[源码解析] 深度学习分布式训练框架 horovod (19) --- kubeflow MPI-operator
0x00 摘要
Horovod 是一款基于 AllReduce 的分布式训练框架。凭借其对 TensorFlow、PyTorch 等主流深度学习框架的支持,以及通信优化等特点,Horovod 被广泛应用于数据并行的训练中。
本文是 horovod on k8s 的中间阶段,是 Horovod 的主要相关部分,看看 Horovod on K8S 在社区内如何实现。
本文目的是:借着分析学习 Horovod on K8S 功能,把相关概念梳理一遍,期望可以从中找出设计思路。所以成文方式是:整理学习了很多网上文章,然后自己分析代码。特此对各位作者深表感谢。
本系列其他文章链接如下:
[源码解析] 深度学习分布式训练框架 Horovod (1) --- 基础知识
[源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入
[源码解析] 深度学习分布式训练框架 horovod (3) --- Horovodrun背后做了什么
[源码解析] 深度学习分布式训练框架 horovod (4) --- 网络基础 & Driver
[源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架
[源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构
[源码解析] 深度学习分布式训练框架 horovod (7) --- DistributedOptimizer
[源码解析] 深度学习分布式训练框架 horovod (8) --- on spark
[源码解析] 深度学习分布式训练框架 horovod (9) --- 启动 on spark
[源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark
[源码解析] 深度学习分布式训练框架 horovod (11) --- on spark --- GLOO 方案
[源码解析] 深度学习分布式训练框架 horovod (12) --- 弹性训练总体架构
[源码解析] 深度学习分布式训练框架 horovod (13) --- 弹性训练之 Driver
[源码解析] 深度学习分布式训练框架 horovod (14) --- 弹性训练发现节点 & State
[源码解析] 深度学习分布式训练框架 horovod (15) --- 广播 & 通知
[源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Worker生命周期
[源码解析] 深度学习分布式训练框架 horovod (17) --- 弹性训练之容错
[源码解析] 深度学习分布式训练框架 horovod (18) --- kubeflow tf-operator
0x01 背景知识
首先,K8S 和 Kube-flow 部分请参见前文。
1.1 MPI
MPI(Message Passing Interface) 是一种可以支持点对点和广播的通信协议,具体实现的库有很多,使用比较流行的包括 Open Mpi, Intel MPI 等等。
MPI 是一种消息传递编程模型。消息传递指用户必须通过显式地发送和接收消息来实现处理器间的数据交换。在这种并行编程中,每个控制流均有自己独立的地址空间,不同的控制流之间不能直接访问彼此的地址空间,必须通过显式的消息传递来实现。这种编程方式是大规模并行处理机(MPP)和机群(Cluster)采用的主要编程方式。由于消息传递程序设计要求用户很好地分解问题,组织不同控制流间的数据交换,并行计算粒度大,特别适合于大规模可扩展并行算法。
MPI 是基于进程的并行环境。进程拥有独立的虚拟地址空间和处理器调度,并且执行相互独立。MPI 设计为支持通过网络连接的机群系统,且通过消息传递来实现通信,消息传递是 MPI 的最基本特色。
1.2 Open-MPI
OpenMPI 是一种高性能消息传递库,最初是作为融合的技术和资源从其他几个项目(FT-MPI, LA-MPI, LAM/MPI, 以及 PACX-MPI),它是 MPI-2 标准的一个开源实现,由一些科研机构和企业一起开发和维护。
因此,OpenMPI 能够从高性能社区中获得专业技术、工业技术和资源支持,来创建最好的 MPI 库。OpenMPI 提供给系统和软件供应商、程序开发者和研究人员很多便利。易于使用,并运行本身在各种各样的操作系统,网络互连,以及调度系统。
1.3 MPI Operator
MPI Operator 是 Kubeflow 的一个组件,是 Kubeflow 社区贡献的另一个关于深度/机器学习的一个 Operator,主要就是为了 MPI 任务或者 Horovod 任务提供了一个多机管理工作。
Kubeflow 提供 mpi-operator,可使 allreduce 样式的分布式训练像在单个节点上进行培训一样简单。
我们可以轻松地在 Kubernetes 上运行 allreduce 样式的分布式训练。在操作系统上安装ksonnet 后,可安装 MPI Operator。其后将安装 MPIJob 和作业控制器,最后可以将 MPIJob 提交到 Kubernetes 集群。
对于用户,只要创建一个 MPIJob 的自定义资源对象,在 Template 配置好 Launcher 和 Worker 的相关信息,就相当于描述好一个分布式训练程序的执行过程了。
Mpi-operator 可以做到开箱即用,但是在生产集群的应用,面对一些固定场景和业务的时候会有一定的限制。
我们看看其 Dockerfile,可以看到安装了 MPI,hovorod 等等软件。
# Install TensorFlow, Keras, PyTorch and MXNet
RUN pip install future typing
RUN pip install numpy
tensorflow==${TENSORFLOW_VERSION}
keras
h5py
RUN pip install torch==${PYTORCH_VERSION} torchvision==${TORCHVISION_VERSION}
RUN pip install mxnet==${MXNET_VERSION}
# Install Open MPI
RUN mkdir /tmp/openmpi &&
cd /tmp/openmpi &&
wget https://www.open-mpi.org/software/ompi/v4.0/downloads/openmpi-4.0.0.tar.gz &&
tar zxf openmpi-4.0.0.tar.gz &&
cd openmpi-4.0.0 &&
./configure --enable-orterun-prefix-by-default &&
make -j $(nproc) all &&
make install &&
ldconfig &&
rm -rf /tmp/openmpi
# Install Horovod
RUN HOROVOD_WITH_TENSORFLOW=1 HOROVOD_WITH_PYTORCH=1 HOROVOD_WITH_MXNET=1
pip install --no-cache-dir horovod==${HOROVOD_VERSION}
0x02 设计思路
目前社区在 mpi-operator 主要用于 allreduce-style 的分布式训练,因为 mpi-operator 本质上就是给用户管理好多个进程之间的关系,所以天然支持的框架很多,包括 Horovod, TensorFlow, PyTorch, Apache MXNet 等等。
而 mpi-operator 的基本架构是通过 Mpi-job 的这种自定义资源对象来描述分布式机器学习的训练任务,同时实现了 Mpijob 的 Controller 来控制,其中分为 Launcher 和 Worker 这两种类型的工作负荷。
其特点如下:
-
为Horovod/MPI多机训练准备的Operator
-
多机任务分为多种角色
- Launcher
- Worker-N
-
每个任务通过特定的RBAC
-
每个任务会设置rsh_agent以及hostfile
-
Launcher中init-container会等worker就位后
2.1 架构图
其架构图如下:
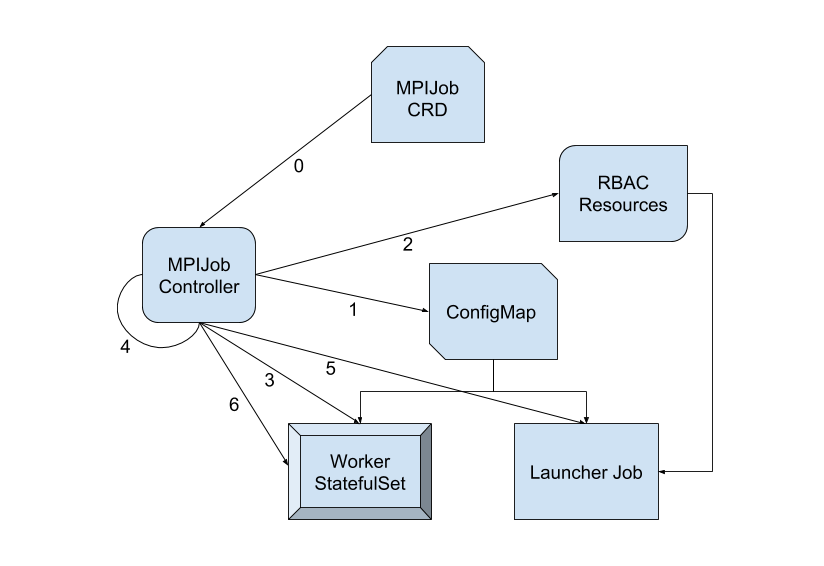
2.2 角色
主要分两种角色。
Worker本质上是StatefulSet,在分布式训练的过程中,训练任务通常是有状态的,StatefulSet正是管理这些的 Workload 的对象。Launcher相当于一个启动器的角色,它会等Worker都就位之后,去启动MPI的任务。通常会是一个比较轻量化的 Job,他主要完成几条命令的发送就可以了,通常是把命令通过ssh/rsh来发送接受命令,在 mpi-operator 里使用的是kubectl来给Worker发送命令。
这里我们有了一个疑问,为什么 MPI-Operator 于 TF-Operator 相比没有 service 概念?
