索引是数据库优化中最常用也最重要的手段之一,通过索引可以解决大多数的sql性能问题。在mysql中,索引是在存储引引擎层而不是服务器层实现的,所以,并没有统一的索引标准:不同的存储引擎的索引的工作方式并不一样,也不是所有的存储引擎都支持所有类型的索引。即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不通过。
一、索引的分类
InnoDB存储引擎支持以下几种常见的索引:
- B+树索引:我们通常在讨论索引的时候,如果没有特别指明,通常说的就是B+树索引。MyISAM和InnoDB存储引擎的表默认创建的都是B+树索引。B+树索引中的B不代表二叉树(binary),而是代表平衡树(balanced)。B+树索引并不是一颗二叉树。
- Hash索引:InnoDB存储引擎是支持hash索引的,并且是自适应的,InnoDB存储引擎会根据表的使用情况自动为表生成创建hash索引,不能人为干预是否在表中创建hash索引。
- 全文索引:InnoDB从Mysql5.6版本开始提供对全文索引的支持。仅限于CHAR、VARCHAR和TEXT列。全文索引只能用于英文,如果出现中文,还是应该使用Lucene等第三方开源框架来处理。
Mysql官方文档Introduction to InnoDB中图表已经表明了InnoDB存储引擎并不支持Hash索引,但InnoDB内部会使用自适应Hash索引来进行字典的查找,但仅仅是内部使用,并不能手动进行干预。
二、B+树索引
B+树是由二叉查找树(BST),再由平衡二叉树(AVL),B树演化而来,这几种树的知识可以参考排序二叉树、平衡二叉树、红黑树、B树、B+树。B+树的操作可以参考B+树的插入和删除操作。
1.为什么数据库索引使用B+树结构,而不选择Hash结构或其它树结构?
索引为什么不用Hash结构?
我们可以看一下Mysql参考官方文档中B树索引和Hash索引的对比:8.3.8 Comparison of B-Tree and Hash Indexes,其中Hash索引的特点中已经说的很清楚了:
- 对于等值查找非常快,但不适合等范围比较操作,如<,between等。
- 不适合顺序查找。(优化器不能使用Hash索引进行ORDER BY操作)
- MySQL不能判断两个值间大致有多少行记录(范围优化器会根据这来决定选用哪个索引)
- 不适合前缀匹配查找
所以Hash索引不适合作为数据库索引。不适合并不表示数据库不支持,实际上Mysql是支持Hash索引的,其Memory存储引擎就支持Hash索引,前面也提到了InnoDB内部会使用自适应Hash索引来进行字典的查找。
索引为什么不用其它树型结构?
普通的二叉树虽然查找时间为O(logN),但极端条件下会退化到O(N)。
平衡二叉树(AVL树和红黑树)解决了极端条件下查找效率低的问题,但无论如何,二叉的结构决定了树的高度太大,导致IO次数过度,不太适合。
所以只有平衡的多路查找树才比较适合,其中由B树和B+树的不同特点,决定了B+树才适合作为数据库的索引。
①磁盘IO
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,所以索引的组织结构要尽量减少查找过程中磁盘I/O的存取次数。B树的节点既要存索引信息,又要存数据,与B+树相比,在相同数据量下,B树相对需要更多次的IO操作。
②查找方式
数据库需要经常进行范围查找,B+由于其数据都按照顺序保存在叶子节点中,且相互间有指针相连。这样的特点非常适合顺序查找和范围查找。
2.OLTP和OLAP应用中B+树索引的使用
应用程序分为两种:OLTP和OLAP。OLTP应用中,查询操作只从数据库中取得一小部分数据,一般在10条记录以内,甚至很多时候只取一条记录,如根据主键获取用户信息,根据订单号取得订单详细信息,这都是典型的OLTP应用。在这种情况下,B+树索引建立后,对该索引的使用应该只是通过该索引取得表中少部分数据。这时建立B+树索引才是有意义的,否则即使建立了,优化器也可能选择不适用索引。
