最近学人工智能,讲到了Kaggle上的一个竞赛任务,Ames房价预测 。本文将描述一下数据预处理和特征工程所进行的操作,具体代码Click Me。
原始数据集共有特征81个,数值型特征38个,非数值型特征43个。有很多缺失值。
1、离群点检测
以GrLivArea(地上面积)和SalePrice(房价)为自变量和因变量,得到如下散点图:
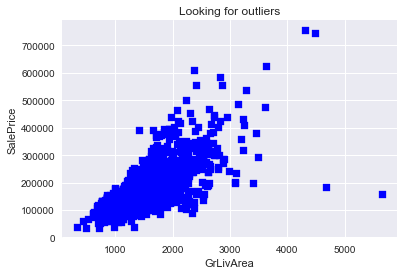
从上图中可以看出有2个极端的离群点在图的右下角(面积很大,但价格很低)。该数据集的提供者建议移除面积大于4000 square feet的数据点(这样就去掉了4个点)。
当然也可以使用其他特征作为自变量,来绘制散点图,检查是否存在离群点。
2、缺失值处理
缺失值处理方法有:删除、统计填充、统一填充、预测填充、具体分析。(可参考这里)
2.1、具体分析,填充缺失值
首先,在Kaggle提供的数据描述中,有说明部分缺省值意味着什么,例如:
BsmtQual: Evaluates the height of the basement
Ex Excellent (100+ inches)
Gd Good (90-99 inches)
TA Typical (80-89 inches)
Fa Fair (70-79 inches)
Po Poor (<70 inches
NA No Basement
也就是说,如果“地下室质量”的值缺失,说明没有地下室。因此,如果BsmtQual值缺失,我们设置为一种新的取值:No(非数值型特征)。如果BsmtFullBath(地下室完整浴室的数量)的值确实,直接设置为0(数值型特征)。
其次,就要对特征进行具体分析了。比如,CentralAir(是否有中央空调)缺失,倾向于没有(如果有的话,房东一般都会写出来吧)。
2.2、其它缺失值填充
上一步未能填充的缺失值,这一步进行统一处理。数值型特征使用中位数填充,非数值型特征将缺失设置为一种新的类型。
3、数值型数据和非数值型数据的转换
有些特征,虽然取值是数值型的,但这些数值是分类的意思,作为数值进行统计分析没有意义,例如:
MSSubClass: Identifies the type of dwelling involved in the sale.
20 1-STORY 1946 & NEWER ALL STYLES
30 1-STORY 1945 & OLDER
40 1-STORY W/FINISHED ATTIC ALL AGES
45 1-1/2 STORY - UNFINISHED ALL AGES
50 1-1/2 STORY FINISHED ALL AGES
60 2-STORY 1946 & NEWER
70 2-STORY 1945 & OLDER
75 2-1/2 STORY ALL AGES
80 SPLIT OR MULTI-LEVEL
85 SPLIT FOYER
90 DUPLEX - ALL STYLES AND AGES
120 1-STORY PUD (Planned Unit Development) - 1946 & NEWER
150 1-1/2 STORY PUD - ALL AGES
160 2-STORY PUD - 1946 & NEWER
180 PUD - MULTILEVEL - INCL SPLIT LEV/FOYER
190 2 FAMILY CONVERSION - ALL STYLES AND AGES
这一特征是房屋风格。虽然取值是数值型的,但这些数值是对风格的分类,应该转换为非数值型的特征。
还有一些特征虽然在类别型的,但存在明显的数值等级,例如:
Alley: Type of alley access to property
Grvl Gravel
Pave Paved
NA No alley access
这一特征是指通向房屋的道路类型。Grvl是碎石路,Paved是水泥路,NA是不通道路。显然,Grvl、Pave、NA这三者存在的关系,分别设置为0、1、2。
4、创建新的特征
4.1、简化已有特征
例如:
OverallQual: Rates the overall material and finish of the house
10 Very Excellent
9 Excellent
8 Very Good
7 Good
6 Above Average
5 Average
4 Below Average
3 Fair
2 Poor
1 Very Poor
该特征是房屋的使用材料和完成品级,从最好到最差,设置了10的档次。我们相应的设置一个简化的SimplOverallQual,将数据的1、2、3映射为1(低品级),4、5、6映射为2(中等水平),7、8、9、10映射为3(高品级)。
4.2、联合已有特征
例如,设置一个新的特征PoolScore(游泳池得分),取值为PoolArea(游泳池面积)和PoolQC(游泳池质量)的乘积。
4.3、现有重要特征(top 10)的多项式
通过计算协方差,找到10个跟房价关联性最强的特征,我们得到了AllSF,AllFlrsSF,GrLivArea,OverallQual,GarageCars,TotalBsmtSF,GarageArea,TotalBath,ExterQual,1stFlrSF这是个特征。
对于top10的每一个特征,都设置三个新的特征,分别是该特征的平方、立方、平方根。
5、数值型特征的数据标准化
数值型特征填充了缺失值之后,我们使用sklearn模块里面的StandardScaler()函数,进行标准化。处理后的数据期望为0,方差为1。
6、非数值型特征处理
对非数值型特征进行one hot编码。
7、遇到的问题
7.1、不要添加与某个属性线性相关的属性。
例如,YearBuilt这个属性,表示的是房屋建造年费。我尝试添加一个房龄属性HouseAge = 2017 - YearBuilt。添加之后,模型的正确率反而下降了。无正则项的线性回归,校验集正确率出现了大幅下滑,LinearRegression.score是个很大的负数,说明模型特别差劲;岭回归校验集正确率出现了小幅下滑。
实际上根本没有必要添加HouseAge。我们看一下HouseAge和YearBuilt标准化之后(使用StandardScaler,转化后均值为0,标准差为1),分别为Std_HouseAge和Std_YearBuilt。由方差与均值的计算规则可知,Std_HouseAge = -Std_YearBuilt。