应该是因为 MPI-Operator 都是内部运作,不需要外部访问,所以不需要添加 Service。
即 MPI-Operator 用这个启动,就不需要service 了。因为 MPI-Operator 利用 API 获得了 pod 信息,kubectl-delivery 的已经将 kubectl 放入到 Launcher 容器内,之后可以通过 kubectl 来给 Worker 发送 mpirun 的命令
%s/kubectl cp %s/hosts ${POD_NAME}:/etc/hosts_of_nodes
%s/kubectl exec ${POD_NAME},
2.3 主要过程
其主要过程包括:
- MPIJob Controller 会根据每一份 MPIJob 的配置,生成一个 launcher pod 和对应个数的 worker pod;
- MPIJob Controller 会针对每一份 MPIJob 生成一份 ConfigMap,其中包含两份脚本,一为反应该任务所有 worker pod 的
hostfile,一为kubexec.sh脚本; - Launcher pod 上的
mpirun会利用由 ConfigMap 中的kubexel 在 worker pod 中拉起进程;需要注意的是,kubectl的执行有赖于 MPIJob Controller 预先创建的 RBAC 资源(如果对应的 Role 中没有给 launcher pod 配置在 worker pod 上的执行权限,launcher pod 在执行kubectl exec` 时会被拒绝);
2.4 CRD 的定义
Mpi-operator 里面扩展出来的新 CRD,名为MPIJob,他的具体定义可以在这里找到:mpijob-v1alpha2-crd.yaml.
对于用户,只要创建一个 Mpijob 的自定义资源对象,在 Template 配置好 Launcher 和 Worker 的相关信息,就相当于描述好一个分布式训练程序的执行过程了。
简单介绍下该新 CRD Spec 的组成:
- launcher:目前只是一个,只运行启动 mpijob 的 pod,不运行 workload;
- worker:可以是一个也可以是多个,真正运行 workload 的 Pod;
- slotsPerWorker:每个 worker 运行的 slots 数目;
- backoffLimit:最多重试次数;
- cleanPodPolicy:任务结束时,清除 Pod 策略;
- runPolicy:多机任务运行策略;
具体Spec样例如下:
apiVersion: kubeflow.org/v1alpha2
kind: MPIJob
metadata:
name: tensorflow-mnist
spec:
slotsPerWorker: 1
cleanPodPolicy: Running
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- image: horovod-cpu:latest
name: mpi-launcher
command:
- mpirun
args:
- -np
- "2"
- --allow-run-as-root
- -bind-to
- none
- -map-by
- slot
- -x
- LD_LIBRARY_PATH
- -x
- PATH
- -mca
- pml
- ob1
- -mca
- btl
- ^openib
- python
- /examples/tensorflow_mnist.py
resources:
limits:
cpu: 1
memory: 2Gi
Worker:
replicas: 2
template:
spec:
containers:
- command:
- ""
image: horovod-cpu:latest
name: mpi-worker
resources:
limits:
cpu: 2
memory: 4Gi
有了 MPI-Operator 的定义,就可以具体执行。一般来说新的 CRD 都是无法复用 Kubernetes 现有资源类型的情况,那么就会通过 operator 进行转换,转换成 Kubernetes 可以识别的资源类型。
- 比如上面的
Launcher会被转换成 Kubernetes 中的 job 资源类型。 - worker 会被转换成 Kubernetes 中的 Statefulset,进而通过 informers 的机制来监控 Kubernetes 中的 Job 和 Statefulset 这两个资源更新 MPIJob 的资源状态。
下面我们以两个典型的操作来介绍如何执行的:
2.5 创建
当用户创建了一个 MPIJob,其中包含一个 Launcher,2 个 Worker 这样的配置,进行多机训练时,当是如何进行的呢?下面依次介绍:
- 与一般的 controller 写法相同,监听 MPIJob 创建,并将其放入队列中;
- 多线程从队列中去处新的 mpijob,进行处理,判断 launcher 和 worker 是否存在,如果不存在就进行创建,具体可以参考这个函数;
Mpijob启动的顺序是先启动Worker再启动Launcher。- 创建 launcher 和 worker 的同时,会在 launcher job 创建时添加一个额外的 init container,这个 init container 主要的工作就是监控所有的 worker 都已经就位了,然后执行执行后面 launcher job 里面定义的命令;
- 除此之外,为了能够帮用户减少一些额外的配置,基于 worker pod 的名字,会将其加入到一个 configmap 中,并 mount 到每个 pod 中,这样通过环境变量将 hostfile 设置为这个 mount 的 configmap 路径,就可以发现多机程序,进而去链接了;
- 前面也介绍过 rsh agent,默认是用 sshd,这个要设置面秘钥登录,设置起来会稍显麻烦,那么在 Kubernetes 中运行有没有更简单的办法?答案是有的。我们通过 kubectl 命令来达到同样的效果,参见此处代码。在这里会创建一个可执行程序,然后去通知 worker pod 去执行相应的命令等操作;
- 其中
kubectl-delivery的作用主要是将kubectl放入到Launcher容器内,之后可以通过kubectl来给Worker发送mpirun的命令。
至此,mpijob 就被转换成 Kubernetes 可以识别的类型,并开始运行了。
2.6 终止
MPIJob 的终止 终止分为两种类型,分别是正确,或者是出错了。
- 针对正常终止,Launcher Job 的状态会变成 Completed 状态,mpi-operator 会发现监听的 job 状态变化,进而去找到对应的 mpijob,并更新其状态,代码在这里;
- 针对异常终止,某一个 worker 或者 launcher 出现了错误,那么会进行重试(笔者注:这里面的重试其实没有意义),如果超过了
backoffLimit,那么就会认为是 failed 状态,执行上面步骤中同样的函数,并更新 mpijob 状态为 failed; - 当 mpijob 终止了,就会通过
cleanPodPolicy去删除没用的 pod;
0x03 实现
3.1 K8S CRD 基本概念
首先,我们需要介绍下 K8S 一些概念,我们编程主要涉及这么几个概念:
-
informer:监听apiserver中特定资源变化,然后会存储到一个线程安全的local cache中,最后回调我们自己实现的event handler。
-
local cache:informer实时同步apiserver(也就是etcd)中的数据到内存中存储,可以有效降低apiserver的查询压力,但缺点就是实时性不好,本地会比远程的数据落后一点点但会最终与etcd一致,所以需要根据情况具体分析是走Local cache还是apiserver实时获取数据。
-
Lister:提供了CURD操作访问local cache。
-
controller:一个逻辑概念,就是指调度某种资源的实现而已,需要我们自己开发。Controller做的事情主要包括:
-
- 实现event handler处理资源的CURD操作
- 在event handler,可以使用workqueue类库实现相同资源对象的连续event的去重,以及event处理异常后的失败重试,通常是建议使用的。
-
Workqueue:一个单独的类库,是可选使用的,但通常都会使用,原因上面说了。我们需要在实现event handler的时候把发生变化的资源标识放入workqueue,供下面的processor消费。
-
Clientset:默认clientset只能CRUD k8s提供的资源类型,比如deployments,daemonset等;生成的代码为我们自定义的资源(CRD)生成了单独的clientset,从而让我们使用结构化的代码CURD自定义资源。也就是说,想操作内建资源就用k8s自带的clientset,想操作CRD就用生成代码里的clientset。
-
Processor:我们实现的go协程,消费workqueue中的事件,workqueue提供了按资源标识的去重。
3.2 入口
MPI-Operator 的入口是 Run 函数。
- 这里最重要的就是使用 NewMPIJobController 来生成一个 controller;
- 然后调用 controller.Run 来运行;
func Run(opt *options.ServerOption) error {
cfg, err := clientcmd.BuildConfigFromFlags(opt.MasterURL, opt.Kubeconfig)
// Create clients.