而对于OLAP应用,则需要访问表中大量的数据,根据这些数据来产生查询的结果,这些查询多是面向分析的查询,目的是为决策者提供支持。如本月每个用户的消费情况,销售额同比、环比增长情况等。这些复杂的查询要涉及到多张表之间的连接操作,因此索引的添加依然是有意义的。但是,如果连接操作使用的Hash Join,那么所以可能又变得不是非常重要。这就需要仔细研究自己的应用了。OLAP应用通常会需要对时间字段进行索引,这是因为大多数统计需要根据时间维度来进行数据的筛选。
三、聚集索引和辅助索引
数据库中的B+树索引可以分为聚集索引和辅助索引(非聚集索引)。无论是聚集的还是辅助的,其内部都是B+树,即高度平衡的,叶子存放着所有的数据。聚集索引与辅助索引不同的是,叶子节点存放的是否是一整行的信息。
1.聚集索引(clustered index)
官方文档:14.6.2.1 Clustered and Secondary Indexes
聚集索引,又称为聚簇索引,它并不是一种单独的索引类型,而是一种数据存储方式。每张InnoDB表都有一个聚集索引,表中的数据行就存储在聚集索引中。通常来讲,聚集索引和主键具有相同的含义,但是并不总是如此。
- 如果表显式的定义了主键,InnoDB就会将该主键作为聚集索引。
- 如果表没有显式的定义主键,则会使用第一个非NULL的唯一索引作为聚集索引。非空指的是该唯一索引中的所有key都是非空的。
- 如果没有显式的定义主键,也没有合适的唯一索引,InnoDB就会隐式的创建一个6位的主键自增列,并以该列来创建名为GEN_CLUST_INDEX的聚集索引。该自增列中会记录当前行的行ID,每插入一行记录,对应行的行ID就会自增1,因此行的排列顺序就是行的物理插入顺序。
聚集索引是如何加速查询速度的
通过聚集索引来查询时,最终索引到的页中就直接存储了所有的行记录,无需再进行额外的查询操作,所以大大提升了查询效率。当表非常大时,与未使用聚集索引的索引结构相比,则会节省磁盘IO。
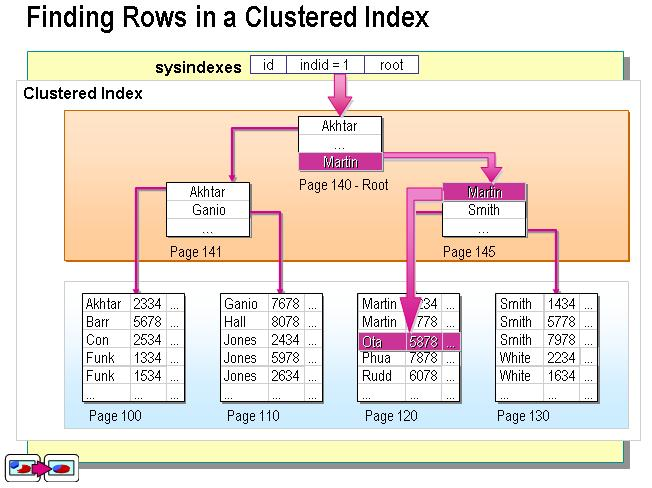
2.辅助索引(非聚集索引,nonclustered index)
辅助索引,也称为非聚集索引或二级索引,除聚集索引以外的所有索引都称为辅助索引。在InnoDB中,辅助索引中的每个记录都包含了该行的主键列,以及为辅助索引指定的列。InnoDB使用此主键值在聚集索引中搜索行,我们称之为回表。
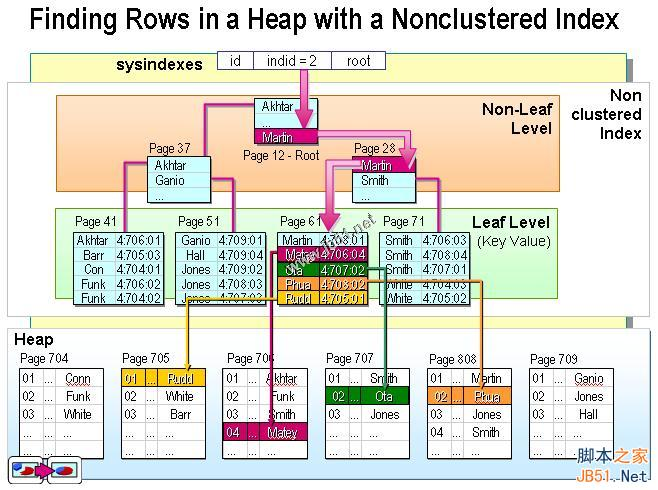
3.两者的区别
非聚集索引和聚集索引的区别在于:
由于聚集索引的叶子节点存放的是完整的行记录信息,而非聚集索引的叶子节点存放的是所要查找的行记录的主键值。所以通过聚集索引可以一次查到需要查找的数据,而通过非聚集索引第一次只能查到记录对应的主键值,需要再次使用主键的值通过聚集索引查找才能到需要的数据。
聚集索引一张表只能有一个,而非聚集索引一张表可以有多个。
四、联合索引和覆盖索引
1.联合索引
官方文档:8.3.5 Multiple-Column Indexes
联合索引是在表上的多个列进行索引。比如在如下的表中创建一个联合索引(a,b)
CREATE TABLE t( a INT, b INT, PRIMARY KEY (a), #主键索引 KEY idx_a_b (a,b) #联合索引 )ENGINE=INNODB
联合索引的B+树如下。通过叶子节点可以逻辑上顺序的读出所有数据,(1,1),(1,2),(2,1),(2,4),(3,1),(3,2)
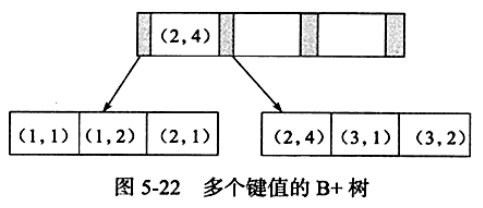
能够使用联合索引的情况
#全匹配 select * from t where a=xxx and b=xxx #最左前缀匹配。 select * from t where a=xxx
不能使用联合索引的情况
