小结:
1、
Celery如何修复Python的GIL问题
https://python.freelycode.com/contribution/detail/346
最近,我重读了Glyph写的Unyielding。如果你还没有读过,那赶紧去。我将会在下文略述它的内容,但是,原文绝对值得一读。
近十年我都在研究Python全局解释器锁,即GIL。
关于GIL,真正的问题是异步I/O--线程就是作为处理它的简洁方法推广的。你接收到一个请求,你创建一个线程,魔法发生了。关注是分开的而资源是共享的。
但是在Python里,你不能高效的这样做,因为线程需要争夺GIL,而每个解释器只有一个GIL,无论你的机器有多少核。所以,即使你使用顶配的英特尔酷睿i7处理器,你也不会觉得使用线程使性能有很大提升。
理论上是这样的,现实可能更糟糕--Python 3.1之前的GIL实际上在多核处理器上处理多线程时性能更糟糕并且可能使你的代码变得更慢。
异步I/O是问题吗?
现代编程中我们做的大多数任务都可以归结为I/O,或者通常这样回答:
例如,从数据库取数是I/O--你等待数据的时候,系统可以同时做其他事,比如,服务更多请求。
asyncio最近向Python添加的内容是
使用协同程序(coroutines)编写单线程并发代码,通过socket和其他资源实现I/O复用,运行网络服务器和客户端
这里面有一些假设,我将分析一下:
-
人们需要单线程并发代码
-
人们经常需要I/O复用
-
人们使用协同程序
首先,我们真的需要单线程并发执行代码吗?
在过去10年里,我从来没有遇见一个人指出“这个代码需要并发执行但是使用单线程。”
我认为这里的意思其实是我们需要并发执行,这是GIL最具争议的地方--我们不能实现真正的并发。
我最近意识到我们真的不需要并发--稍后讨论这点,此前,我们来列出后面这两条假设,扔掉协同程序。
人们使用协同程序吗?是的,但是不用在生产环境中。这可能有点武断,但是我使用很多种语言编写并发程序,并且从来没有遇到过像协同程序那么难读的。
如果代码意味着可读,那么协同程序就意味着弄瞎你的眼睛。
另外,协作并发又叫协同程序在很久之前就被抛弃了。为什么?
因为协作程序的最基本假设是他们合作。抢先并发强制,或者至少尝试强制,公平使用资源。
协同程序并没有这样幸运--如果你的协同程序阻塞了,你必须等待。你的线程等待所有其他的协同程序。
那是协同程序在现实中的最大问题。如果你的程序是一个shell脚本,用于计算斐波那契数,那或许还行。但是在这种困境,服务器断掉,连接超时,我们不能阅读读取任何安装的开源库的代码。
回到并发执行--我限制可以使用的线程数了吗?不,一次也没有。
我觉得我们既不需要协同程序,也不需要并发性。
我认为我们需要的,并且值得花费精力研究的是,非阻塞代码。
阻塞代码的问题
代码是阻塞的是说代码具有以下两个特征之一:
-
真得阻塞
-
完成需要很长时间
人类是没有耐心的,但是在等待机器完成操作时我们看起来更急不可耐。长时间等待,还是避免阻塞,其实是同一个问题。
我们不需要阻塞一些可以很快做完的事,比如,等待一些慢的操作(数据库请求)完成时,可以响应用户。
抢先并发(线程)是解决这个问题的好方法,有一些优点:
-
代码可读性好
-
更好的利用资源
对于线程可读性--不多说了,他们不是最简单的可以理解的,但是绝对比协同程序好。
关于资源--那真得是从“更好一点”到“不可置信”转变的实现细节。他们中的大部分可以使用双核机器中的两个核。
在经典线程编程我们可以:

如果thread_procession_data超时--我们将会得到一个错误。当第二个核可用时它会使用第二个核。漂亮。
现在我们也可以用Python这样做--不完成一样,但是接近。我们可以把执行处理数据的代码放进一个进程里而不使用thread_procession_data。我当然是在说超级棒的multiprocession库。
但是,那样真的更好吗?
我仍然需要理解几个概念,尤其是进程间是如何共享资源的,那看起来不是很明显。
有更好的方法吗?
无锁的胜利和Celery
作为程序员我只想要不阻塞的代码。
我不关心是通过进程,线程,事物内存还是魔法实现的。
创建一个工作单元,描述它的参数,比如优先级,你的工作完成了。在Python世界里有一个包可以满足你--Celery。
Celery是一个庞大的项目,开始你的第一个任务前有繁杂的配置。但是一旦它开始工作,就变得美妙。
举个例子,工作中我有一个系统,在各种各样的网络入口拉取一个社会股。调用API需要时间,还需要加上网络连接收发数据的时间。
例如:

面向用户的代码超过一秒钟都不能被接受。然而我需要仅在用户访问记录视图时才触发这段代码。我该怎么做?
有了Celery,我就可以用一个任务(task)包裹update_metrics,然后这样做:

这里:
-
update_metrics 是一个耗时操作,但是并没有阻塞
-
queue参数指定执行任务的队列
update_metrics耗时很长--但是多亏Celery我不需要考虑那些:
-
由用户动作准确触发
-
代码可读性高,并且非常明确
-
资源可用时便会使用
最重要的是:我不必再苦恼于代码是否在执行I/O,我是否应该让出,或者它是被CPU或I/O强迫的。
Celery可以做的事
你的问题有:抓取1000 URLs,然后计算用户在表格里指定的3个词的频率。
通常,这很难--你需要定位将要抓取的URLs。连接可能超时,你需要一直等待直到所有任务完成,并且你需要以某种方式存储用户的输入。
不使用Celery,搞清楚哪里以及如何存储数据就是一个噩梦。使用Celery我只需要任务:
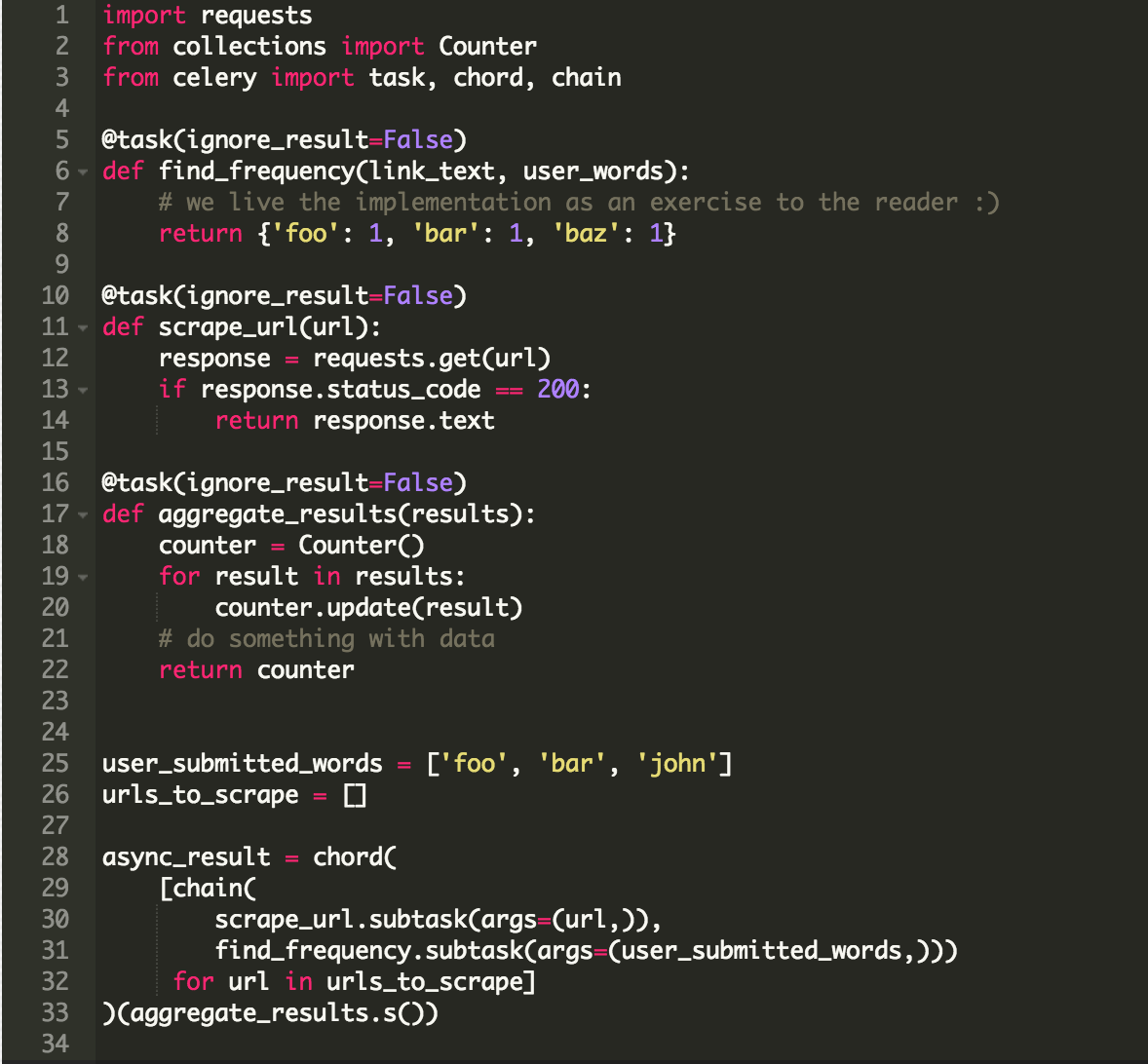
这个例子的主要部分在最后几行:
-
chain用来在任务间建造通道,一个的输出成为另一个的输入
-
chord用来将任务分组,使一个任务在其他任务都完成后才执行
这样写优点有很多:
-
你不需要了解它是如何执行的。可以是线程或进程或协同程序。(在某种程度上,Celery支持所有类型池)
-
你不???
对了,这个例子里也有一些缺点:
-
因为Celery任务是函数,我们不得不使用scrape_url.subtask(args=(url,))语法,它并不易读
-
Celery需要明确的任务路径,作为内嵌函数的任务,通常,task.py模块--不能在其他任务中定义或者提交任务
-
因为我们不能在一个任务的内部定义或者通过调用另一个任务串联起任务,需要chord和chain这样的对象,而这些对象使代码变复杂
无锁?
抛开前面列出的问题,对我而言,最大的问题是细粒度控制的缺乏。队列是一个伟大的实现无锁编程的基本模型。
前面的例子假设你需要执行一堆任务然后聚合结果--大约30行代码的map/reduce。
但是让我们考虑一种更加困难的情形--假设我们有一个不支持并发的任务,完全是无锁的,但是需要读写而不使用阻塞。
我们应该怎么做?
首先(这里我假设你使用Django整合)

