[源码解析] PyTorch 分布式之弹性训练(3)---代理
0x00 摘要
在前面的文章之中,我们已经学习了PyTorch 分布式的基本模块,介绍了官方的几个例子,我们接下来会介绍PyTorch的弹性训练,本文是第三篇,看看弹性代理的基本功能。
弹性训练系列文章如下:
[源码解析] PyTorch 分布式之弹性训练(1) --- 总体思路
[源码解析] PyTorch 分布式之弹性训练(2)---启动&单节点流程
0x01 总体背景
我们先总述一下,TE 最重要的是 Agent 和 Rendezvous 这两个概念。
- Agent是运行在单节点上的独立后台进程,可以认为是 worker manager 或者 process supervisor,其负责启动worker,监控 worker 运行,捕获woker异常,通过
rendezvous实现 worker 间的相互发现,当有成员变动时候负责基于rendezvous进行变更同步。 - 为了实现弹性训练,需要有一个节点/进程之间彼此发现的机制。rendezvous就是这个发现机制或者说同步组件。当系统启动或者成员变更时候,所有worker会(重新)集合(rendezvous)以建立一个新的进程组。
1.1 功能分离
TE 是围绕在 Rendezvous 基础之上的多个elastic agent构成,这是一种功能分离,让我们对比一下看看。
- Agent 偏重具体节点上的逻辑。
- Agent 负责具体业务逻辑相关操作,比如启动进程执行用户程序,监控用户程序运行情况,如果有异常就通知 Rendezvous。
- Agent 是一个 worker manager,负责启动/管理 workers 进程,组成一个 worker group,监控 workers 运行状态,捕获失效 workers,如果有故障/新加入worker,则重启 worker group。
- Agent负责维护 WORLD_SIZE 以及 RANK 信息。用户不需要再手动提供,Agent会自动处理这些。
- Agent 是具体节点上的后台进程,是独立个体。Agent自己无法实现整体上的弹性训练,所以需要一个机制来完成 worker 之间的相互发现,变更同步等等(WORLD_SIZE 和 RANK 这些信息其实也需要多个节点同步才能确定),这就是下面的 Rendezvous 概念。
- Rendezvous 负责集群逻辑,保证节点之间对于""有哪些节点参与训练"达成强一致共识。
- 每一个 Agent 内部包括一个 Rendezvous handler,这些 handler 总体上构成了一个 Rendezvous 集群,从而构成了一个 Agent 集群。
- Rendezvous 完成之后,会创建一个共享键值存储(shared key-value store),这个store实现了一个
torch.distributed.StoreAPI。此存储仅由已完成Rendezvous的成员共享,它旨在让Torch Distributed Elastic在初始化作业过程之中交换控制和数据信息。 - Rendezvous 负责在每个agent之上维护当前 group 所有相关信息。每个 agent 之上有一个 rendezvous,它们会互相通信,总体维护一套信息,这些信息存储在上面提到的Store 之中。
- Rendezvous 负责集群逻辑相关,比如新加入节点,移除节点,分配rank等等。
我们首先从源码中取出示意图看看,大家先有一个总体概念。

1.2 Rendezvous
我们本文只是简单介绍一下 rendezvous,重点在于介绍 agent。
在 Torch Distributed Elastic 上下文之中,我们使用 rendezvous 这个术语来特指一个特定功能:一个结合了对等发现(peer discovery)的分布式同步(distributed synchronization)原语。
Rendezvous 被Torch Distributed Elastic用来收集一个训练job的参与者(节点),这样,参与者们可以商议得到参与者列表和每个参与者的角色,也可以对训练何时开始/恢复做出一致的集体决定。
Rendezvous 把功能分割解耦,业务逻辑被抽象成为一系列算子,比如 _RendevzousJoinOp。而 Rendezvous 内部维护了一套状态机,由算子决定下一步操作。比如 _RendezvousOpExecutor 来执行各种算子,依据算子结果得到下一步应该执行的 Action,从而对本身进行操作。
比如在 _DistributedRendezvousOpExecutor 之中,如果发现了当前 action 是 ADD_TO_WAIT_LIST,会执行 _add_to_wait_list,进而调用 self._state.wait_list.add(self._node)
if action == _Action.KEEP_ALIVE:
self._keep_alive()
elif action == _Action.ADD_TO_PARTICIPANTS:
self._add_to_participants()
elif action == _Action.ADD_TO_WAIT_LIST: # 发现当前Action
self._add_to_wait_list() # 然后执行
elif action == _Action.REMOVE_FROM_PARTICIPANTS:
self._remove_from_participants()
elif action == _Action.REMOVE_FROM_WAIT_LIST:
self._remove_from_wait_list()
elif action == _Action.MARK_RENDEZVOUS_COMPLETE:
self._mark_rendezvous_complete()
elif action == _Action.MARK_RENDEZVOUS_CLOSED:
self._mark_rendezvous_closed()
0x02 Agent 总体逻辑
2.1 功能
Elastic agent 是 torchelastic 的控制台(control plane),他是一个独立进程,负责启动和管理底层 worker 进程,代理具体负责:
- 与PyTorch原生分布式协同工作:使每个worker都能获得所有需要的信息,以便成功调用
torch.distributed.init_process_group()。 - 容错:监控每个worker,当出现错误或者异常时能及时终止所有worker并重启它们。
- 弹性:对成员更改作出反应,并使用新的成员来重启所有workers。
下图来自知乎,算是对上一个图的细化。
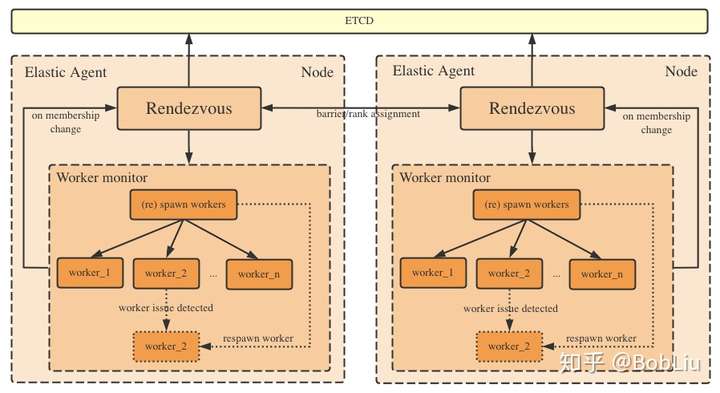
2.2 工作基础
Torchelast agent 和 用户worker 依据故障切换契约来工作:
- TE(torchelastic)希望用户worker以5分钟为误差完成工作。
- 设计DDP应用程序时,最好让所有worker都失败,而不只是一个worker失败。
- TE不会在代理之间同步重启次数。
- TE re-rendezvous不会减少重启次数。
- 当单个代理完成其工作(成功或失败)时,它将关闭rendezvous。如果其他代理仍有worker在工作,他们将被终止。
- 基于上述情况,如果至少有一个代理完成了任务,则缩容(scale down)不起作用。
- 当代理检测到Scale up时,它不会减少 "max_restarts"。
- Torchelast agent 之间通过etcd或者类似后端来保持协同工作。
2.3 部署
简单的agent部署在每个节点上,并与本地进程协同工作。更高级的agent可以远程启动和管理workers。Agent可以做到彻底的去中心化,与其他agents(管理同一个job的workers)进行沟通协调做出一个集体性决策,决策是基于其管理的 workers 情况来完成。