kubeClient, leaderElectionClientSet, mpiJobClientSet, volcanoClientSet, err := createClientSets(cfg)
// Add mpi-job-controller types to the default Kubernetes Scheme so Events
// can be logged for mpi-job-controller types.
err = kubeflowScheme.AddToScheme(clientgokubescheme.Scheme)
// Set leader election start function.
run := func(ctx context.Context) {
var kubeInformerFactory kubeinformers.SharedInformerFactory
var kubeflowInformerFactory informers.SharedInformerFactory
var volcanoInformerFactory volcanoinformers.SharedInformerFactory
if namespace == metav1.NamespaceAll {
kubeInformerFactory = kubeinformers.NewSharedInformerFactory(kubeClient, 0)
kubeflowInformerFactory = informers.NewSharedInformerFactory(mpiJobClientSet, 0)
volcanoInformerFactory = volcanoinformers.NewSharedInformerFactory(volcanoClientSet, 0)
} else {
kubeInformerFactory = kubeinformers.NewSharedInformerFactoryWithOptions(kubeClient, 0, kubeinformers.WithNamespace(namespace))
kubeflowInformerFactory = informers.NewSharedInformerFactoryWithOptions(mpiJobClientSet, 0, informers.WithNamespace(namespace))
volcanoInformerFactory = volcanoinformers.NewSharedInformerFactoryWithOptions(volcanoClientSet, 0, volcanoinformers.WithNamespace(namespace))
}
var podgroupsInformer podgroupsinformer.PodGroupInformer
if opt.GangSchedulingName != "" {
podgroupsInformer = volcanoInformerFactory.Scheduling().V1beta1().PodGroups()
}
controller := controllersv1.NewMPIJobController(
kubeClient,
mpiJobClientSet,
volcanoClientSet,
kubeInformerFactory.Core().V1().ConfigMaps(),
kubeInformerFactory.Core().V1().ServiceAccounts(),
kubeInformerFactory.Rbac().V1().Roles(),
kubeInformerFactory.Rbac().V1().RoleBindings(),
kubeInformerFactory.Core().V1().Pods(),
podgroupsInformer,
kubeflowInformerFactory.Kubeflow().V1().MPIJobs(),
opt.KubectlDeliveryImage,
opt.GangSchedulingName)
go kubeInformerFactory.Start(ctx.Done())
go kubeflowInformerFactory.Start(ctx.Done())
if opt.GangSchedulingName != "" {
go volcanoInformerFactory.Start(ctx.Done())
}
// Set leader election start function.
isLeader.Set(1)
if err = controller.Run(opt.Threadiness, stopCh); err != nil {
klog.Fatalf("Error running controller: %s", err.Error())
}
}
}
3.3 NewMPIJobController
NewMPIJobController 的作用是生成了MPIJobController,并且配置了一系列 Informer。
Informer 的作用是 监听apiserver中特定资源变化,然后会存储到一个线程安全的local cache中,最后回调我们自己实现的event handler
这里基本看名字就可以确认其作用。
// NewMPIJobController returns a new MPIJob controller.
func NewMPIJobController(...) *MPIJobController {
// Create event broadcaster.
eventBroadcaster := record.NewBroadcaster()
var podgroupsLister podgroupslists.PodGroupLister
controller := &MPIJobController{
kubeClient: kubeClient,
kubeflowClient: kubeflowClient,
volcanoClient: volcanoClientSet,
......
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "MPIJobs"),
....
}
controller.updateStatusHandler = controller.doUpdateJobStatus
// Set up an event handler for when MPIJob resources change.
mpiJobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.addMPIJob,
UpdateFunc: func(old, new interface{}) {
controller.enqueueMPIJob(new)
},
})
configMapInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newConfigMap := new.(*corev1.ConfigMap)
controller.handleObject(new)
}
})
serviceAccountInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newServiceAccount := new.(*corev1.ServiceAccount)
controller.handleObject(new)
}
})
roleInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newRole := new.(*rbacv1.Role)
controller.handleObject(new)
}
})
roleBindingInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newRoleBinding := new.(*rbacv1.RoleBinding)
controller.handleObject(new)
}
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newPod := new.(*corev1.Pod)
controller.handleObject(new)
}
})
if podgroupsInformer != nil {
podgroupsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newPolicy := new.(*podgroupv1beta1.PodGroup)
controller.handleObject(new)
}
})
}
return controller
}
3.4 MPIJobController
我们顺理成章的来到了 MPIJobController,基本如下:
- 与一般的 controller 写法相同,监听 MPIJob 创建,并将其放入队列中;
- 多线程从队列中去处新的 mpijob,进行处理,判断 launcher 和 worker 是否存在,如果不存在就进行创建;
看看其定义,基本就是配置了各种 InformerSynced,Lister。
// MPIJobController is the controller implementation for MPIJob resources.
type MPIJobController struct {
// kubeClient is a standard kubernetes clientset.
kubeClient kubernetes.Interface
// kubeflowClient is a clientset for our own API group.
kubeflowClient clientset.Interface
// volcanoClient is a clientset for volcano.sh API.
volcanoClient volcanoclient.Interface
configMapLister corelisters.ConfigMapLister
configMapSynced cache.InformerSynced
serviceAccountLister corelisters.ServiceAccountLister
serviceAccountSynced cache.InformerSynced
roleLister rbaclisters.RoleLister
roleSynced cache.InformerSynced
roleBindingLister rbaclisters.RoleBindingLister
roleBindingSynced cache.InformerSynced
podLister corelisters.PodLister
podSynced cache.InformerSynced
podgroupsLister podgroupslists.PodGroupLister
podgroupsSynced cache.InformerSynced
mpiJobLister listers.MPIJobLister
mpiJobSynced cache.InformerSynced
// queue is a rate limited work queue. This is used to queue work to be
// processed instead of performing it as soon as a change happens. This
// means we can ensure we only process a fixed amount of resources at a
// time, and makes it easy to ensure we are never processing the same item
// simultaneously in two different workers.
queue workqueue.RateLimitingInterface
// recorder is an event recorder for recording Event resources to the
// Kubernetes API.
recorder record.EventRecorder
// The container image used to deliver the kubectl binary.
kubectlDeliveryImage string
// Gang scheduler name to use
gangSchedulerName string
// To allow injection of updateStatus for testing.
updateStatusHandler func(mpijob *kubeflow.MPIJob) error
}
大致逻辑如下:
+-----------------------------+
| MPIJobController |
| | +---> addMPIJob
| | |
| mpiJobInformer +--------+
| | |
| | +---> enqueueMPIJob
| |
| |
| serviceAccountInformer +-------> handleObject(ServiceAccount)
| |
| |
| roleInformer +-------------> handleObject(Role)
| |
| |
| roleBindingInformer +--------> handleObject(RoleBinding)
| |
| |
| podInformer +--------------> handleObject(Pod)
| |
| |
| podgroupsInformer +----------> handleObject(PodGroup)
| |
+-----------------------------+
3.5 响应 new Job 消息
上文看到,mpiJobInformer 设置了两个消息响应函数,其中 addMPIJob 负责处理新 Job 的生成。
// Set up an event handler for when MPIJob resources change.
mpiJobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.addMPIJob,
UpdateFunc: func(old, new interface{}) {
controller.enqueueMPIJob(new)
},
})
addMPIJob 的作用就是 生成了一个 kubeflow.MPIJob,然后调用 c.enqueueMPIJob 加入到 queue 之中。
// When a mpiJob is added, set the defaults and enqueue the current mpiJob.
func (c *MPIJobController) addMPIJob(obj interface{}) {
mpiJob := obj.(*kubeflow.MPIJob)
// Set default for the new mpiJob.
scheme.Scheme.Default(mpiJob)
// Add a created condition.
err := updateMPIJobConditions(mpiJob, common.JobCreated, mpiJobCreatedReason, msg)
c.recorder.Event(mpiJob, corev1.EventTypeNormal, "MPIJobCreated", msg)
mpiJobsCreatedCount.Inc()
c.enqueueMPIJob(mpiJob)
}
具体如下:
+-----------------------------+ kubeflow.MPIJob
| MPIJobController |
| | +---> addMPIJob +------------+
| | | |
| mpiJobInformer +--------+ v
| | |
| | +---------------------> enqueueMPIJob
| |
| |
| serviceAccountInformer +-------> handleObject(ServiceAccount)
| |
| |
| roleInformer +-------------> handleObject(Role)
| |
| |
| roleBindingInformer +--------> handleObject(RoleBinding)
| |
| |
| podInformer +--------------> handleObject(Pod)
| |
| |
| podgroupsInformer +----------> handleObject(PodGroup)
| |
+-----------------------------+
enqueueMPIJob 的代码如下,其中,c.queue 就是之前设定的 workqueue.NewNamedRateLimitingQueue。
// enqueueMPIJob takes a MPIJob resource and converts it into a namespace/name
// string which is then put onto the work queue. This method should *not* be
// passed resources of any type other than MPIJob.
func (c *MPIJobController) enqueueMPIJob(obj interface{}) {
var key string
var err error
if key, err = cache.MetaNamespaceKeyFunc(obj); err != nil {
runtime.HandleError(err)
return
}
c.queue.AddRateLimited(key)
}
3.5 主循环
上面是创建和监听,下面是处理消息了,处理消息就是在主循环之中完成的。
3.5.1 消息循环
在 runWorker 的主循环就是一直执行 processNextWorkItem。
// runWorker is a long-running function that will continually call the
// processNextWorkItem function in order to read and process a message on the
// work queue.
func (c *KubectlDeliveryController) runWorker() {
for c.processNextWorkItem() {
}
}
3.5.2 processNextWorkItem
processNextWorkItem 从 queue 之中获取一个消息,然后调用了 syncHandler 进行处理。
// processNextWorkItem will read a single work item off the work queue and
// attempt to process it, by calling the syncHandler.
func (c *KubectlDeliveryController) processNextWorkItem() bool {
obj, shutdown := c.queue.Get()
if shutdown {
return false
}
// We wrap this block in a func so we can defer c.queue.Done.
err := func(obj interface{}) error {
defer c.queue.Done(obj)
var key string
var ok bool
if key, ok = obj.(string); !ok {
c.queue.Forget(obj)
return nil
}
// Run the syncHandler, passing it the namespace/name string of the
// MPIJob resource to be synced.
if err := c.syncHandler(key); err != nil {
c.queue.AddRateLimited(key)
return fmt.Errorf("error syncing '%s': %s", key, err.Error())
}
c.queue.Forget(obj)
return nil
}(obj)
return true
}
逻辑扩展如下:
+-----------------------------+ kubeflow.MPIJob
| MPIJobController |
| | +---> addMPIJob +------------+ +-------> runWorker +-------+
| | | | | |
| mpiJobInformer +--------+ v | |
| | | | v
| | +---------------------> enqueueMPIJob +---+ processNextWorkItem <--+
| | +
| | | ^
| | | +--------------+ |
| | +---> | | |
| | | workqueue +-------+
| queue +-------------------------------------------------> | |
| | +--------------+
| |
| |
| serviceAccountInformer +-------> handleObject(ServiceAccount)
| |
| |
| roleInformer +-------------> handleObject(Role)
| |
| |
| roleBindingInformer +--------> handleObject(RoleBinding)
| |
| |
| podInformer +--------------> handleObject(Pod)
| |
| |
| podgroupsInformer +----------> handleObject(PodGroup)
| |
+-----------------------------+
手机如下:

3.5.3 syncHandler
processNextWorkItem 主要就是调用了 syncHandler,其作用主要是:同步状态,生成 worker 或者 launcher。
就相当于是创建资源,子资源创建顺序如下:
- 创建 configmap, 包含 discover_host 脚本 , hostfile 文件。
- 创建 workers,包含 service 和 pod。
- 创建 launcher,挂载 configmap。hostfile 后续会随着拓扑关系修改。
具体逻辑如下:
- 依据 namespace/name 得到 MPIJob。
- 如果已经结束,就删除 pods;
- 从 MPIJob 取得 launcher Job;
- 如果 launcher Job 没有结束,则
- 获得 MPIJob 的 ConfigMap;
- 获得 ServiceAccount;
- 获得 Role;
- 获得 RoleBinding;
- 获得 PodGroup;
- 创建 worker;
- 如果 launcher 目前为空,则创建 Launcher;
Mpijob启动的顺序是先启动Worker再启动Launcher。 - 更新各种状态
代码如下:
// syncHandler compares the actual state with the desired, and attempts to
// converge the two. It then updates the Status block of the MPIJob resource
// with the current status of the resource.
func (c *MPIJobController) syncHandler(key string) error {
// Convert the namespace/name string into a distinct namespace and name.
namespace, name, err := cache.SplitMetaNamespaceKey(key)
// Get the MPIJob with this namespace/name.
sharedJob, err := c.mpiJobLister.MPIJobs(namespace).Get(name)
// Whether the job is preempted, and requeue it
requeue := false
// If the MPIJob is terminated, delete its pods according to cleanPodPolicy.
if isFinished(mpiJob.Status) {
if isSucceeded(mpiJob.Status) && isCleanUpPods(mpiJob.Spec.CleanPodPolicy) {
// set worker StatefulSet Replicas to 0.
initializeMPIJobStatuses(mpiJob, kubeflow.MPIReplicaTypeWorker)
mpiJob.Status.ReplicaStatuses[common.ReplicaType(kubeflow.MPIReplicaTypeWorker)].Active = 0
if c.gangSchedulerName != "" {
if err := c.deletePodGroups(mpiJob); err != nil {
return err
}
}
}
if !requeue {
if isFailed(mpiJob.Status) && isCleanUpPods(mpiJob.Spec.CleanPodPolicy) {
// set worker StatefulSet Replicas to 0.
if err := c.deleteWorkerPods(mpiJob); err != nil {
return err
}
}
return c.updateStatusHandler(mpiJob)
} else {
launcher, err := c.getLauncherJob(mpiJob)
if err == nil && launcher != nil && isPodFailed(launcher) {
// In requeue, should delete launcher pod
err = c.kubeClient.CoreV1().Pods(launcher.Namespace).Delete(launcher.Name, &metav1.DeleteOptions{})
}
}
}
// Get the launcher Job for this MPIJob.
launcher, err := c.getLauncherJob(mpiJob)
var worker []*corev1.Pod
// We're done if the launcher either succeeded or failed.
