论文1
https://arxiv.org/pdf/1705.00108.pdf
Semi-supervised sequence tagging with bidirectional language models
理解序列标注中,如何使用动态embedding向量(bilstm)
1、上下文敏感 2、泛化能力增强
论文2
https://arxiv.org/pdf/1802.05365.pdf
Deep contextualized word representations
我感觉第一篇文章就是这篇文章的特例,上篇是将BILM的两个双向隐层去和task rnn的隐层组合,但是这篇文章的BILM是多层的,通过加权的方式把不同隐层的token表示和task rnn组合。
**BiLM在pre-train的时候,如何调整参数呢?-- LM的目标都是最大化概率预测下一个词,P(t1,t2,。。tk)=。。,所以在这样的目标下更新LM的参数
对LM的理解真的非常重要,感觉现在才真正弄懂了--
语言模型的评价目标:语言模型的计算的概率分布能够与真实的理想模型的概率分布可以相接近
常用的几个指标:交叉熵,困惑度
困惑度:其基本思想是给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好
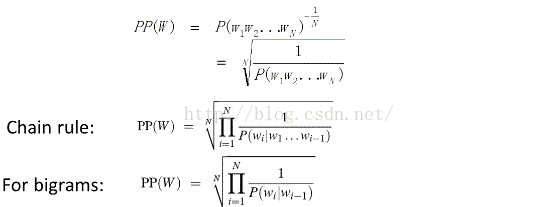
task rnn的训练的时候,BILM是fiexed,但是参数伽马和sj是需要不断调整的
名词解释:
context-independent : glove这些就是context independent的,但是经过rnn后就是上下文敏感的
We tie the parameters for both the token representation (Θx) and Softmax layer (Θs) in the forward and backward direction while maintaining separate parameters for the LSTMs in each direction. Overall, this formulation is similar to the approach of Peters et al. (2017), with the exception that we share some weights between directions instead of using completely independent parameters.
论文3
https://yq.aliyun.com/articles/601452
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
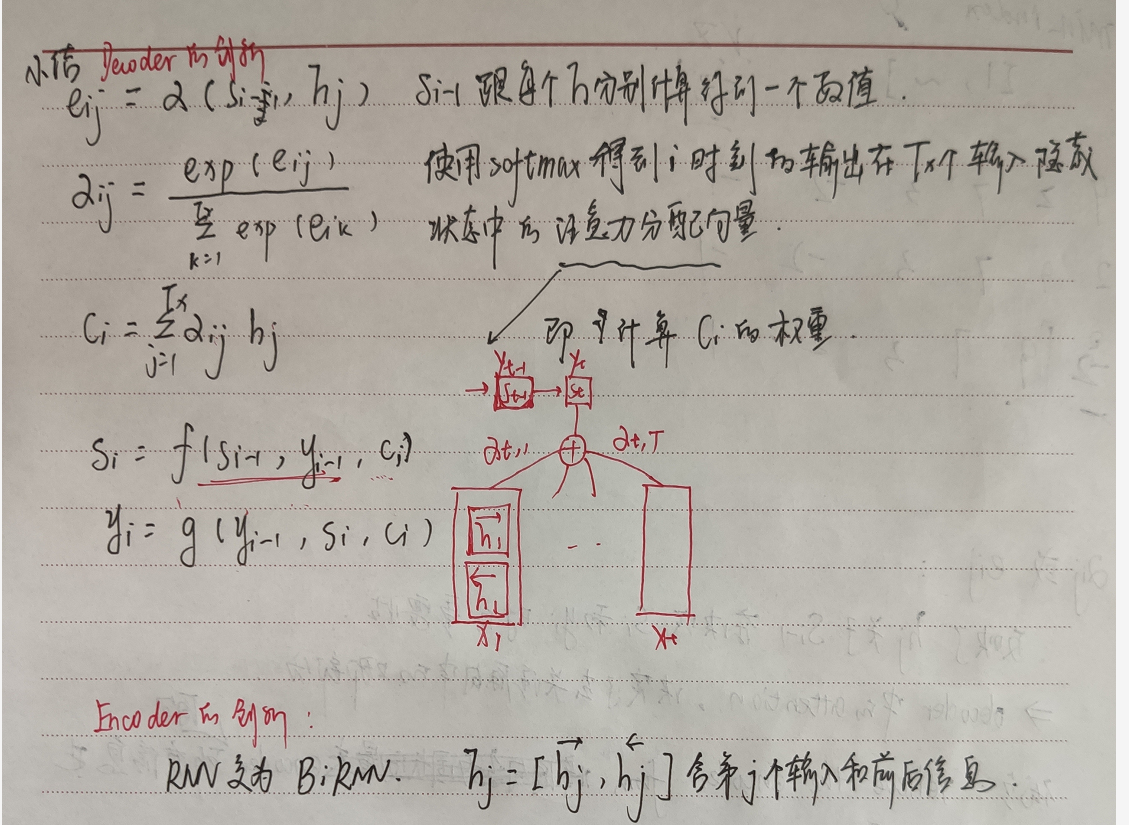
Instead, the alignment model directly computes a soft alignment, which allows the gradient of the cost function to be backpropagated through. This gradient can be used to train the alignment model as well as the whole translation model jointly


论文4
https://arxiv.org/pdf/1706.03762.pdf
Attention Is All You Need
主要介绍了transformer模型——
Transformer, a model architecture eschewing避开 recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output



2 background
sequential computation:the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions,但是transformer可以将这种操作降低在常数级
end to end memory : are based on a recurrent attention mechanism instead of sequencealigned recurrence
transduction models
重点理解:
*multihead由8个part组成,得到concate的z后再去乘以W0,使得输出的维度和embedding相同 ;再去add andnormalize
*<转>将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
--我理解的是:上面的意思只是一个特例,h即head的个数不是固定的,但是Wk、Wq、Wv的作用可以让embedding的维度分成几个部分来分别看,这也就是不同的head所做的事情
*encoder会重复6次,也就是上个encoder的输出作为下一个encoder的输入,这时候就是可以把输出的z看作第一次的embedding,那么同样要去乘以新的Wk,Wq,Wv,得到这个encoder的k、q、v
*encoder的输出z,会经过新的K、V矩阵得到k、v,decoder自身的输出可能也会经过新的Q得到q,作为decoder的第三个sub-layer,是对encoder的输入进行attention计算
*残差层意思是说,x+经过multihead后的z