对于如何配置,源码中也给出了示例,如果在GPU上启动训练一个拥有 8 个 trainer(每GPU一个trainer)的 job,我们可以做如下配置。
1. Use 8 x single GPU instances, place an agent per instance, managing 1 worker per agent.
2. Use 4 x double GPU instances, place an agent per instance, managing 2 workers per agent.
3. Use 2 x quad GPU instances, place an agent per instance, managing 4 workers per agent.
4. Use 1 x 8 GPU instance, place an agent per instance, managing 8 workers per agent.
2.4 基类
基类ElasticAgent 是一个 Abstract Class,真正运行的代理都需要由此派生。从 ElasticAgent 的注释可知,代理进程负责管理一个或多个worker 进程。工作进程被假定为常规分布式PyTorch脚本。当worker进程由代理创建时,代理将为worker进程提供必要的信息,以便正确初始化torch进程组。部署时,精确的拓扑和 agent-to-worker 比率取决于代理的具体实现和用户作业放置偏好。
class ElasticAgent(abc.ABC):
"""
Agent process responsible for managing one or more worker processes.
The worker processes are assumed to be regular distributed PyTorch scripts.
When the worker process is created by the agent, the agent provides the
necessary information for the worker processes to properly initialize
a torch process group.
The exact deployment topology and ratio of agent-to-worker is dependent
on the specific implementation of the agent and the user's job placement
preferences.
Usage
::
group_result = agent.run()
if group_result.is_failed():
# workers failed
failure = group_result.failures[0]
log.exception(f"worker 0 failed with exit code : {failure.exit_code}")
else:
return group_result.return_values[0] # return rank 0's results
"""
@abc.abstractmethod
def run(self, role: str = DEFAULT_ROLE) -> RunResult:
"""
Runs the agent, retrying the worker group on failures up to
``max_restarts``.
Returns:
The result of the execution, containing the return values or
failure details for each worker mapped by the worker's global rank.
Raises:
Exception - any other failures NOT related to worker process
"""
raise NotImplementedError()
@abc.abstractmethod
def get_worker_group(self, role: str = DEFAULT_ROLE) -> WorkerGroup:
"""
Returns:
The ``WorkerGroup`` for the given ``role``.
Note that the worker group is a mutable object and hence in a
multi-threaded/process environment it may change state.
Implementors are encouraged (but not required) to return
a defensive read-only copy.
"""
raise NotImplementedError()
ElasticAgent 有两个派生类:
SimpleElasticAgent实现了基类的部分函数,其目的是为了方便扩展新代理的实现。LocalElasticAgent派生了SimpleElasticAgent,是目前弹性训练最终使用的代理,主要用于在本地进行操作,负责管理单机上所有的worker进程。
0x03 Worker
我们首先要看看 worker,这是 Agent 所管理的主体。
3.1 Worker 定义
Worker 类代表了一个worker实例,我们上文介绍了WorkerSpec,Worker 就是依据 WorkerSpec 构建出来的,其重点成员变量如下:
-
id(任意):唯一标识一个worker,具体是由ElasticAgent的特定实现来解释,对于本地代理,它可以是worker的
pid(int),对于远程代理,它可以被编码为``host:port(string)`。 -
local_rank :worker的local rank。
-
global_rank:worker的global rank。
-
role_rank:具有相同角色的所有worker的rank。
-
world_size:全局worker数量。
-
role_world_size:具有相同角色的worker数量。
class Worker:
"""
Represents a worker instance. Contrast this with ``WorkerSpec`` that
represents the specifications of a worker. A ``Worker`` is created from
a ``WorkerSpec``. A ``Worker`` is to a ``WorkerSpec`` as an object is to
a class.
The ``id`` of the worker is interpreted
by the specific implementation of ``ElasticAgent``. For a local
agent, it could be the ``pid (int)`` of the worker, for a remote
agent it could be encoded as ``host:port (string)``.
Args:
id (Any): uniquely identifies a worker (interpreted by the agent)
local_rank (int): local rank of the worker
global_rank (int): global rank of the worker
role_rank (int): rank of the worker across all workers that have the same role
world_size (int): number of workers (globally)
role_world_size (int): number of workers that have the same role
"""
def __init__(
self,
local_rank: int,
global_rank: int = -1,
role_rank: int = -1,
world_size: int = -1,
role_world_size: int = -1,
):
# unique identifier for this worker
self.id: Any = None
# rank of the worker among workers with the same role being monitored
# by the same ``agent`` instance.
self.local_rank: int = local_rank
# rank of the worker among all the workers across all roles
# across all ``agent`` instances.
# Global rank is not stable between re-rendezvous.
self.global_rank: int = global_rank
# rank of the worker among all the workers with the same role
# across all ``agent`` instances.
# Global rank is not stable between re-rendezvous.
self.role_rank: int = role_rank
# total number of workers (globally). Due to elasticity
# the world size may change between re-rendezvous.
self.world_size: int = world_size
# total number of workers that share the same role. Due to elasticity
# the role world size may change between re-rendezvous.
self.role_world_size: int = role_world_size
3.2 WorkerGroup
WorkerGroup 代表了一个工作组,作为一个整体来管理多个 workers,进行批量处理。
class WorkerGroup:
"""
Represents the set of ``Worker`` instances for the given ``WorkerSpec``
managed by ``ElasticAgent``. Whether the worker group contains cross
instance workers or not depends on the implementation of the agent.