done := launcher != nil && isPodFinished(launcher)
if !done {
workerSpec := mpiJob.Spec.MPIReplicaSpecs[kubeflow.MPIReplicaTypeWorker]
workerReplicas := int32(0)
if workerSpec != nil && workerSpec.Replicas != nil {
workerReplicas = *workerSpec.Replicas
}
isGPULauncher := isGPULauncher(mpiJob)
// Get the ConfigMap for this MPIJob.
if config, err := c.getOrCreateConfigMap(mpiJob, workerReplicas, isGPULauncher);
// Get the launcher ServiceAccount for this MPIJob.
if sa, err := c.getOrCreateLauncherServiceAccount(mpiJob); sa == nil || err != nil
// Get the launcher Role for this MPIJob.
if r, err := c.getOrCreateLauncherRole(mpiJob, workerReplicas); r == nil || err != nil
// Get the launcher RoleBinding for this MPIJob.
if rb, err := c.getLauncherRoleBinding(mpiJob); rb == nil || err != nil
// Get the PodGroup for this MPIJob
if c.gangSchedulerName != "" {
if podgroup, err := c.getOrCreatePodGroups(mpiJob, workerReplicas+1); podgroup == nil || err != nil {
return err
}
}
worker, err = c.getOrCreateWorker(mpiJob)
if launcher == nil {
launcher, err = c.kubeClient.CoreV1().Pods(namespace).Create(c.newLauncher(mpiJob, c.kubectlDeliveryImage, isGPULauncher))
}
}
// Finally, we update the status block of the MPIJob resource to reflect the
// current state of the world.
err = c.updateMPIJobStatus(mpiJob, launcher, worker)
return nil
}
逻辑如下
+-----------------------------+ kubeflow.MPIJob
| MPIJobController |
| | +---> addMPIJob +------------+ +-------> runWorker +-------+
| | | | | |
| mpiJobInformer +--------+ v | |
| | | | v
| | +---------------------> enqueueMPIJob +---+ processNextWorkItem <--+
| | + +
| | | ^ |
| | | +--------------+ | |
| | +---> | | | |
| | | workqueue +-------+ |
| queue +-------------------------------------------------> | | |
| | +--------------+ v
| | syncHandler
| | +
| PodLister | |
| | |
| | v
| | getOrCreateWorker
| serviceAccountInformer +-------> handleObject(ServiceAccount) +
| | |
| | |
| roleInformer +-------------> handleObject(Role) v
| | newLauncher
| | +
| roleBindingInformer +--------> handleObject(RoleBinding) |
| | |
| | v
| podInformer +--------------> handleObject(Pod) updateMPIJobStatus
| |
| |
| podgroupsInformer +----------> handleObject(PodGroup)
| |
+-----------------------------+
手机上如下:

3.5.4 创建 worker
创建 worker分为两个阶段。
3.5.4.1 getOrCreateWorker
首先是 getOrCreateWorker,大致功能如下:
- 从 spec 之中获取 Replicas;
- 依据 job 名字获取到 selector;
- 依据 selector 获取到 pod list;
- 遍历 workerReplicas,逐一调用 newWorker 生成 pod;
// getOrCreateWorkerStatefulSet gets the worker StatefulSet controlled by this
// MPIJob, or creates one if it doesn't exist.
func (c *MPIJobController) getOrCreateWorker(mpiJob *kubeflow.MPIJob) ([]*corev1.Pod, error) {
var (
workerPrefix string = mpiJob.Name + workerSuffix
workerPods []*corev1.Pod = []*corev1.Pod{}
i int32 = 0
workerReplicas *int32
)
if worker, ok := mpiJob.Spec.MPIReplicaSpecs[kubeflow.MPIReplicaTypeWorker]; ok && worker != nil {
workerReplicas = worker.Replicas
}
// Remove Pods when replicas are scaled down
selector, err := workerSelector(mpiJob.Name)
podFullList, err := c.podLister.List(selector)
if len(podFullList) > int(*workerReplicas) {
for _, pod := range podFullList {
indexStr := strings.TrimLeft(pod.Name, fmt.Sprintf("%s-", workerPrefix))
index, err := strconv.Atoi(indexStr)
if err == nil {
if index >= int(*workerReplicas) {
err = c.kubeClient.CoreV1().Pods(pod.Namespace).Delete(pod.Name, &metav1.DeleteOptions{})
}
}
}
}
for ; i < *workerReplicas; i++ {
name := fmt.Sprintf("%s-%d", workerPrefix, i)
pod, err := c.podLister.Pods(mpiJob.Namespace).Get(name)
// If the worker Pod doesn't exist, we'll create it.
if errors.IsNotFound(err) {
worker := newWorker(mpiJob, name, c.gangSchedulerName)
pod, err = c.kubeClient.CoreV1().Pods(mpiJob.Namespace).Create(worker)
}
workerPods = append(workerPods, pod)
}
return workerPods, nil
}
3.5.4.2 newWorker
newWorker 的作用就是创建一个 Pod。
// newWorker creates a new worker StatefulSet for an MPIJob resource. It also
// sets the appropriate OwnerReferences on the resource so handleObject can
// discover the MPIJob resource that 'owns' it.
func newWorker(mpiJob *kubeflow.MPIJob, name, gangSchedulerName string) *corev1.Pod {
labels := defaultWorkerLabels(mpiJob.Name)
podSpec := mpiJob.Spec.MPIReplicaSpecs[kubeflow.MPIReplicaTypeWorker].Template.DeepCopy()
// keep the labels which are set in PodTemplate
if len(podSpec.Labels) == 0 {
podSpec.Labels = make(map[string]string)
}
for key, value := range labels {
podSpec.Labels[key] = value
}
setRestartPolicy(podSpec, mpiJob.Spec.MPIReplicaSpecs[kubeflow.MPIReplicaTypeWorker])
container := podSpec.Spec.Containers[0]
if len(container.Command) == 0 {
container.Command = []string{"sleep"}
container.Args = []string{"365d"}
}
// We need the kubexec.sh script here because Open MPI checks for the path
// in every rank.
container.VolumeMounts = append(container.VolumeMounts, corev1.VolumeMount{
Name: configVolumeName,
MountPath: configMountPath,
})
podSpec.Spec.Containers[0] = container
scriptMode := int32(0555)
podSpec.Spec.Volumes = append(podSpec.Spec.Volumes, corev1.Volume{
Name: configVolumeName,
VolumeSource: corev1.VolumeSource{
ConfigMap: &corev1.ConfigMapVolumeSource{
LocalObjectReference: corev1.LocalObjectReference{
Name: mpiJob.Name + configSuffix,
},
Items: []corev1.KeyToPath{
{
Key: kubexecScriptName,
Path: kubexecScriptName,
Mode: &scriptMode,
},
},
},
},
})
// add SchedulerName to podSpec
if gangSchedulerName != "" {
podSpec.Spec.SchedulerName = gangSchedulerName
if podSpec.Annotations == nil {
podSpec.Annotations = map[string]string{}
}
// we create the podGroup with the same name as the mpijob
podSpec.Annotations[podgroupv1beta1.KubeGroupNameAnnotationKey] = mpiJob.Name
}
return &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: name,
Namespace: mpiJob.Namespace,
Labels: podSpec.Labels,
Annotations: podSpec.Annotations,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(mpiJob, kubeflow.SchemeGroupVersionKind),
},
},
Spec: podSpec.Spec,
}
}
3.5.5 创建 Launcher
3.5.5.1 newLauncher
我们先看看 newLauncher,这是主要函数,其主要逻辑就是:
- 生成了 InitContainers。其目的是:创建 launcher 和 worker 的同时,会在 launcher job 创建时添加一个额外的 InitContainers,这个 InitContainers 主要的工作就是监控所有的 worker 都已经就位了,然后执行执行后面 launcher job 里面定义的命令;
- 这里生成 container 时候,用到了 kubectlDeliveryName,就是
"kubectl-delivery"。其中kubectl-delivery的作用主要是将kubectl放入到Launcher容器内,之后可以通过kubectl来给Worker发送mpirun的命令; - 另外,前面也介绍过 rsh agent,默认是用 sshd,这个要设置面秘钥登录,设置起来会稍显麻烦,那么在 Kubernetes 中运行有没有更简单的办法?答案是有的。我们通过 kubectl 命令来达到同样的效果,参见此处代码。在这里会创建一个可执行程序,然后去通知 worker pod 去执行相应的命令等操作;
- 这里生成 container 时候,用到了 kubectlDeliveryName,就是
- 生成 OMPI_MCA_plm_rsh_agent 和 OMPI_MCA_orte_default_hostfile 信息,这些是配置文件的地址,分别对应 discovery_hosts.sh 和 /etc/mpi/kubexec.sh ;
- 生成 Pod;
// newLauncher creates a new launcher Job for an MPIJob resource. It also sets
// the appropriate OwnerReferences on the resource so handleObject can discover
// the MPIJob resource that 'owns' it.
