Completely Fair Scheduler - Wikipedia https://en.wikipedia.org/wiki/Completely_Fair_Scheduler
https://zh.wikipedia.org/wiki/完全公平排程器
Inside the Linux 2.6 Completely Fair Scheduler - IBM Developer https://developer.ibm.com/tutorials/l-completely-fair-scheduler/
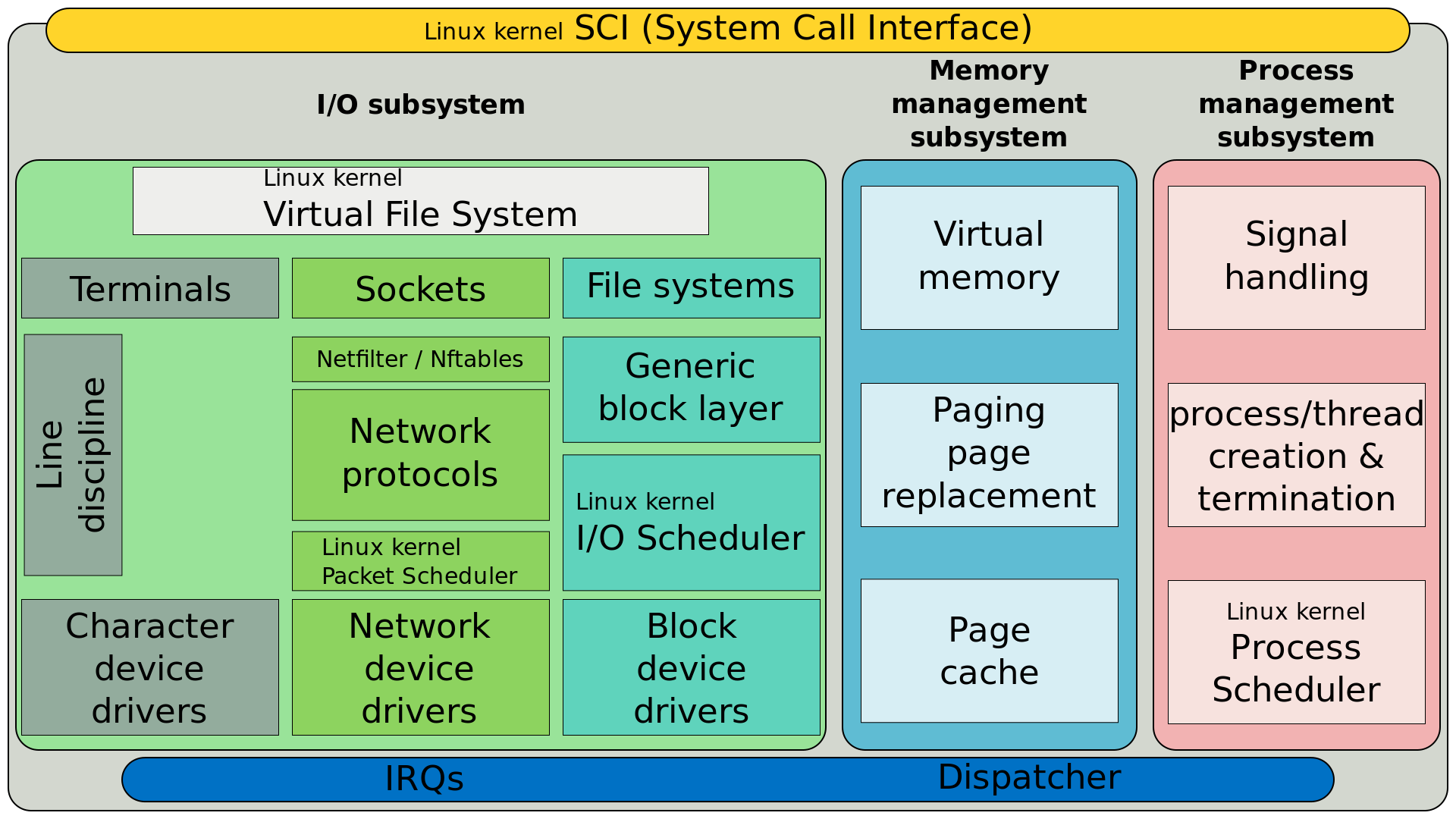
Location of the "Completely Fair Scheduler" (a process scheduler) in a simplified structure of the Linux kernel.