"""
def __init__(self, spec: WorkerSpec):
self.spec = spec
self.workers = [Worker(local_rank=i) for i in range(self.spec.local_world_size)]
# assigned after rdzv
self.store = None
self.group_rank = None
self.group_world_size = None
self.state = WorkerState.INIT
在SimpleElasticAgent 初始化之中,会建立一个 WorkerGroup。
class SimpleElasticAgent(ElasticAgent):
"""
An ``ElasticAgent`` that manages workers (``WorkerGroup``)
for a single ``WorkerSpec`` (e.g. one particular type of worker role).
"""
def __init__(self, spec: WorkerSpec, exit_barrier_timeout: float = 300):
self._worker_group = WorkerGroup(spec)
self._remaining_restarts = self._worker_group.spec.max_restarts
self._store = None
self._exit_barrier_timeout = exit_barrier_timeout
self._total_execution_time = 0
3.3 WorkerState
WorkerState 表示 WorkerGroup的状态。工作组中的所有工作人员作为一个整体来维护/更改状态。如果工作组中的一个worker失败,则整个工作组被认为是失败:
UNKNOWN - agent lost track of worker group state, unrecoverable
INIT - worker group object created not yet started
HEALTHY - workers running and healthy
UNHEALTHY - workers running and unhealthy
STOPPED - workers stopped (interruped) by the agent
SUCCEEDED - workers finished running (exit 0)
FAILED - workers failed to successfully finish (exit !0)
具体这些状态意义如下:
-
UNKNOWN-代理丢失了对工作组状态的跟踪,无法恢复
-
INIT-创建的工作组对象尚未启动
-
HEALTHY-worker健康运行
-
UNHEALTHY-worker在运行但是不健康
-
STOPPED-代理停止(中断)worker
-
SUCCEEDED-worker已完成运行(exit数值为0)
-
FAILED-worker未能成功完成(exit数值不等于0)
工作组从初始的INIT状态开始,然后进入"健康"或"不健康"状态,最后到达终端"成功"或"失败"状态。工作组可以被代理打断并且临时置于"停止"状态。处于"已停止"状态的工作进程可以在不久的将来被调度重启,被设置为已停止的状态的例子为:
- 观察到工作组故障|不健康
- 检测到成员更改
当工作组上的操作(启动、停止、rdzv、重试等)失败,并导致操作部分应用于工作组时,状态将为"未知"。这通常发生在状态改变期间发生异常,而且异常未捕获/未处理的情况下。当工作组处于"未知"状态,代理不会恢复工作组,因此最好终止作业,并且由job manager重试节点。
WorkerState 具体定义如下:
class WorkerState(str, Enum):
"""
State of the ``WorkerGroup``. Workers in a worker group change state as a unit.
If a single worker in a worker group fails the entire set is considered
failed::
UNKNOWN - agent lost track of worker group state, unrecoverable
INIT - worker group object created not yet started
HEALTHY - workers running and healthy
UNHEALTHY - workers running and unhealthy
STOPPED - workers stopped (interruped) by the agent
SUCCEEDED - workers finished running (exit 0)
FAILED - workers failed to successfully finish (exit !0)
A worker group starts from an initial ``INIT`` state,
then progresses to ``HEALTHY`` or ``UNHEALTHY`` states,
and finally reaches a terminal ``SUCCEEDED`` or ``FAILED`` state.
Worker groups can be interrupted and temporarily put into ``STOPPED`` state
by the agent. Workers in ``STOPPED`` state are scheduled to be restarted
in the near future by the agent. Some examples of workers being put into
``STOPPED`` state are:
1. Worker group failure|unhealthy observed
2. Membership change detected
When actions (start, stop, rdzv, retry, etc) on worker group fails
and results in the action being partially applied to the worker group
the state will be ``UNKNOWN``. Typically this happens on uncaught/unhandled
exceptions during state change events on the agent. The agent is not
expected to recover worker groups in ``UNKNOWN`` state and is better off
self terminating and allowing the job manager to retry the node.
"""
UNKNOWN = "UNKNOWN"
INIT = "INIT"
HEALTHY = "HEALTHY"
UNHEALTHY = "UNHEALTHY"
STOPPED = "STOPPED"
SUCCEEDED = "SUCCEEDED"
FAILED = "FAILED"
@staticmethod
def is_running(state: "WorkerState") -> bool:
"""
Returns:
True if the worker state represents workers still running
(e.g. that the process exists but not necessarily healthy).
"""
return state in {WorkerState.HEALTHY, WorkerState.UNHEALTHY}
0x04 SimpleElasticAgent
SimpleElasticAgent 是 Agent 的实现类之一。此抽象是为了方便扩展新的 agent 实现。从后面可知,目前内置的 LocalElasticAgent 负责管理单机上的所有 worker 进程,如果用户希望只用一个代理就管理多机上所有的 worker,而不仅仅是本机 worker,那么可以通过扩展 SimpleElasticAgent 来实现一个自定义 Agent。
class SimpleElasticAgent(ElasticAgent):
"""
An ``ElasticAgent`` that manages workers (``WorkerGroup``)
for a single ``WorkerSpec`` (e.g. one particular type of worker role).
