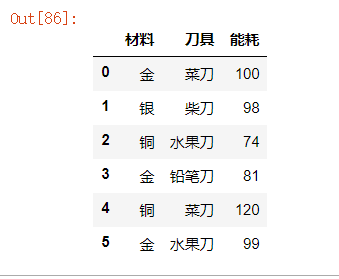
数据集为:
材料 刀具 能耗
金 菜刀 100
银 柴刀 98
铜 水果刀 74
金 铅笔刀 81
铜 菜刀 120
金 水果刀 99
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression from sklearn import preprocessing df = pd.read_csv('1.csv',encoding = 'gbk') df
cailiao = pd.get_dummies(df['材料']) #对材料进行onehot编码 daoju = pd.get_dummies(df['刀具']) #对刀具进行onehot编码 onehot = pd.concat([cailiao,daoju], axis=1) #用连接函数将数据合并 df = onehot.iloc[:,0:7].join(df) #将onehot数据加入原数据集 df.drop(['材料','刀具'],axis=1,inplace=True) #删除掉材料刀具这两列数据 df #打印

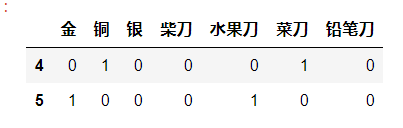
x_train = df.iloc[:4,0:-1] x_test = df.iloc[4:,0:-1] x_train

x_test
y_train = df.iloc[:4,-1]
y_train

另一种分割数据集的方式,使用sklearn中自带的分割函数:
from sklearn.model_selection import train_test_split x = df.iloc[:,0:-1] y = df.iloc[:,-1] x_tr,x_te,y_tr,y_te = train_test_split(x,y) x_tr