func (c *MPIJobController) newLauncher(mpiJob *kubeflow.MPIJob, kubectlDeliveryImage string, isGPULauncher bool) *corev1.Pod {
launcherName := mpiJob.Name + launcherSuffix
labels := map[string]string{
labelGroupName: "kubeflow.org",
labelMPIJobName: mpiJob.Name,
labelMPIRoleType: launcher,
}
podSpec := mpiJob.Spec.MPIReplicaSpecs[kubeflow.MPIReplicaTypeLauncher].Template.DeepCopy()
// copy the labels and annotations to pod from PodTemplate
if len(podSpec.Labels) == 0 {
podSpec.Labels = make(map[string]string)
}
for key, value := range labels {
podSpec.Labels[key] = value
}
// add SchedulerName to podSpec
if c.gangSchedulerName != "" {
if podSpec.Spec.SchedulerName != "" && podSpec.Spec.SchedulerName != c.gangSchedulerName {
klog.Warningf("%s scheduler is specified when gang-scheduling is enabled and it will be overwritten", podSpec.Spec.SchedulerName)
}
podSpec.Spec.SchedulerName = c.gangSchedulerName
if podSpec.Annotations == nil {
podSpec.Annotations = map[string]string{}
}
// we create the podGroup with the same name as the mpijob
podSpec.Annotations[podgroupv1beta1.KubeGroupNameAnnotationKey] = mpiJob.Name
}
// 监控所有的 worker 都已经就位了,然后执行执行后面 launcher job 里面定义的命令
podSpec.Spec.ServiceAccountName = launcherName
podSpec.Spec.InitContainers = append(podSpec.Spec.InitContainers, corev1.Container{
Name: kubectlDeliveryName,
Image: kubectlDeliveryImage,
ImagePullPolicy: corev1.PullIfNotPresent,
Env: []corev1.EnvVar{
{
Name: kubectlTargetDirEnv,
Value: kubectlMountPath,
},
{
Name: "NAMESPACE",
Value: mpiJob.Namespace,
},
},
VolumeMounts: []corev1.VolumeMount{
{
Name: kubectlVolumeName,
MountPath: kubectlMountPath,
},
{
Name: configVolumeName,
MountPath: configMountPath,
},
},
Resources: corev1.ResourceRequirements{
Limits: corev1.ResourceList{
corev1.ResourceCPU: resource.MustParse(initContainerCpu),
corev1.ResourceMemory: resource.MustParse(initContainerMem),
corev1.ResourceEphemeralStorage: resource.MustParse(initContainerEphStorage),
},
Requests: corev1.ResourceList{
corev1.ResourceCPU: resource.MustParse(initContainerCpu),
corev1.ResourceMemory: resource.MustParse(initContainerMem),
corev1.ResourceEphemeralStorage: resource.MustParse(initContainerEphStorage),
},
},
})
container := podSpec.Spec.Containers[0]
container.Env = append(container.Env,
corev1.EnvVar{
Name: "OMPI_MCA_plm_rsh_agent",
Value: fmt.Sprintf("%s/%s", configMountPath, kubexecScriptName),
},
corev1.EnvVar{
Name: "OMPI_MCA_orte_default_hostfile",
Value: fmt.Sprintf("%s/%s", configMountPath, hostfileName),
},
)
if !isGPULauncher {
container.Env = append(container.Env,
// We overwrite these environment variables so that users will not
// be mistakenly using GPU resources for launcher due to potential
// issues with scheduler/container technologies.
corev1.EnvVar{
Name: "NVIDIA_VISIBLE_DEVICES",
Value: "",
},
corev1.EnvVar{
Name: "NVIDIA_DRIVER_CAPABILITIES",
Value: "",
})
}
container.VolumeMounts = append(container.VolumeMounts,
corev1.VolumeMount{
Name: kubectlVolumeName,
MountPath: kubectlMountPath,
},
corev1.VolumeMount{
Name: configVolumeName,
MountPath: configMountPath,
})
podSpec.Spec.Containers[0] = container
setRestartPolicy(podSpec, mpiJob.Spec.MPIReplicaSpecs[kubeflow.MPIReplicaTypeLauncher])
scriptsMode := int32(0555)
hostfileMode := int32(0444)
podSpec.Spec.Volumes = append(podSpec.Spec.Volumes,
corev1.Volume{
Name: kubectlVolumeName,
VolumeSource: corev1.VolumeSource{
EmptyDir: &corev1.EmptyDirVolumeSource{},
},
},
corev1.Volume{
Name: configVolumeName,
VolumeSource: corev1.VolumeSource{
ConfigMap: &corev1.ConfigMapVolumeSource{
LocalObjectReference: corev1.LocalObjectReference{
Name: mpiJob.Name + configSuffix,
},
Items: []corev1.KeyToPath{
{
Key: kubexecScriptName,
Path: kubexecScriptName,
Mode: &scriptsMode,
},
{
Key: hostfileName,
Path: hostfileName,
Mode: &hostfileMode,
},
{
Key: discoverHostsScriptName,
Path: discoverHostsScriptName,
Mode: &scriptsMode,
},
},
},
},
})
return &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: launcherName,
Namespace: mpiJob.Namespace,
Labels: podSpec.Labels,
Annotations: podSpec.Annotations,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(mpiJob, kubeflow.SchemeGroupVersionKind),
},
},
Spec: podSpec.Spec,
}
}
逻辑如下:
+-----------------------------+ kubeflow.MPIJob
| MPIJobController |
| | +---> addMPIJob +------------+ +-------> runWorker +-------+
| | | | | |
| mpiJobInformer +--------+ v | |
| | | | v
| | +---------------------> enqueueMPIJob +---+ processNextWorkItem <--+
| | + +
| | | ^ |
| | | +--------------+ | |
| | +---> | | | |
| | | workqueue +-------+ |
| queue +-------------------------------------------------> | | v
| | +--------------+ syncHandler
| | +
| | |
| PodLister | |
| | v
| | getOrCreateWorker +----> newWorker +----> Pod
| | +
| serviceAccountInformer +-------> handleObject(ServiceAccount) |
| | |
| | v
| roleInformer +-------------> handleObject(Role) +--------------------------+----------------------+
| | | newLauncher |
| | | |
| roleBindingInformer +--------> handleObject(RoleBinding) | OMPI_MCA_plm_rsh_agent +---------> Pod
| | | OMPI_MCA_orte_default_hostfile |
| | | kubexecScript hostfile discoverHostsScript |
| podInformer +--------------> handleObject(Pod) | |
| | +--------------------------+----------------------+
| | |
| podgroupsInformer +----------> handleObject(PodGroup) |
| | v
+-----------------------------+ updateMPIJobStatus
手机如下:

3.5.6 利用 ConfigMap 简化配置
K8S configMap的主要作用就是为了让镜像 和 配置文件解耦,以便实现镜像的可移植性和可复用性。
因为一个configMap其实就是一系列配置信息的集合,将来可直接注入到Pod中的容器使用,它通过两种方式实现给Pod传递配置参数:
- 将环境变量直接定义在configMap中,当Pod启动时,通过env来引用configMap中定义的环境变量。
- 将一个完整配置文件封装到configMap中,然后通过共享卷的方式挂载到Pod中,实现给应用传参。
Horovod 为了能够帮用户减少一些额外的配置,基于 worker pod 的名字,会将其加入到一个 configmap 中,并 mount 到每个 pod 中,这样通过环境变量将 hostfile 设置为这个 mount 的 configmap 路径,就可以发现多机程序,进而去链接了。
3.5.6.1 getOrCreateConfigMap
这个是在 运行了 worker 之后才处理的,即 先运行 worker pod 了,然后在响应消息时候,再次调用 getOrCreateConfigMap 才会有运行的 worker pod 信息。
- 这里会先调用 updateDiscoverHostsInConfigMap 生成 discovery host 文件内容;
- 然后 newConfigMap 具体生成了 kubectl 的执行命令 和 host file,具体就是 hostfileName 和 kubexecScriptName;
// getOrCreateConfigMap gets the ConfigMap controlled by this MPIJob, or creates
// one if it doesn't exist.
func (c *MPIJobController) getOrCreateConfigMap(mpiJob *kubeflow.MPIJob, workerReplicas int32, isGPULauncher bool) (*corev1.ConfigMap, error) {
newCM := newConfigMap(mpiJob, workerReplicas, isGPULauncher)
podList, err := c.getRunningWorkerPods(mpiJob)
updateDiscoverHostsInConfigMap(newCM, mpiJob, podList, isGPULauncher)
cm, err := c.configMapLister.ConfigMaps(mpiJob.Namespace).Get(mpiJob.Name + configSuffix)
// If the ConfigMap doesn't exist, we'll create it.
if errors.IsNotFound(err) {
cm, err = c.kubeClient.CoreV1().ConfigMaps(mpiJob.Namespace).Create(newCM)
}
// If the ConfigMap is not controlled by this MPIJob resource, we
// should log a warning to the event recorder and return.
if !metav1.IsControlledBy(cm, mpiJob) {
msg := fmt.Sprintf(MessageResourceExists, cm.Name, cm.Kind)
c.recorder.Event(mpiJob, corev1.EventTypeWarning, ErrResourceExists, msg)
return nil, fmt.Errorf(msg)
}
// If the ConfigMap is changed, update it
if !reflect.DeepEqual(cm.Data, newCM.Data) {
cm, err = c.kubeClient.CoreV1().ConfigMaps(mpiJob.Namespace).Update(newCM)
}
return cm, nil
}
3.5.6.2 newConfigMap
newConfigMap 具体生成了 kubectl 的执行命令,之后可以通过 kubectl 来给 Worker 发送 mpirun 的命令。
// newConfigMap creates a new ConfigMap containing configurations for an MPIJob
// resource. It also sets the appropriate OwnerReferences on the resource so
// handleObject can discover the MPIJob resource that 'owns' it.
func newConfigMap(mpiJob *kubeflow.MPIJob, workerReplicas int32, isGPULauncher bool) *corev1.ConfigMap {
kubexec := fmt.Sprintf(`#!/bin/sh
set -x
POD_NAME=$1
shift
%s/kubectl exec ${POD_NAME}`, kubectlMountPath)
if len(mpiJob.Spec.MainContainer) > 0 {
kubexec = fmt.Sprintf("%s --container %s", kubexec, mpiJob.Spec.MainContainer)
}
kubexec = fmt.Sprintf("%s -- /bin/sh -c "$*"", kubexec)
// If no processing unit is specified, default to 1 slot.
slots := 1
if mpiJob.Spec.SlotsPerWorker != nil {
slots = int(*mpiJob.Spec.SlotsPerWorker)
}
var buffer bytes.Buffer
if isGPULauncher {
buffer.WriteString(fmt.Sprintf("%s%s slots=%d
", mpiJob.Name, launcherSuffix, slots))
}
for i := 0; i < int(workerReplicas); i++ {
buffer.WriteString(fmt.Sprintf("%s%s-%d slots=%d
", mpiJob.Name, workerSuffix, i, slots))
}
return &corev1.ConfigMap{
ObjectMeta: metav1.ObjectMeta{
Name: mpiJob.Name + configSuffix,
Namespace: mpiJob.Namespace,
Labels: map[string]string{
"app": mpiJob.Name,
},
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(mpiJob, kubeflow.SchemeGroupVersionKind),
},
},
Data: map[string]string{
hostfileName: buffer.String(),
kubexecScriptName: kubexec,
},
}
}
3.5.6.3 命令例子
生成的执行命令例子如下:
# Launcher 容器中执行的命令,就是给 Worker 下发 mpirun 的命令
/opt/kube/kubectl exec mpi-ea4304c32617ec5dvx89ht1et9-worker-0 -- /bin/sh -c PATH=/usr/local/bin:$PATH ; export PATH ; LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH ; export LD_LIBRARY_PATH ; DYLD_LIBRARY_PATH=/usr/local/lib:$DYLD_LIBRARY_PATH ; export DYLD_LIBRARY_PATH ; /usr/local/bin/orted -mca ess "env" -mca ess_base_jobid "2828599296" -mca ess_base_vpid 1 -mca ess_base_num_procs "2" -mca orte_node_regex "mpi-ea[4:4304]c32617ec5dvx89ht1et9-launcher-kljzn,mpi-ea[4:4304]c32617ec5dvx89ht1et9-worker-0@0(2)" -mca orte_hnp_uri "2828599296.0;tcp://6.16.105.7:36055" -mca plm "rsh" --tree-spawn -mca orte_parent_uri "2828599296.0;tcp://6.16.105.7:36055" -mca orte_default_hostfile "/etc/mpi/hostfile" -mca plm_rsh_agent "/etc/mpi/kubexec.sh" -mca hwloc_base_binding_policy "none" -mca rmaps_base_mapping_policy "slot" -mca pmix "^s1,s2,cray,isolated"
3.5.6.4 命令说明
有一个问题是:命令中为什么要有 -- 号
因为kubectl exec可以执行容器命令。
格式为:
kubectl exec -it <podName> -c <containerName> -n <namespace> -- shell comand
例如我们创建一个testfile文件:
kubectl exec -it <podname> -c <container name> -n <namespace> -- touch /usr/local/testfile
需要注意的是:
shell命令前,要加 -- 号,不然shell命令中的参数,不能识别。否则虽然执行了kubectl exec 命令,但后续的一些操作并没有在容器内执行,而是在本地执行了。
此时扩展如下:
+-----------------------------+ kubeflow.MPIJob
| MPIJobController |
| | +---> addMPIJob +------------+ +-------> runWorker +-------+
| | | | | |
| mpiJobInformer +--------+ v | |
| | | | v
| | +---------------------> enqueueMPIJob +---+ processNextWorkItem <--+
| | + +
| | | ^ |
| | | +--------------+ | |
| | +---> | | | |
| | | workqueue +-------+ |
| queue +-------------------------------------------------> | | v
| | +--------------+ syncHandler
| | +
| | |
| PodLister | getOrCreateConfigMap |
| | + v
| | | getOrCreateWorker +----> newWorker +----> Pod
| | | +
| serviceAccountInformer +-------> handleObject(ServiceAccount) v |
| | +-------+---------+ |
| | | newConfigMap | v
| roleInformer +-------------> handleObject(Role) | | +-------------+-----------------------------------+
| | | kubectl exec | | newLauncher |
| | | | | |
| roleBindingInformer +--------> handleObject(RoleBinding) +-------+---------+ | OMPI_MCA_plm_rsh_agent +---------> Pod
| | | | OMPI_MCA_orte_default_hostfile |
| | +----------> | kubexecScript hostfile discoverHostsScript |
| podInformer +--------------> handleObject(Pod) | |
| | +--------------------------+----------------------+
| | |
| podgroupsInformer +----------> handleObject(PodGroup) |
| | v
+-----------------------------+ updateMPIJobStatus
手机如下:

0x04 弹性训练
弹性训练应该是后来才加入的。我们尝试着梳理一下过程。
4.1 之前问题
此前,MPI-Operator 和 Elastic Horovod 存在几个兼容性上的问题。
- MPI-Operator 尚不提供
discover_hosts.sh,这一点直接导致 Elastic Horovod 无法使用 - 当用户将 worker replicas 调小之后,controller 不会对“额外”的 worker pod 采取任何措施,这会导致 worker pod 无法释放,训练任务的实例规模也就无法缩小
- 当用户增大 worker replica 后,controller 并不会为 launcher pod 的 Role 配置新增 worker 的执行权限,这会导致 launcher pod 上的 horovodrun 在试图利用
kubectl在新创建的 worker pod 上执行进程时被 Kubernetes 的权限管理机制拒绝
4.2 方案
以下应该是腾讯云团队提出的方案。
基于这些存在的兼容性问题,我们在社区上提出了 Elastic Horovod on MPIJob:https://github.com/kubeflow/mpi-operator/pull/335 。配合对 Horovod 的修改 https://github.com/horovod/horovod/pull/2199 ,能够在 Kubernetes 上实现 Horovod 的弹性训练。
在该方案中,最关键的问题在于如何在 launcher pod 上实现
discover_hosts.sh的功能。而在 Kubernetes 上实现该功能的关键,在于如何获取当前处在 Running 状态的 worker pods。这里有两种思路。1.MPIJob Controller 构建
discover_hosts.sh并通过 ConfigMap 同步至 launcher pod
- MPIJob Controller 本身就在监听 pods 相关的信息,利用 controller 内的 podLister,可以很快地列出每一个 MPIJob 的 worker pods;
- 根据 pods 的 status.phase,controller 在筛选出 Running 状态的 worker pods 之后,就可以构建出一份反映当前 worker pods 状态的
discover_hosts.sh;- 通过 ConfigMap,controller 可以将
discover_hosts.sh像hostfile、kubexec.sh脚本一样同步至 launcher pod。- 利用 launcher pod 内已有的
kubectl向 APIServer 实时获取 worker pod 信息2.Launcher pod 自身已经绑定了 pods 的 “get” 和 “list” 权限,通过 kubectl 或者其他 Kubernetes client 的直接调用,即可获取对应 pod 信息,通过一样的筛选标准也可以返回 Elastic Horovod 期待的信息。
考虑到第二种思路无法限制用户执行
discover_hosts.sh的频率,如果用户执行过于频繁或是 MPIJob 规模较大的情况下,会对 Kubernetes 集群造成较大的压力,第一种思路在管控上更为全面。一种对思路二的修正是将
kubectl或是 client 改为一个 podLister 运行在 launcher pod 中,从而降低对 APIServer 的压力。然而这种方式使得 launcher pod 中运行了两个进程。当这个 podLister 进程失效时,缺乏合适的机制将其重新拉起,会造成后续的弹性训练失效。因此,我们提议中选择了第一种思路,这样一来,controller 通过 ConfigMap 将
discover_hosts.sh同步至 launcher pod 内,并挂载于/etc/mpi/discover_hosts.sh下。同时,该提议中也对 controller 针对另外两个兼容性问题做了相应的修改。这些修改并不会影响到非 Elastic 模式的 MPI 任务,用户只需忽略discover_hosts.sh即可。当然这种方案也存在一定的问题。ConfigMap 同步至 launcher pod 存在一定的延迟。然而一方面,这个延迟时间是 Kubernetes 管理员可以进行调整的。另一方面相比整个训练所花的时间,同时也相比 Elastic Horovod 在重置上所花的时间,这一部分延迟也是可以接受的。
4.3 实现
4.3.1 定义
discoverHostsScriptName 具体定义在这里
const (
controllerAgentName = "mpi-job-controller"
configSuffix = "-config"
configVolumeName = "mpi-job-config"
configMountPath = "/etc/mpi"
kubexecScriptName = "kubexec.sh"
hostfileName = "hostfile"
discoverHostsScriptName = "discover_hosts.sh" // 这里
kubectlDeliveryName = "kubectl-delivery"
kubectlTargetDirEnv = "TARGET_DIR"
kubectlVolumeName = "mpi-job-kubectl"
kubectlMountPath = "/opt/kube"
launcher = "launcher"
worker = "worker"
launcherSuffix = "-launcher"
workerSuffix = "-worker"
gpuResourceNameSuffix = ".com/gpu"
labelGroupName = "group-name"
labelMPIJobName = "mpi-job-name"
labelMPIRoleType = "mpi-job-role"
initContainerCpu = "100m"
initContainerEphStorage = "5Gi"
initContainerMem = "512Mi"
)
4.2 代码
// updateDiscoverHostsInConfigMap updates the ConfigMap if the content of `discover_hosts.sh` changes.
func updateDiscoverHostsInConfigMap(configMap *corev1.ConfigMap, mpiJob *kubeflow.MPIJob, runningPods []*corev1.Pod, isGPULauncher bool) {
slots := 1
if mpiJob.Spec.SlotsPerWorker != nil {
slots = int(*mpiJob.Spec.SlotsPerWorker)
}
// Sort the slice of Pods to make sure the order of entries in `discover_hosts.sh` is maintained.
sort.Slice(runningPods, func(i, j int) bool {
return runningPods[i].Name < runningPods[j].Name
})
discoverHosts := "#!/bin/sh"
if isGPULauncher {
discoverHosts = fmt.Sprintf("%s
echo %s%s:%d
", discoverHosts, mpiJob.Name, launcherSuffix, slots)
}
for _, p := range runningPods {
discoverHosts = fmt.Sprintf("%s
echo %s:%d", discoverHosts, p.Name, slots)
}
oldDiscoverHosts, exist := configMap.Data[discoverHostsScriptName]
if exist {
if oldDiscoverHosts == discoverHosts {
return
}
}
configMap.Data[discoverHostsScriptName] = discoverHosts
}
具体更新 host 信息是在 getOrCreateConfigMap 之中。因为这时候知道了 pods 的信息变化,于是:
- 利用 controller 内的 podLister,可以很快地列出每一个 MPIJob 的 worker pods;
- 根据 pods 的 status.phase,controller 在筛选出 Running 状态的 worker pods 之后,就可以构建出一份反映当前 worker pods 状态的
discover_hosts.sh;
func (c *MPIJobController) getOrCreateConfigMap(mpiJob *kubeflow.MPIJob, workerReplicas int32, isGPULauncher bool) (*corev1.ConfigMap, error) {
newCM := newConfigMap(mpiJob, workerReplicas, isGPULauncher)
podList, err := c.getRunningWorkerPods(mpiJob)
updateDiscoverHostsInConfigMap(newCM, mpiJob, podList, isGPULauncher)
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,敬请关注。

0xFF 参考
tensorflow学习笔记(十九):分布式Tensorflow
在 Kubernetes 上弹性深度学习训练利器-Elastic Training Operator
像Google一样构建机器学习系统3 - 利用MPIJob运行ResNet101
揭秘|一探腾讯基于Kubeflow建立的多租户训练平台背后的技术架构
https://blog.csdn.net/weixin_43970890/article/details/113863716
在 Amazon EKS 上优化分布式深度学习性能的最佳实践
云原生的弹性 AI 训练系列之一:基于 AllReduce 的弹性分布式训练实践
通过shell执行kubectl exec并在对应pod容器内执行shell命令