"""
def __init__(self, spec: WorkerSpec, exit_barrier_timeout: float = 300):
self._worker_group = WorkerGroup(spec)
self._remaining_restarts = self._worker_group.spec.max_restarts
self._store = None
self._exit_barrier_timeout = exit_barrier_timeout
self._total_execution_time = 0
4.1 总体运行
SimpleElasticAgent 主循环 _invoke_run 是核心逻辑(这里默认代理和worker在同一个机器之上),其中做如下操作:
- 使用
self._initialize_workers(self._worker_group)完成初始化工作,比如来启动 worker,为每个worker 分配 rank 等等。 - 然后进入 while True 循环,在循环之中通过 _monitor_workers 定期轮训用户程序运行情况,得到 worker 进程运行结果,然后依据情况进行不同处理。
- 如果程序正常结束,则返回。
- 如果程序出错,则重试,如果重试次数达到,结束workers。
- 如果节点成员关系有变化,比如scale up就会有新的节点在waiting,这时候就重启所有workers。
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
# NOTE: currently only works for a single role
spec = self._worker_group.spec
role = spec.role
self._initialize_workers(self._worker_group) # 启动worker
monitor_interval = spec.monitor_interval
rdzv_handler = spec.rdzv_handler
while True:
assert self._worker_group.state != WorkerState.INIT
# 定期监控
time.sleep(monitor_interval)
# 监控客户程序运行情况
run_result = self._monitor_workers(self._worker_group) # 得到进程运行结果
state = run_result.state
self._worker_group.state = state
put_metric(f"workers.{role}.remaining_restarts", self._remaining_restarts)
put_metric(f"workers.{role}.{state.name.lower()}", 1)
if state == WorkerState.SUCCEEDED:
# 程序正常结束
self._exit_barrier()
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
# 程序出错
if self._remaining_restarts > 0: # 重试
self._remaining_restarts -= 1
self._restart_workers(self._worker_group)
else:
self._stop_workers(self._worker_group) # 重试次数达到,结束workers
self._worker_group.state = WorkerState.FAILED
self._exit_barrier()
return run_result
elif state == WorkerState.HEALTHY:
# 节点成员关系有变化,比如scale up,就会有新节点waiting
# membership changes do not count as retries
num_nodes_waiting = rdzv_handler.num_nodes_waiting()
group_rank = self._worker_group.group_rank
# 如果有新的节点在waiting,就重启所有workers
if num_nodes_waiting > 0:
self._restart_workers(self._worker_group)
else:
raise Exception(f"[{role}] Worker group in {state.name} state")
上面只是大概讲了下这个总体流程,我们接下来对这个总体流程逐一分析。
4.2 初始化workers
代理主循环之中,首先使用 self._initialize_workers(self._worker_group) 来启动 worker。在 _initialize_workers之中:
- 首先使用
self._rendezvous(worker_group)进行节点之间的同步共识操作以及rank处理等等。 - 其次调用
_start_workers启动 workers。这里的_start_workers是虚函数,需要派生类实现。
@prof
def _initialize_workers(self, worker_group: WorkerGroup) -> None:
r"""
Starts a fresh set of workers for the worker_group.
Essentially a rendezvous followed by a start_workers.
The caller should first call ``_stop_workers()`` to stop running workers
prior to calling this method.
Optimistically sets the state of the worker group that
just started as ``HEALTHY`` and delegates the actual monitoring
of state to ``_monitor_workers()`` method
"""
role = worker_group.spec.role
# TODO after stopping workers, wait at least monitor_interval*2 for
# workers on different nodes to fail on a collective op before waiting
# on the rdzv barrier, this way we ensure that nodes enter rdzv
# at around the same time and reduce false positive rdzv timeout errors
self._rendezvous(worker_group) # 同步共识操作
worker_ids = self._start_workers(worker_group) # 启动worker
for local_rank, w_id in worker_ids.items():
worker = worker_group.workers[local_rank]
worker.id = w_id
worker_group.state = WorkerState.HEALTHY
4.2.1 _rendezvous
我们首先看看_rendezvous,其做如下操作:
- 调用 next_rendezvous() 来处理成员关系变化,其会返回 world size,store等。
- 会把 store 配置到 workgroup 之中,后续worker 之间就可以通过这个kvstore进行沟通。
- 调用 _assign_worker_ranks 会生成 worker,并且为 worker 建立 ranks,返回的 workers 都赋值在代理的 worker_group.workers 之中。
以上两点都是利用 rendezvous 的信息来进行处理,比如从 rendezvous 之中提取 ranks。
@prof
def _rendezvous(self, worker_group: WorkerGroup) -> None:
r"""
Runs rendezvous for the workers specified by worker spec.
Assigns workers a new global rank and world size.
Updates the rendezvous store for the worker group.
"""
spec = worker_group.spec
# 处理成员关系变化,注意,这里得到的是 group rank!
store, group_rank, group_world_size = spec.rdzv_handler.next_rendezvous()
self._store = store # store被设置到 Agent之中,store可以被认为是远端KV存储
# 依据 group rank 为 worker 建立 ranks
workers = self._assign_worker_ranks(store, group_rank, group_world_size, spec)
worker_group.workers = workers
worker_group.store = store
worker_group.group_rank = group_rank
worker_group.group_world_size = group_world_size
if group_rank == 0:
self._set_master_addr_port(store, spec.master_addr, spec.master_port)
master_addr, master_port = self._get_master_addr_port(store)
restart_count = spec.max_restarts - self._remaining_restarts
4.2.2.1 处理成员关系变化
Elastic 调用 rdzv_handler.next_rendezvous() 来处理成员关系变化,目的是启动下一轮 rendezvous 操作(因为本worker已经启动,需要加入集群)。
注意,next_rendezvous 是 RendezvousHandler 的内部函数。这一函数调用会被阻塞,直到 worker 的数量达到了要求。在 worker 被初始化,或者重启的时候,这一函数都会被调用。当函数返回时,不同的 worker group 会以返回中的 rank 作为唯一的标示。其内部逻辑是:
- 先使用
_RendezvousExitOp让该node退出。 - 然后再使用
_RendezvousJoinOp把该node重新加入。 - 最后启动心跳,返回world size,store等。
def next_rendezvous(self) -> Tuple[Store, int, int]:
"""See base class."""
self._stop_heartbeats()
# Delay the execution for a small random amount of time if this is our
# first run. This will slightly skew the rendezvous attempts across the
# nodes and reduce the load on the backend.
if self._state_holder.state.round == 0:
_delay(seconds=(0, 0.3))
exit_op = _RendezvousExitOp()
join_op = _RendezvousJoinOp()
deadline = self._get_deadline(self._settings.timeout.join)
self._op_executor.run(exit_op, deadline)
self._op_executor.run(join_op, deadline)
self._start_heartbeats()
rank, world_size = self._get_world()
store = self._get_store()
return store, rank, world_size # 返回的是 worker group 的rank
4.2.3.2 为 worker 分配 ranks
接着是调用 _assign_worker_ranks 为 worker 建立 ranks。分配 rank 算法如下:
- 每个代理将其配置(group_rank, group_world_size , num_workers)写入公共存储。
- 每个代理检索所有代理的配置,并使用角色和rank执行两级排序。
- 确定全局rank:当前代理的global rank是 本代理 的 group_rank 在infos数组的偏移量(offset)。偏移量的计算方法是,排名低于group_rank的所有代理的local_world之和。workers 的等级为:[offset, offset+local_world_size]。
- 确定role rank:使用第3点中的算法确定role rank,不同之处是:偏移量计算是从与当前角色相同且具有最小 group rank 的第一个代理开始。
- 因为所有代理都使用同样算法,所以其计算出的 ranks 数组都是相同的。
然后生成 workers,把 worker 都赋值在 worker_group.workers 之中。
@prof
def _assign_worker_ranks(
self, store, group_rank: int, group_world_size: int, spec: WorkerSpec
) -> List[Worker]:
"""
Determines proper ranks for worker processes. The rank assignment
is done according to the following algorithm:
1. Each agent writes its configuration(group_rank, group_world_size
, num_workers) to the common store.