#不能使用联合索引。叶子节点上b的值为1,2,1,4,1,2,显然不是排序的。 select * from t where b=xxx
同理,如果建立(a,b,c)索引,则下面的查询都能用到索引。
select * from t where a=xxx and b=xxx and c=xxx
select * from t where a=xxx and b=xxx
select * from t where a=xxx
select * from t where b=xxx and c=xxx
联合索引可对第二个列进行排序处理,减少一次filesort。
在联合索引(a,b)中,由于a相同的情况下b本来就是排序的,所以下面的查询能够用到(a,b)索引,且不需要额外再进行排序。
select * from t where a=xxx order by b
同理,如果建立(a,b,c)索引,下面的查询也能少一次fileSort。
select * from t where a=xxx and b=xxx order by c select * from t where b=xxx order by c select * from t where a=xxx order by b
2.索引的列顺序问题
联合索引的列顺序非常重要,列的顺序能够决定一个索引的好坏。
对于如何选择索引的列顺序有一个经验法则:将选择性最高的列放到索引最前列。当然这只是一个建议,场景不同选择也不同,并没有一个放之四海接皆准的法则。
当不需要考虑排序和分组时,将选择性最高的列放在前面通常是很好的。这时索引的作用只是用于优化WHERE条件的查找,这种情况下,设计的索引确实能够最快地过滤出需要的行,对于在WHERE字句中只使用了索引部分前缀列的查询来说选择性也更高。
更具体的例子和详细说明可以参考《高性能mysql》5.3.4 P159多列索引章节
3.覆盖索引
要查询的所有列都被包含在一个索引中,称为覆盖索引,此时索引将大大提高查询性能。
并不是所有类型的索引都可以成为覆盖索引。覆盖索引必须存储索引列的值,而hash索引、全文索引等都不存储索引列的值,所以Mysql只能使用B+树索引做覆盖索引。当发起一个被索引覆盖的查询时,在explain的extra列中可以看到Using index的信息。
更具体的例子和详细说明可以参考《高性能mysql》5.3.6 P159覆盖索引章节
4.能够使用索引和索引失效的典型场景
五、更多
《高性能mysql》第5章
官方文档:
- 8.3.1 How MySQL Uses Indexes
- 8.3.2 Primary Key Optimization
- 8.3.3 Foreign Key Optimization
- 8.3.4 Column Indexes
- 8.3.5 Multiple-Column Indexes
- 8.3.6 Verifying Index Usage
- 8.3.7 InnoDB and MyISAM Index Statistics Collection
- 8.3.8 Comparison of B-Tree and Hash Indexes
- 8.3.9 Use of Index Extensions
- 8.3.10 Optimizer Use of Generated Column Indexes
- 8.3.11 Indexed Lookups from TIMESTAMP Columns
面试题:
1.索引的优点?缺点?
2.不适合创建索引的场景?
对于非常小的表,大部分情况下简单的扫描更高效。
3.索引的原理?
4.索引为什么使用B+树数据结构,而不选择Hash或者红黑树数据结构?
5.聚集索引和非聚集索引的区别?
6.能有效利用索引的情况和索引失效的情况?
需要注意的是:B+树索引并不能找到一个给定键值的具体行,B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
7.索引中为什么不能有NULL值?
8.什么是索引覆盖?