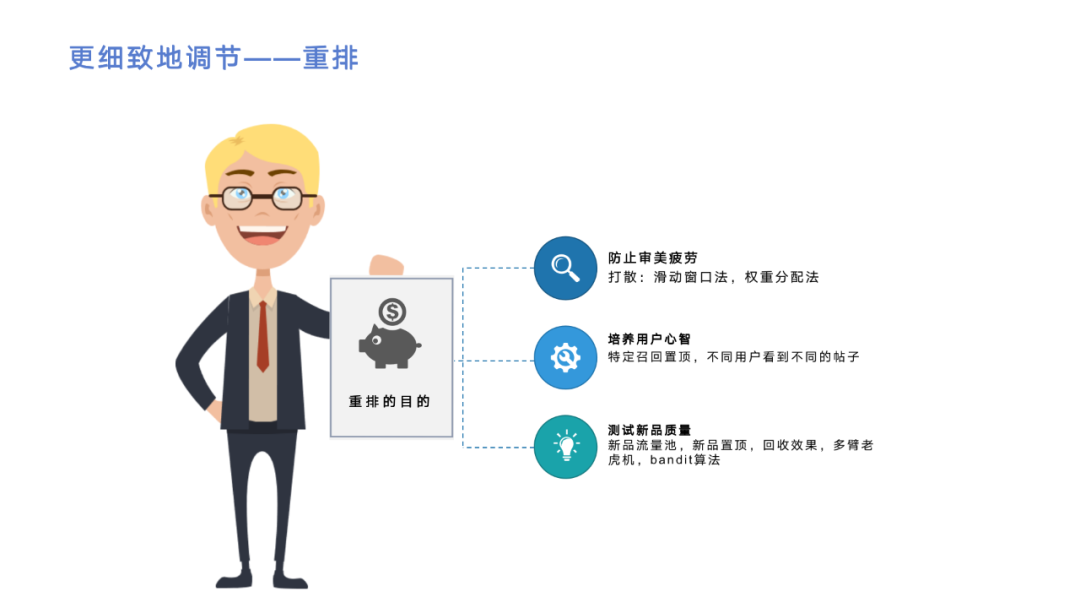
在粗排和精排后,最后一步是重排。重排的目的是为了更细致地调节推荐列表,比如对逛逛来讲,如果有个大V发帖子质量分都很高,某个用户非常关注他,这样用户推荐列表里面可能一页都是同一个人发的帖子,会造成用户审美疲劳。所以,需要有一些业务规则去进行打散,目前我们的算法有滑动窗口法和权重分配法。
第二个目的是为了培养用户的心智。举个例子,在逛逛业务里面我们有一个需求,对于某些人群需要给他推荐某一类帖子,但帖子质量不一定非常高,排序模型不能精确达到把这些帖子排在前面的目的。所以需要在精排后加入重排,然后把特定的帖子置顶。当然置顶也不是直接全排前面,而是通过跳一个插一个的方式把这些帖子放前面,通过这种方式来培养用户的心智。
还有另一种做法是流量池的设定,比如运营觉得某些帖子质量比较高,但他并不知道用户喜不喜欢,或者一些新品也可以放到流量池里面,给它相应的曝光,这样能让用户看到这些帖子并由用户来决定质量高不高。用户如何决定可以通过离线任务来计算,比如看过去一个小时内帖子的CTR怎么样来判断质量高不高,这种方式的实现也是在重排中从流量池捞一些帖子进行置顶,再去回收效果。
这里可以把它抽象成一个算法问题,叫做多臂老lao虎户机问题,解决这个问题的算法是bandit算法。多臂老lao虎户机有多个不同的臂,摇动不同的臂会吐出不同数量的金币,要解决的问题就是通过什么样的策略摇臂,能吐出最大数量的金币。有很多算法可以去解决这个问题,bandit是其中一种算法,映射到推荐服务来讲,就是新品池里每个帖子是一个臂,帖子CTR的值是它吐的金币数,因为我们曝光量有限,应该怎样去把更优秀的帖子获取更大的曝光率,一种比较简单的解决算法叫 bandit算法。
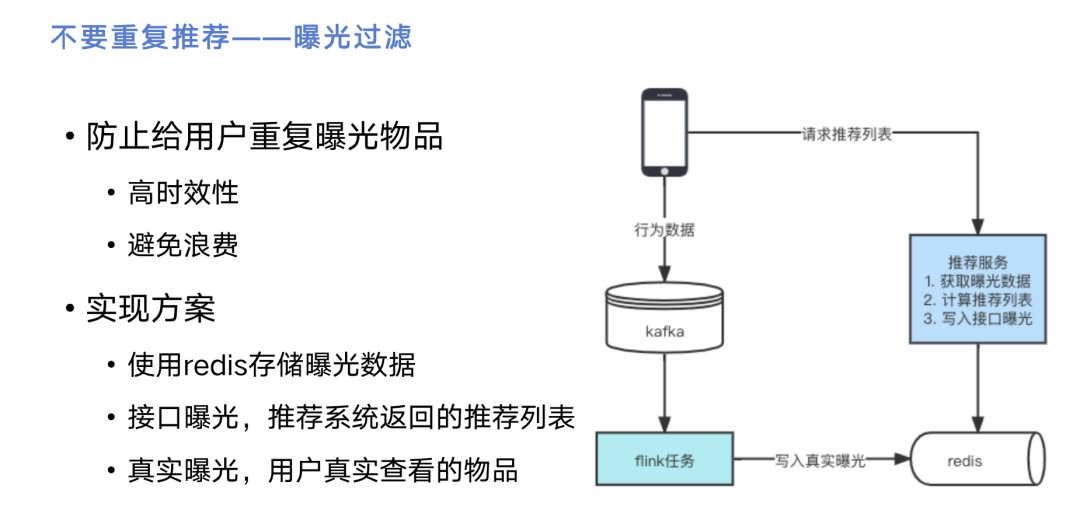