2. Each agent retrieves configuration for all agents
and performs two level sort using role and rank.
3. Determine the global rank: the global rank of the workers for the current
agent is the offset of the infos array up to group_rank of the agent.
The offset is computed as a sum of local_world_size of all agents that
have rank less than the group_rank. The workers would have the ranks:
[offset, offset+local_world_size)
4. Determine the role rank: The role rank is determined using the algorithms
in the point 3 with the exception that the offset is done from the first
agent that has the same role as current one and has the minimum group rank.
"""
# 每个代理将其配置(group_rank, group_world_size, num_workers)写入公共存储。
role_infos = self._share_and_gather(store, group_rank, group_world_size, spec)
# 每个代理检索所有代理的配置,并使用角色和rank执行两级排序。
my_role_info = role_infos[group_rank]
# 确定全局rank:当前代理的global rank是 本代理 的 group_rank 在infos数组的偏移量(offset)。偏移量的计算方法是,排名低于group_rank的所有代理的local_world之和。workers 的等级为:[offset, offset+local_world_size]。
worker_world_size, worker_global_ranks = self._get_ranks(role_infos, group_rank)
role_infos = sorted(
role_infos, key=functools.cmp_to_key(_RoleInstanceInfo.compare)
)
role_start_idx, role_end_idx = _RoleInstanceInfo.find_role_boundaries(
role_infos, my_role_info.role
)
role_pos = next(
idx
for idx, role_info in enumerate(role_infos)
if _RoleInstanceInfo.compare(role_info, my_role_info) == 0
)
# 确定role rank:使用第3点中的算法确定role rank,不同之处是:偏移量计算是从与当前角色相同且具有最小 group rank 的第一个代理开始。
role_world_size, role_ranks = self._get_ranks(
role_infos, role_pos, role_start_idx, role_end_idx + 1
)
# 生成 workers,把 worker 都赋值在 worker_group.workers 之中。
workers = []
for ind in range(spec.local_world_size):
worker = Worker(
local_rank=ind,
global_rank=worker_global_ranks[ind],
role_rank=role_ranks[ind],
world_size=worker_world_size,
role_world_size=role_world_size,
)
workers.append(worker)
return workers
4.2.4 启动 workers 进程
调用 派生类的 _start_workers 来启动 worker 进程,因此基类这里没有实现,我们后续会看到派生类如何实现。
@abc.abstractmethod
def _start_workers(self, worker_group: WorkerGroup) -> Dict[int, Any]:
r"""
Starts ``worker_group.spec.local_world_size`` number of workers
according to worker spec for the worker group .
Returns a map of ``local_rank`` to worker ``id``.
"""
raise NotImplementedError()
目前逻辑如下,具体是:
- 调用 rdzv_handler.next_rendezvous 来与其他 Node 进行同步。
- rdzv_handler.next_rendezvous 返回 ranks 等信息给_assign_worker_ranks。
- _assign_worker_ranks会生成一些Workers,其中每个 Worker都被自动分配了 rank。这些 workers 被 Agent的worker_group.workers所指向。
+--------------------------------------------------+
| LocalElasticAgent | _initialize_workers
| | +
| | |
| | |
| +----------------------+ | v
| |WorkerGroup | | _rendezvous(worker_group)
| | | | +
| | spec | | |
| | | | | 1
| | group_world_size | | v
| | | | rdzv_handler.next_rendezvous()
| | store | | +
| | | +----------------+ | |
| | group_rank | | Worker0(rank 0)| | 2 | ranks
| | | | Worker1(rank 1)| | Workers v
| | workers +----------> | ... | | <----+ _assign_worker_ranks
| | | | Workern(rank n)| | 3
| +----------------------+ +----------------+ |
| |
+--------------------------------------------------+
接下来会分别把 rank 相关和 worker 相关的函数都分别罗列出来,以便大家更好的理解。
4.3 ranks相关
前面的 _assign_worker_ranks 为 worker 建立 ranks,但是其内部有些细节我们还需要梳理一下。
4.3.1 _RoleInstanceInfo
这里要介绍一下 _RoleInstanceInfo 这个数据结构。代理使用该类与其他代理交换信息。该信息用于确定本代理workers的rank。这些代理工作在异构环境下,不同代理也许有不同数量的workers。其构建参数是:
- role (str) : 用户定义的role。
- rank (int) : 代理的rank。
- local_world_size (int) : 本地 workers 的数目。
class _RoleInstanceInfo:
"""
The class is used by the agent to exchange the information with other agents.
The information is used to determine the rank of the workers that agent
manages in heterogeneous environments, where different agents can have
different number of workers.