这就是运行一个同时处理最多一个任务的任务执行单元(worker)所需要做的全部工作。

因此,不用做任何特别的事情,没有锁,没有GIL问题,我们可以读写一个值。
当然,这有一个主要问题--我们不能同时读取,即使可以。
结语
对我来讲,这总结了整个GIL和协同程序/同步的争论。我认为Python核心的主要问题是它很大程度上由C启发。但是,在这里我认为这是Python的缺陷。
而且我不知道这方面努力的原因。
有数百家公司运行Python代码作为连接逻辑(glue logic)--单线程同步代码(看看Django多受欢迎)但是这些公司服务数以万计的用户。
我认为如果我们想要Python完全支持同步,这是方法。引入基于队列的完全无锁以及允许编程人员修改队列。
Celery已经实现了其中的大部分。为了在Python里拥有这些,我们需要扩展解释器来管理任务执行单元和队列,添加一些语法糖衣用来进行内嵌任务的定义和调用以便使用。
作为编程人员,我认为我们从来不需要异步代码。我从来不需要协同程序,也从来不需要多重I/O。
我需要的是高效表达想法和我想到它的方式的工具,抽象线程、抛弃同步、使用无锁例程解决了这个问题。
https://mp.weixin.qq.com/s/rmOwqwLRoGPR40486xL8dg