推荐的步骤讲完了,这里还涉及到一个问题是曝光过滤。曝光过滤的目的是防止给用户重复推荐物品,右边是它的实现方案。手机代表用户的APP,他的行为数据由前端采集到kafka里面,再通过flink任务实时读取kafka中的数据,写入到redis里面,redis里面就存储了用户看过的帖子。当一个用户从手机上发送请求,录入到我们的推荐服务上获取曝光数据。我们从多路召回拿到数据之后,需要经过曝光过滤,从redis中获取用户看过的帖子并删除,然后返回给用户。
这里有一个细节,是怎么样定义给用户曝光的帖子。假如我们把通过flink任务写出来的数据作为用户曝光帖子的话会有个问题,比如用户一屏刷了10个,等他刚看完第10个再往下刷的时候,第二屏请求就已经发起了,这时候flink的数据还没来得及写入redis,所以会出现重复。考虑到这个问题,我们可以有另一种解决方案,就是推荐服务在我们自己这边,我们的推荐服务推出来10个,就认为这10个全曝光了,直接把它作为曝光过滤的列表。但这里也有一个问题,很可能用户请求了10个,但一屏可能只看了两三个,这时候就有七八个被浪费了。所以我们的曝光过滤有两个设计目标,一是高时效性,即不能给用户推荐重复的东西;二是避免浪费,比如接口曝光有10个,用户只看2个的话就浪费了8个。我们的实现方案就是在redis中存两个key,一个key写它的真实曝光列表,另一个key写它的接口曝光列表,接口曝光列表是会滚动过期的。我们进行曝光过滤的时候,需要把这两个列表都拿到取个并集作为曝光列表,过滤召回的物品。因为接口曝光数据会定时过期,所以被接口曝光多曝光的一些物品,会在后面适当释放出来,最终还是用真实曝光数据来作它的曝光过滤结果。