"""
__slots__ = ["role", "rank", "local_world_size"]
def __init__(self, role: str, rank: int, local_world_size: int):
r"""
Args:
role (str): user-defined role for the workers with this spec
rank (int): the rank of the agent
local_world_size (int): number of local workers to run
"""
self.role = role
self.rank = rank
self.local_world_size = local_world_size
def serialize(self) -> bytes:
dict_data = {
"role": self.role,
"rank": self.rank,
"local_world_size": self.local_world_size,
}
return json.dumps(dict_data).encode(encoding="UTF-8")
@staticmethod
def deserialize(data: bytes):
dict_data = json.loads(data.decode(encoding="UTF-8"))
return _RoleInstanceInfo(
dict_data["role"], dict_data["rank"], dict_data["local_world_size"]
)
@staticmethod
def compare(obj1, obj2) -> int:
if obj1.role == obj2.role:
return obj1.rank - obj2.rank
elif obj1.role > obj2.role:
return 1
else:
return -1
@staticmethod
def find_role_boundaries(roles_infos: List, role: str) -> Tuple[int, int]:
start_idx, end_idx = -1, -1
for idx, role_info in enumerate(roles_infos):
if role_info.role == role:
if start_idx == -1:
start_idx = idx
end_idx = idx
return (start_idx, end_idx)
4.3.2 _share_and_gather
_share_and_gather 的作用是在各个代理之间同步,得到角色的总体信息。每个代理将其配置(group_rank, group_world_size , num_workers)写入公共存储。这里就是使用之前 Rendezvous 返回的 store 来进行信息共享。
def _share_and_gather(
self, store, group_rank: int, group_world_size: int, spec: WorkerSpec
) -> List:
agent_role_info = _RoleInstanceInfo(
spec.role, group_rank, spec.local_world_size
)
key_prefix = "torchelastic/role_info"
agent_config_enc = agent_role_info.serialize()
role_infos_bytes = store_util.synchronize(
store, agent_config_enc, group_rank, group_world_size, key_prefix
)
role_infos = [
_RoleInstanceInfo.deserialize(role_info_bytes)
for role_info_bytes in role_infos_bytes
]
return role_infos
4.3.3 _get_ranks
依据 role infos 来确定全局rank:当前代理的global rank是 本代理 的 group_rank 在infos数组的偏移量(offset)。偏移量的计算方法是,排名低于group_rank的所有代理的local_world之和。workers 的等级为:[offset, offset+local_world_size]。
def _get_ranks(
self,
role_infos: List[_RoleInstanceInfo],
role_idx: int,
start_idx: int = 0,
end_idx: int = -1,
) -> Tuple[int, List[int]]:
if end_idx == -1:
end_idx = len(role_infos)
prefix_sum = 0
total_sum = 0
for idx in range(start_idx, end_idx):
if role_idx > idx:
prefix_sum += role_infos[idx].local_world_size
total_sum += role_infos[idx].local_world_size
return (
total_sum,
list(range(prefix_sum, prefix_sum + role_infos[role_idx].local_world_size)),
)
目前逻辑拓展如下:
- 调用 rdzv_handler.next_rendezvous() 来和其他节点进行同步,获得信息。
- 获得信息中的store(可以认为就是远端的KV存储),group_world_size,group_rank 传给 Agent。
- ranks 等信息传给 _assign_worker_ranks方法。
- _assign_worker_ranks 之中,调用 _share_and_gather 在各个代理之间同步,得到角色的总体信息。每个代理将其配置(group_rank, group_world_size , num_workers)写入公共KV存储。
- 依据 role infos 来确定全局rank:当前代理的global rank是 本代理 的 group_rank 在infos数组的偏移量(offset)。偏移量的计算方法是,排名低于group_rank的所有代理的local_world之和。
- 使用各种信息建立一系列的 Workers。
- Workers 被复制给 Agent 的 WorkerGroup 之中。
_initialize_workers
+
|
|
v
_rendezvous(worker_group)
+
+----------------------------------------------+ |
| LocalElasticAgent | | 1
| | 2 v
| +--------------+ rdzv_handler.next_rendezvous()
| +--------------------+ | | +
| | WorkerGroup | | | |
| | | | | 3 | ranks
| | | | | v
| | spec | | | +--------------+------------------+
| | | | | | _assign_worker_ranks |
| | | | | | |
| | store <----------------------------+ | | 4 |
| | | | | | role_infos = _share_and_gather( |
| | | | | | + store) |
| | group_world_size<--------------------+ | | | 5 |
| | | | | | | |
| | | | | | v |
| | group_rank <-------------------------+ | | _get_ranks(world...) |
| | | | | _get_ranks(role...) |
| | | +----------------+ | | + |
| | workers +----------->+ Worker0(rank 0)| | | | |
| | | | Worker1(rank 1)| | | | 6 |
| | | | ... | |Workers| v |
| | | | Workern(rank n)+<------------+ new Worker(local_rank, |
| +--------------------+ +----------------+ | 7 | global_rank, |
| | | role_rank, |
+----------------------------------------------+ | world_size, |
| role_world_size) |
| |
+---------------------------------+
_rendezvous 操作之后,Worker 实例已经生成了,接下来就看看如何生成 Worker 进程。但是因为这些方法在 SimpleElasticAgent 之中并没有实现,所以我们需要在其派生类 LocalElasticAgent 分析小节才能继续拓展我们的逻辑图。
4.4 Worker 相关
我们先看看 SimpleElasticAgent 剩余两个 worker 相关函数。
4.4.1 重启
_restart_workers 是重启 workers。
# pyre-fixme[56]: Pyre was not able to infer the type of the decorator
# `torch.distributed.elastic.metrics.prof`.
@prof
def _restart_workers(self, worker_group: WorkerGroup) -> None:
"""
Restarts (stops, rendezvous, starts) all local workers in the group.
"""
role = worker_group.spec.role
self._stop_workers(worker_group)
worker_group.state = WorkerState.STOPPED
self._initialize_workers(worker_group)
4.4.2 barrier
实际上,几乎不可能保证DDP的所有 worker 都能保证同时结束,所以因此TE提供了一个finalization barrier,这个barrier的作用是对worker finalization 实施等待超时(5分钟)。
def _exit_barrier(self):
"""
Wait for ``exit_barrier_timeout`` seconds for all agents to finish
executing their local workers (either successfully or not). This
acts as a safety guard against user scripts that terminate at different
times. This barrier keeps the agent process alive until all workers finish.
"""
start = time.time()
try:
store_util.barrier(
self._store,
self._worker_group.group_rank,
self._worker_group.group_world_size,
key_prefix=_TERMINAL_STATE_SYNC_ID,
barrier_timeout=self._exit_barrier_timeout,
)
except Exception:
log.exception(
f"Error waiting on exit barrier. Elapsed: {time.time() - start} seconds"
)
0x05 LocalElasticAgent
LocalElasticAgent 是弹性训练最终使用的代理,主要用于在本地进行操作,负责管理单机上所有的worker进程,其派生了 SimpleElasticAgent。
此代理在每个主机之上部署,并配置为生成n个工作进程。当使用GPU时,n是主机上可用的GPU数量。本地代理不会与部署在其他主机上的其他本地代理通信,即使worker可以在主机间通信。Worker id被解释为本地进程。代理作为把本机所有工作进程作为一个整体启动和停止。
传递给worker的函数和参数必须与python multiprocessing兼容。要将multiprocessing数据结构传递给worker,用户可以在与指定的start_method相同的多处理multiprocessing中创建数据结构,并将其作为函数参数传递。
exit_barrier_timeout用来指定等待其他代理完成的时间量(以秒为单位)。这起到了一个安全网的作用,可以处理worker在不同时间完成的情况,以防止代理将提前完成的worker视为scale-down事件。强烈建议用户代码确保worker以同步方式终止,而不是依赖于exit_barrier_timeout。
SimpleElasticAgent 主要是提供给了初始化和总体运行方式,但是遗留了一些抽象函数没有被实现,比如_start_workers,_stop_workers,_monitor_workers,_shutdown。LocalElasticAgent 就补齐了这些函数。
class LocalElasticAgent(SimpleElasticAgent):
"""
An implementation of :py:class:`torchelastic.agent.server.ElasticAgent`
that handles host-local workers.
