算法原理
kmeans的计算方法如下:
1 随机选取k个中心点
2 遍历所有数据,将每个数据划分到最近的中心点中
3 计算每个聚类的平均值,并作为新的中心点
4 重复2-3,直到这k个中线点不再变化(收敛了),或执行了足够多的迭代
代码实现:
import cv2 import numpy as np import matplotlib.pyplot as plt %matplotlib inline image = cv2.imread('2.png') image_copy = np.copy(image) image_copy = cv2.cvtColor(image_copy,cv2.COLOR_BGR2RGB) plt.imshow(image_copy)

pixel_vals = image_copy.reshape((-1,3)) #第一个参数为-1时,那么reshape函数会根据另一个参数(这里是3)的维度计算出数组的shape属性值。 pixel_vals = np.float32(pixel_vals) #转化为浮点型,为k均值聚类做数据准备,因为 OpenCV 的函数 kmeans 需要这类数据 criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER,10,1.0) #经过几次迭代后,若簇移动的范围小于该值,则算法终止,实现收敛 k=3 #k值设为3 retval,labels,centers = cv2.kmeans(pixel_vals,k,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS) #二位数组,K的个数,标签(这里不需要),终止标准,迭代次数,初始中心点的选择方式 这里设为随机选择 centers = np.uint8(centers) seqmented_data = centers[labels.flatten()] seqmented_image = seqmented_data.reshape((image_copy.shape)) labels_reshape = labels.reshape(image_copy.shape[0],image_copy.shape[1]) plt.imshow(seqmented_image)
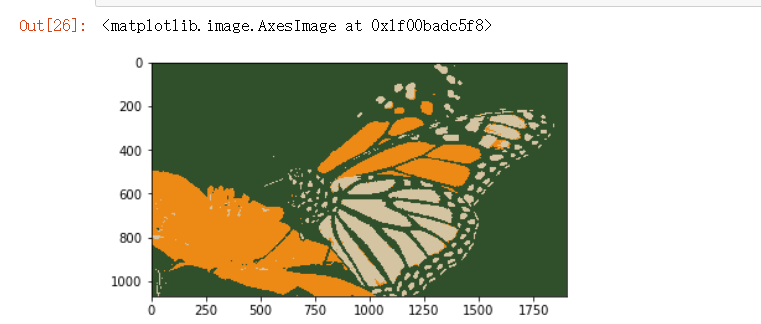
plt.imshow(labels_reshape == 1,cmap='gray')

masked_image = np.copy(image_copy) masked_image[labels_reshape == 1] = [0,0,0] plt.imshow(masked_image)