接下来是冷启动问题,我们考虑的不是非常多,但它是推荐中大家都面临的一个问题。冷启动分为用户冷启动和物品冷启动,用户冷启动我们没有考虑很多,因为一般用哈啰逛逛业务的用户可能只是没用过这个业务,但其他业务如单车或助力车都已经用过了,所以用户的信息我们已经存在了。假如对一些不存在信息,比如说i2i召回,即系统过滤召回,它的含义是根据用户过往点赞过或评论过的帖子,去找相似的帖子推出来,这种情况可能访问为空,但本质上一些热门或者LBS的路它能访问结果,所以说用户冷启动并不是比较大的问题。
比较大的问题在于物品冷启动,因为我们大量的召回阶段都依赖于算法离线算的数据,比如帖子的质量分、帖子跟帖子的相似度。我们具体的解决算法分成两类,一类是在召回阶段新增新品召回的方法,让新品能够获得一定的曝光量。还有一类是刚提到流量池的方法,可以把一些新品放到流量池里,通过bandit算法把它展示获取一定的曝光量。考虑到排序模型中需要用到特征,因此我们需要对冷启动用户或冷启动物品添加特征默认值。

在推荐做完之后,会涉及到很多性能优化。我们推荐服务的步骤非常多,因此整个推荐请求如果耗时比较长的话,我们并不能知道每一步耗时多久,也不能通过单个case去看,比如只看某一个请求每一步耗时多久,这种情况可能得到的数据只是特例,并没有通用性。所以最终我们的做法是埋了一些点,在推荐请求执行过程中,每一步耗时多久都打印了出来,然后通过采集功能进行采集,在grafana上根据筛选数据源配置大盘。上图就是大盘产生结果,大家可以看到我们推荐的平均耗时大概400毫秒不到,图中每条小线代表各个步骤的耗时,每次请求都是各个步骤耗时之和,取各个不重叠的步骤耗时之和来决定整个耗时,这样我们可以通过曲线的趋势来看到哪一块是耗时的性能热点,我们才需要去解决。
通过这样的图表,我们主要分析出两点。一是召回耗时比较久,因为涉及到很多路召回。二是排序模型耗时比较久,排序模型耗时会由算法同学去优化。接下来重点介绍一下召回阶段如何做性能优化。

左边这张图是我们推荐请求召回一开始实现的版本,在性能优化时就发现了问题。第一步需要进行多路召回,比如LBS召回、标签召回、关注者召回,由于召回复杂所以走的都是es,后面两个召回走的都是redis。我们的做法是每个召回都去线程池中拿一个线程往es或redis中去查询,并返回出结果,这样它的最长耗时就是由所有请求中最长的那个耗时决定的,实际上是木桶原理,即一只水桶能装多少水取决于它最短的那块木板。但这个服务上线之后,在QPS比较低的情况下,请求耗时还可以接受;QPS一旦高起来,耗时就会变得非常长。经过分析,我们发现在访问 es的时候,es请求结果里面会带一个叫took的字段,描述了es在搜索引擎里面运行了多久。然后我们发现去访问es的时候,从一个线程发起请求到拿到结果,耗时比took耗时多了几十倍。原因就在于一个推荐请求进来之后,它会裂变成十几个请求,这样就算我们线程值设置的再大,一个请求就要占用十几个线程,很可能QPS就上不去。
考虑到这点,我们就变成了右图的执行逻辑。每个推荐请求进来之后,同样进行多路召回,但最终从线程池发出的只是两个请求,一个请求查es,另一个请求查redis。这样一个推荐请求其实只分成了两个请求,占了两个线程。es是通过multisearch机制去访问的,比如说左边三路,LBS召回、标签召回、关注者召回,我都把它拼起来变成一个请求,这样只需要请求一次。redis是通过pipeline机制去访问,这样在QPS提升之后,还是能达到跟左边一样,甚至比左边更好的耗时结果。
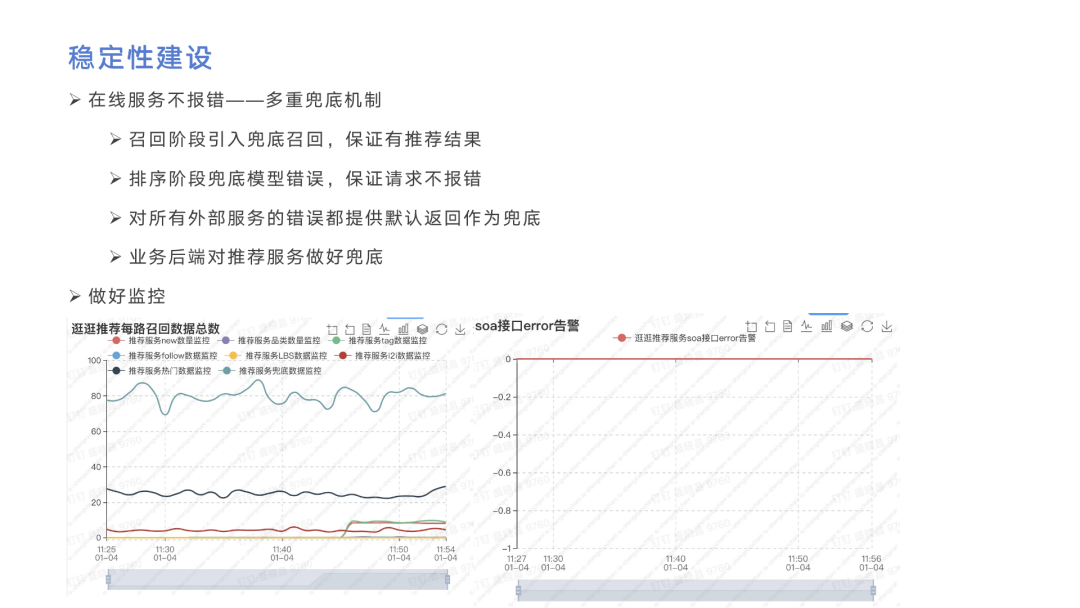
在性能优化之后,稳定性建设也是非常重要的一点。为了在线服务阶段不报错,我们使用了多重兜底的机制。首先在召回阶段引入兜底召回,保证就算其他几路召回为空,也能有推荐结果。第二是在排序阶段也加入兜底操作,保证就算依赖的排序服务出问题,也能反馈出一个比较合理的推荐结果。