This agent is deployed per host and is configured to spawn ``n`` workers.
When using GPUs, ``n`` maps to the number of GPUs available on the host.
The local agent does not communicate to other local agents deployed on
other hosts, even if the workers may communicate inter-host. The worker id
is interpreted to be a local process. The agent starts and stops all worker
processes as a single unit.
The worker function and argument passed to the worker function must be
python multiprocessing compatible. To pass multiprocessing data structures
to the workers you may create the data structure in the same multiprocessing
context as the specified ``start_method`` and pass it as a function argument.
The ``exit_barrier_timeout`` specifies the amount of time (in seconds) to wait
for other agents to finish. This acts as a safety net to handle cases where
workers finish at different times, to prevent agents from viewing workers
that finished early as a scale-down event. It is strongly advised that the
user code deal with ensuring that workers are terminated in a synchronous
manner rather than relying on the exit_barrier_timeout.
"""
def __init__(
self,
spec: WorkerSpec,
start_method="spawn",
exit_barrier_timeout: float = 300,
log_dir: Optional[str] = None,
):
super().__init__(spec, exit_barrier_timeout)
self._start_method = start_method
self._pcontext: Optional[PContext] = None
rdzv_run_id = spec.rdzv_handler.get_run_id()
self._log_dir = self._make_log_dir(log_dir, rdzv_run_id)
def _make_log_dir(self, log_dir: Optional[str], rdzv_run_id: str):
base_log_dir = log_dir or tempfile.mkdtemp(prefix="torchelastic_")
os.makedirs(base_log_dir, exist_ok=True)
dir = tempfile.mkdtemp(prefix=f"{rdzv_run_id}_", dir=base_log_dir)
return dir
5.1 使用
我们先从其注释中提取代码,看看如何使用。以下是如何把function作为入口来启动。
def trainer(args) -> str:
return "do train"
def main():
start_method="spawn"
shared_queue= multiprocessing.get_context(start_method).Queue()
spec = WorkerSpec(
role="trainer",
local_world_size=nproc_per_process,
entrypoint=trainer,
args=("foobar",),
...<OTHER_PARAMS...>)
agent = LocalElasticAgent(spec, start_method)
results = agent.run()
if results.is_failed():
print("trainer failed")
else:
print(f"rank 0 return value: {results.return_values[0]}")
# prints -> rank 0 return value: do train
以下是如何把binary作为入口来启动。
def main():
spec = WorkerSpec(
role="trainer",
local_world_size=nproc_per_process,
entrypoint="/usr/local/bin/trainer",
args=("--trainer_args", "foobar"),
...<OTHER_PARAMS...>)
agent = LocalElasticAgent(spec)
results = agent.run()
if not results.is_failed():
print("binary launches do not have return values")
_rendezvous 操作之后,Worker 实例已经生成了,接下来就看看如何生成 Worker 进程。
5.2 停止
以下函数会停止workers。
@prof
def _stop_workers(self, worker_group: WorkerGroup) -> None:
self._shutdown()
def _shutdown(self) -> None:
if self._pcontext:
self._pcontext.close()
5.3 初始化
我们接着前文来说,_rendezvous 操作之后,Worker 实例已经生成了,接下来就看看如何生成 Worker 进程。之前因为这些方法在 SimpleElasticAgent 之中并没有实现,所以我们在本小结继续拓展我们的逻辑图。
我们先再看看初始化workers。在 _initialize_workers之中,首先使用 _rendezvous 建立 workers 实例,其次调用 _start_workers 启动 workers。
@prof
def _initialize_workers(self, worker_group: WorkerGroup) -> None:
r"""
Starts a fresh set of workers for the worker_group.
Essentially a rendezvous followed by a start_workers.
The caller should first call ``_stop_workers()`` to stop running workers
prior to calling this method.