完全公平调度器(英语:Completely Fair Scheduler,缩写为CFS),Linux内核的一部分,负责进程调度。参考了康恩·科里瓦斯(Con Kolivas)提出的调度器源代码后,由匈牙利程式员英格·蒙内(Ingo Molnar)所提出。在Linux kernel 2.6.23之后采用,取代先前的O(1)调度器,成为系统预设的调度器。它负责将CPU资源,分配给正在执行中的进程,目标在于最大化程式互动效能与整体CPU的使用率。使用红黑树来实作,算法效率为O(log(n))。
背景
CFS 是首支以公平伫列(fair queuing)的调度器可应用于一般用途操作系统(general-purpose operating system).[1]
CFS调度器参考了康恩·科里瓦斯(Con Kolivas)所开发的楼梯调度算法(staircase scheduler)与RSDL(The Rotating Staircase Deadline Schedule)的经验[2] ,选取花费CPU执行时间最少的进程来进行调度。CFS主要由sched_entity 内含的 vruntime所决定,不再跟踪process的sleep time,并扬弃active/expire的概念, runqueue里面所有的进程都平等对待,CFS使用“虚拟运行时”(virtual running time)来表示某个任务的时间量。
CFS改使用红黑树算法,将执行时间越少的工作(即 sched_entity)排列在红黑树的左边[3],时间复杂度是O(log N),节点(即rb_node)的安插工作则由dequeue_entity()和enqueue_entity()来完成。当前执行的task通过呼叫 put_prev_task 返回红黑树,下一个待执行的task则由pick_next_task来呼叫。蒙内表示, CFS在百分之八十时间都在确实模拟处理器的处理时间。
争议
因为在Linux 2.6.23 将CFS 合并到mainline。放弃了RSDL,引起康恩·科里瓦斯的不满,一度宣布脱离Linux开发团队。数年后, Con Kolivas 卷土重来, 重新开发脑残调度器来对决 CFS, Jens Axboe 写了一个名为 Latt.c 的程序进行比对,Jens 发现BFS 确实稍稍优于 CFS[4],而且CFS 的 sleeper fairness 在某些情况下会出现调度延迟。[5]Ingo不得不暂时关闭该特性,很快的在一周内提出新的 Gentle Fairness,彻底解决该问题。
The Completely Fair Scheduler (CFS) is a process scheduler that was merged into the 2.6.23 (October 2007) release of the Linux kernel and is the default scheduler of the tasks of the SCHED_NORMAL class (i.e., tasks that have no real-time execution constraints). It handles CPU resource allocation for executing processes, and aims to maximize overall CPU utilization while also maximizing interactive performance.
In contrast to the previous O(1) scheduler used in older Linux 2.6 kernels, which maintained and switched run queues of active and expired tasks, the CFS scheduler implementation is based on per-CPU run queues, whose nodes are time-ordered schedulable entities that are kept sorted by red–black trees. The CFS does away with the old notion of per-priorities fixed time-slices and instead it aims at giving a fair share of CPU time to tasks (or, better, schedulable entities).[1][2]
Algorithm
A task (i.e., a synonym for thread) is the minimal entity that Linux can schedule. However, it can also manage groups of threads, whole multi-threaded processes, and even all the processes of a given user. This design leads to the concept of schedulable entities, where tasks are grouped and managed by the scheduler as a whole. For this design to work, each task_struct task descriptor embeds a field of type sched_entity that represents the set of entities the task belongs to.
Each per-CPU run-queue of type cfs_rq sorts sched_entity structures in a time-ordered fashion into a red-black tree (or 'rbtree' in Linux lingo), where the leftmost node is occupied by the entity that has received the least slice of execution time (which is saved in the vruntime field of the entity). The nodes are indexed by processor "execution time" in nanoseconds.[3]
A "maximum execution time" is also calculated for each process to represent the time the process would have expected to run on an "ideal processor". This is the time the process has been waiting to run, divided by the total number of processes.
When the scheduler is invoked to run a new process:
- The leftmost node of the scheduling tree is chosen (as it will have the lowest spent execution time), and sent for execution.
- If the process simply completes execution, it is removed from the system and scheduling tree.
- If the process reaches its maximum execution time or is otherwise stopped (voluntarily or via interrupt) it is reinserted into the scheduling tree based on its newly spent execution time.
- The new leftmost node will then be selected from the tree, repeating the iteration.
If the process spends a lot of its time sleeping, then its spent time value is low and it automatically gets the priority boost when it finally needs it. Hence such tasks do not get less processor time than the tasks that are constantly running.
The complexity of the algorithm that inserts nodes into the cfs_rq runqueue of the CFS scheduler is O(log N), where N is the total number of entities. Choosing the next entity to run is made in constant time because the leftmost node is always cached.
History
Con Kolivas's work with scheduling, most significantly his implementation of "fair scheduling" named Rotating Staircase Deadline, inspired Ingo Molnár to develop his CFS, as a replacement for the earlier O(1) scheduler, crediting Kolivas in his announcement.[4] CFS is an implementation of a well-studied, classic scheduling algorithm called weighted fair queuing.[5] Originally invented for packet networks, fair queuing had been previously applied to CPU scheduling under the name stride scheduling. CFS is the first implementation of a fair queuing process scheduler widely used in a general-purpose operating system.[5]
The Linux kernel received a patch for CFS in November 2010 for the 2.6.38 kernel that has made the scheduler "fairer" for use on desktops and workstations. Developed by Mike Galbraith using ideas suggested by Linus Torvalds, the patch implements a feature called autogrouping that significantly boosts interactive desktop performance.[6] The algorithm puts parent processes in the same task group as child processes.[7] (Task groups are tied to sessions created via the setsid() system call.[8]) This solved the problem of slow interactive response times on multi-core and multi-CPU (SMP) systems when they were performing other tasks that use many CPU-intensive threads in those tasks. A simple explanation is that, with this patch applied, one is able to still watch a video, read email and perform other typical desktop activities without glitches or choppiness while, say, compiling the Linux kernel or encoding video.
In 2016, the Linux scheduler was patched for better multicore performance, based on the suggestions outlined in the paper, "The Linux Scheduler: A Decade of Wasted Cores".[9]