另外比如说刚刚提到的i2i召回,可能需要获取用户曾经操作过的帖子,也就是说有一个外部依赖的服务去获取。所以我们对所有外部服务的错误都提供默认值作为兜底。除了上述三个在推荐服务里完成,还要考虑到非常极端的情况,即推荐服务本身故障,所以我们在业务后端对推荐服务也做了兜底,保证用户能看到东西。
兜底会有个问题在于SOA不报错,这样我们可能就感知不到,因此必须在兜底做报警,报警我们目前是通过Argus来实现。这里我从Argus上截了一些图,左边是每路召回数据总数,如果某一路跌到变动比较大的阈值,我们就会认为这一路出问题了,需要人工排查告警。右边是依赖的外部服务SOA错误的告警。
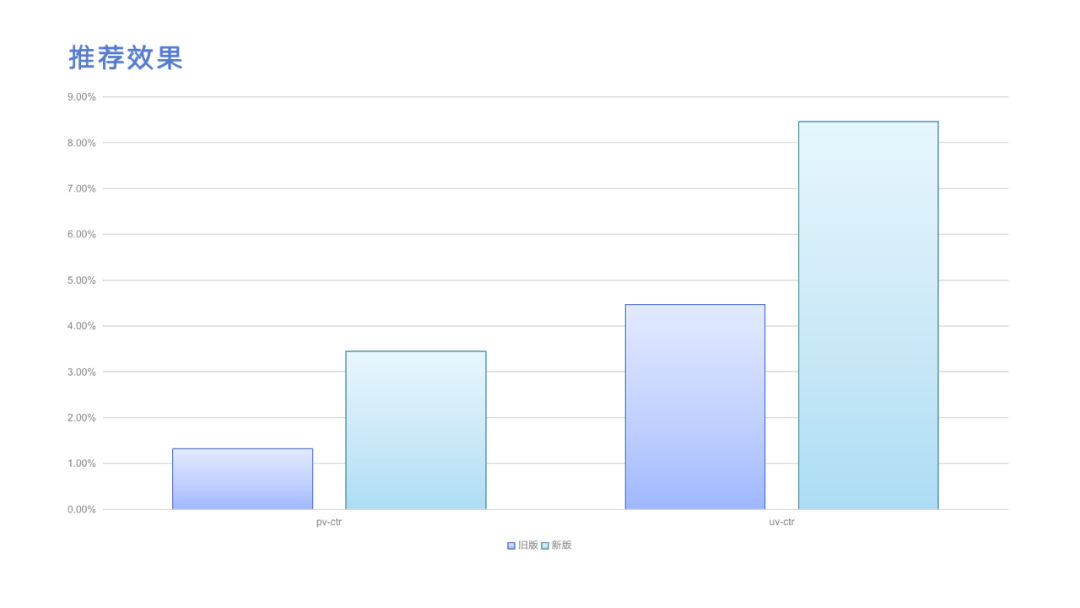
上图展示的是推荐效果,左边是一个旧版推荐服务的 pv-ctr和uv-ctr的指标,右边是新版推荐服务的指标。可以看到提升非常大,当然绝对值还是比较小的。
推荐引擎的后续规划
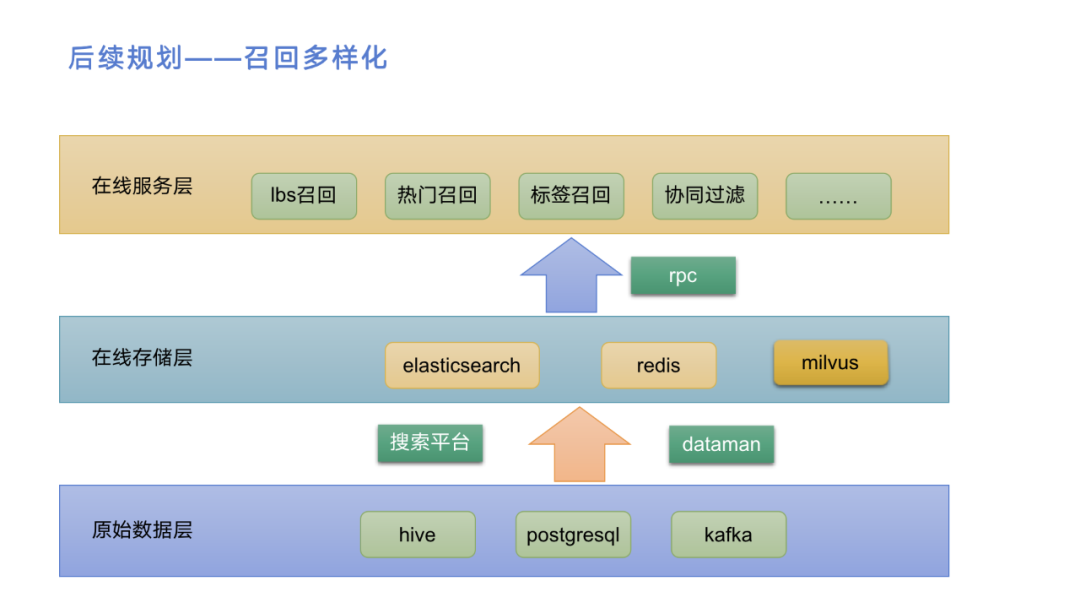
最后介绍一下我们推荐服务后续的规划。未来我们希望在召回这一层再引入向量召回,这也是算法强烈推荐以及觉得效果比较好的召回。因此我们后续的规划主要是在召回多样化,召回多样化有不同层面的含义,在线存储层我们会引入一种新的存储介质,用来支持向量搜索的功能,在线服务层我们会增加更多的召回路径。
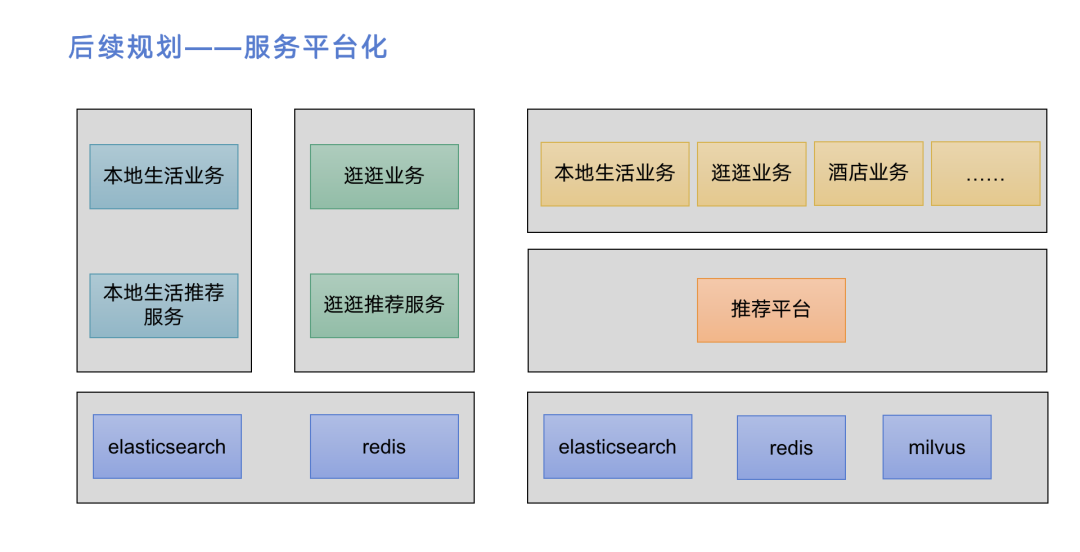
我们还打算把推荐服务变成平台化的服务。除了目前已经接的本地生活和逛逛业务之外,我们可以接更多业务的推荐。左边的图是现有服务的简化架构,数据存储主要是用es和redis。推荐服务各自去支撑各自的业务后端。这种情况下,如果再加一个业务,可能需要再加一个推荐服务,但其实大量代码都是重复的。这样成本会非常高,维护起来也不容易,所以后续我们会把推荐服务平台化。