Optimistically sets the state of the worker group that
just started as ``HEALTHY`` and delegates the actual monitoring
of state to ``_monitor_workers()`` method
"""
role = worker_group.spec.role
# TODO after stopping workers, wait at least monitor_interval*2 for
# workers on different nodes to fail on a collective op before waiting
# on the rdzv barrier, this way we ensure that nodes enter rdzv
# at around the same time and reduce false positive rdzv timeout errors
self._rendezvous(worker_group) # Worker实例已经生成了
worker_ids = self._start_workers(worker_group) # 启动Worker进程
for local_rank, w_id in worker_ids.items():
worker = worker_group.workers[local_rank]
worker.id = w_id # 得到进程ID
worker_group.state = WorkerState.HEALTHY
5.4 启动 worker 进程
_start_workers 方法会调用 start_processes 来启动 worker 进程,默认_start_method 是 "spawn"。也就是启动了多个进程,并行执行用户程序。同时这些进程的运行结果会被监控。start_processes 参数之中,entrypoint和args 是用户命令和参数,entrypoint可以是函数或者字符串。
_start_workers 把 start_processes 方法启动多线程的结果保存在 _pcontext 之中,后续就用 _pcontext 来继续控制,比如结束 worker 就是直接调用 _pcontext 的 close方法。
@prof
def _start_workers(self, worker_group: WorkerGroup) -> Dict[int, Any]:
spec = worker_group.spec
store = worker_group.store
assert store is not None
master_addr, master_port = super()._get_master_addr_port(store)
restart_count = spec.max_restarts - self._remaining_restarts
use_agent_store = spec.rdzv_handler.get_backend() == "static"
args: Dict[int, Tuple] = {}
envs: Dict[int, Dict[str, str]] = {}
for worker in worker_group.workers:
local_rank = worker.local_rank
worker_env = {
"LOCAL_RANK": str(local_rank),
"RANK": str(worker.global_rank),
"GROUP_RANK": str(worker_group.group_rank),
"ROLE_RANK": str(worker.role_rank),
"ROLE_NAME": spec.role,
"LOCAL_WORLD_SIZE": str(spec.local_world_size),
"WORLD_SIZE": str(worker.world_size),
"GROUP_WORLD_SIZE": str(worker_group.group_world_size),
"ROLE_WORLD_SIZE": str(worker.role_world_size),
"MASTER_ADDR": master_addr,
"MASTER_PORT": str(master_port),
"TORCHELASTIC_RESTART_COUNT": str(restart_count),
"TORCHELASTIC_MAX_RESTARTS": str(spec.max_restarts),
"TORCHELASTIC_RUN_ID": spec.rdzv_handler.get_run_id(),
"TORCHELASTIC_USE_AGENT_STORE": str(use_agent_store),
"NCCL_ASYNC_ERROR_HANDLING": str(1),
}
if "OMP_NUM_THREADS" in os.environ:
worker_env["OMP_NUM_THREADS"] = os.environ["OMP_NUM_THREADS"]
envs[local_rank] = worker_env
worker_args = list(spec.args)
worker_args = macros.substitute(worker_args, str(local_rank))
args[local_rank] = tuple(worker_args)
# scaling events do not count towards restarts (gets same attempt #)
# remove existing log dir if this restart is due to a scaling event
attempt_log_dir = os.path.join(self._log_dir, f"attempt_{restart_count}")
shutil.rmtree(attempt_log_dir, ignore_errors=True)
os.makedirs(attempt_log_dir)
self._pcontext = start_processes( # 把启动多线程的结果保存在 _pcontext 之中。
name=spec.role,
entrypoint=spec.entrypoint,
args=args,
envs=envs,
log_dir=attempt_log_dir,
start_method=self._start_method,
redirects=spec.redirects,
tee=spec.tee,
)
return self._pcontext.pids()
5.5 监控
运行之后,TE 会调用 _monitor_workers 对workers进行监控。之前把启动多线程的结果保存在 _pcontext 之中,现在就用 _pcontext 对运行情况进行监控。
@prof
def _monitor_workers(self, worker_group: WorkerGroup) -> RunResult:
role = worker_group.spec.role
worker_pids = {w.id for w in worker_group.workers}
assert self._pcontext is not None
pc_pids = set(self._pcontext.pids().values())
if worker_pids != pc_pids:
return RunResult(state=WorkerState.UNKNOWN)
result = self._pcontext.wait(0) # 对运行结构进行监控
if result:
if result.is_failed(): # 如果进程失败
# map local rank failure to global rank
worker_failures = {}
# 返回的结果内部就包括每个进程的运行结果
for local_rank, failure in result.failures.items():
worker = worker_group.workers[local_rank]
worker_failures[worker.global_rank] = failure
return RunResult(
state=WorkerState.FAILED,
failures=worker_failures, # 返回运行结果
)
else:
# copy ret_val_queue into a map with a global ranks
workers_ret_vals = {}
for local_rank, ret_val in result.return_values.items():
worker = worker_group.workers[local_rank]
workers_ret_vals[worker.global_rank] = ret_val
return RunResult(
state=WorkerState.SUCCEEDED,
return_values=workers_ret_vals, # 返回运行结果
)
else:
return RunResult(state=WorkerState.HEALTHY)
因为启动和监控涉及到系统整体运行逻辑,需要和 rendezvous 一起才能更好理解,所以我们把这部分的分析推迟,等到 Rendezvous 之后再来做整体分析。
目前总体逻辑如下:
- 调用 rdzv_handler.next_rendezvous() 来和其他节点进行同步,获得信息。
- 获得信息中的store(可以认为就是远端的KV存储),group_world_size,group_rank 传给 Agent。
- ranks 等信息传给 _assign_worker_ranks方法。
- _assign_worker_ranks 之中,调用 _share_and_gather 在各个代理之间同步,得到角色的总体信息。每个代理将其配置(group_rank, group_world_size , num_workers)写入公共KV存储。
- 依据 role infos 来确定全局rank:当前代理的global rank是 本代理 的 group_rank 在infos数组的偏移量(offset)。偏移量的计算方法是,排名低于group_rank的所有代理的local_world之和。
- 使用各种信息建立一系列的 Workers。
- Workers 被复制给 Agent 的 WorkerGroup 之中。
- 使用 _start_workers 来启动 worker 进程。
- 把 worker 进程 id 赋值给 Agent 的 worker.id 之中,这样以后就可以用 worker.id 来操作进程。
- 使用 _monitor_workers 监控 worker 进程。
- 使用 _exit_barrier 来等待 worker 进程结束。
_initialize_workers
+
|
|
v
_rendezvous(worker_group)
+
+----------------------------------------------+ |
| LocalElasticAgent | | 1
| | 2 v
| +--------------+ rdzv_handler.next_rendezvous()
| +--------------------+ | | +
| | WorkerGroup | | | |
| | | | | 3 | ranks
| | | | | v
| | spec | | | +--------------+------------------+
| | | | | | _assign_worker_ranks |
| | | | | | |
| | store <----------------------------+ | | 4 |
| | | | | | role_infos = _share_and_gather( |
| | | | | | + store) |
| | group_world_size<--------------------+ | | | 5 |
| | | | | | | |
| | | | | | v |
| | group_rank <-------------------------+ | | _get_ranks(world...) |
| | | | | _get_ranks(role...) |
| | | +----------------+ | | + |
| | workers +----------->+ Worker0(rank 0)| | | | |
| | | | Worker1(rank 1)| | | | 6 |
| | | | ... | |Workers| v |
| | | | Workern(rank n)+<------------+ new Worker(local_rank, |
| +--------------------+ +---------+------+ | 7 | global_rank, |
| ^ | | role_rank, |
| | | | world_size, |
| | | | role_world_size) |
+----------------------------------------------+ | |
| +---------------+-----------------+
| |
| | 8
| 9 v
+-----------------------+ _start_workers
+
| 10
|
v
+---------------+--------------+
| state = _monitor_workers |
+--> | +-->
| +---------------+--------------+ |
| | |
<--------------------------------------+
LOOP Every 30S |
| 11
v
_exit_barrier
手机如下:
