内容概要
- 函数名
- 闭包
- 迭代器
- 生成器
- 推导式与表达式
- 内置函数
- 装饰器
- 初识递归
1、函数名
函数名的运用:
函数名是一个变量,但它是一个特殊的变量,与括号配合可以执行函数的变量。
01. 函数名的内存地址
def foo(): print("呵呵") print(foo) #执行结果: #<function foo at 0x0000000002208BF8>
02.函数名可以赋值给其他变量
def foo(): print("呵呵") print(foo) a = foo # 把函数当成一个变量赋值给另一个变量 a() # 函数调用 func() # 执行结果: # <function foo at 0x0000000002408BF8> # 呵呵
03. 函数名可以当做容器类的元素(列表、字典)
def func1(): print("func1") def func2(): print("func2") def func3(): print("func3") def func4(): print("func4") lst = [func1(),func2(),func3(),func4()] # 加()是调用函数,这样写会把函数返回值存到列表中 print(lst) # 执行结果: # func1 # func2 # func3 # func4 # [None, None, None, None] # 当成列表的元素 lst = [func1,func2,func3,func4] for i in lst: i() # 执行结果: # func1 # func2 # func3 # func4 # 当成字典的value dic = { 1:func1, 2:func2, 3:func3, 4:func4 } ret = input("请输入要执行的函数").strip() dic[int(ret)]()
04. 函数名可以当做函数的参数
def func(): print("吃了吗") def func2(fn): print("我是func2") fn() # 执行传递过来的fn print("我是func2") func2(func) # 把函数func当成参数传递到func2的参数fn
05. 函数名可以作为函数的返回值
def func_1(): print("这里是函数1") def func_2(): print("这里是函数2") print("这里是函数1") return func_2 fn = func_1() #执行函数1. 函数1返回的是函数2,这时fn指向的就是上面的函数2 fn() # 执行的是 func_2 => 在函数外面访问到了内部函数
2、闭包
什么是闭包?闭包就是内存函数,对外层函数(非全局)的变量的引用,叫闭包。
01. 闭包函数
def func1(): name = "lishichao" def func2(): # 闭包函数 print(name) # 内层函数,引用了外层函数的变量 func2() func1() #执行结果: # lishichao
02. 可以使用__closure__来检测函数是否是闭包. 使用函数名.__closure__返回cell就是闭包. 返回None就不是闭包
def func1(): name = "lishichao" def func2(): print(name) # 闭包 func2() print(func2.__closure__) #执行结果: (<cell at 0x0000000001E175E8: str object at 0x0000000001EA54F0>,) func1()
03. 在函数外边调用内部函数.
def outer(): name = "lishichao" #内部函数 def inner(): print(name) return inner fn = outer() # 访问外部函数,获取到内部函数的函数地址 fn() # 调用内部函数 inner # 也可以直接这样调用 outer()()
那如果多层嵌套呢? 很简单, 只需要一层一层的往外层返回就行了
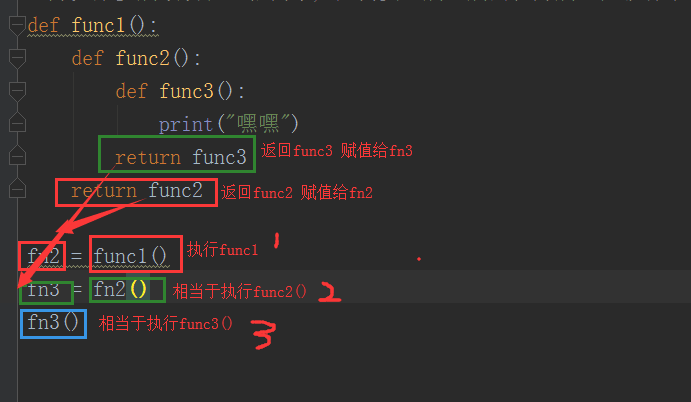
def func1(): def func2(): def func3(): print("嘿嘿") return func3 return func2 fn2 = func1() fn3 = fn2() fn3()
# 以上调用太麻烦了,可以直接加3个小括号调用 func1()()()
执行过程:
04. 闭包的好处是什么??
1. 可以保护你的变量不受侵害. 变量是一个局部变量
2. 可以让一个变量常驻内存. 被内部函数访问的变量会常驻内存.供后面的程序使用(如果不是闭包函数,函数在执行完毕,则这个函数中的变量以及局部命名空间中的内容都会被销毁)
闭包的应用:
# 导入可以发生请求的一个包 from urllib.request import urlopen # content = urlopen("https://www.dytt8.net/").read().decode("gbk") # print(content) # 网页源代码 # 后面的就是爬取数据了...... # 上面的网页内容: 1. 不能被随意的改动. 2. 内容每次都去网络请求 很慢 def but(): content = urlopen("https://www.dytt8.net/").read().decode("gbk") # 访问url内容,赋值给content变量 def get_content(): return content # 闭包 return get_content print("开始爬取内容") fn = but() print("爬取结束") print("第一次") content = fn() # 获取内容,数据都在内存中了 print(content) print("第二次") content2 = fn() # 重新获取内容 print(content2)
3、迭代器
之前说,能被for循环的都是可迭代对象,例如:
# 可以for循环: str, list, tuple, dict, set, range, open, # 不可以for循环: int, bool
dir() 函数可以查看xxx数据类型中可以执行那些操作。
s = "我的哈哈哈" print(dir(s)) # 可以打印对象中的方法和函数 print(dir(str)) # 也可以打印类中声明的方法和函数 # print(dir(list)) # 我们看到了__iter__ # print(dir(str)) # 我们看到了__iter__ # print(dir(range)) # 我们看到了__iter__ # f = open("test.txt", mode="w") # print(dir(f)) # 我们看到了__iter__
# 可以被for循环的都有 __iter__函数。
# print(dir(bool)) # 没有__iter__ # print(dir(int)) # 没有__iter__
迭代: iter
可迭代的里面有__iter__
不可迭代的里面没有__iter__
在打印结果中. 寻找__iter__ 如果能找到. 那么这个类的对象就是一个可迭代对象.
>>> print(dir(list)) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__',
'__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count',
'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
综上. 我们可以确定. 如果对象中有 __iter__ 函数. 那么我们认为这个对象遵守了可迭代协议.就可以获取到相应的迭代器. 这里的 __iter__ 是帮助我们获取到对象的迭代器. 我们使用迭代器中的 __next__() 来获取到一个迭代器中的元素。
lst = ["一个包子", "一碗粥", "一盘咸菜", "一同泡面"] it = lst.__iter__() # iterator 迭代器 print(it) # <list_iterator object at 0x0000000001E8C6D8> print(dir(it)) # __iter__ ==> 迭代器本身也是可以被迭代的 for i in it: print(i) __next__ : 获取迭代器中的元素,一直下一个 print(it.__next__()) print(it.__next__()) print(it.__next__()) print(it.__next__()) print(it.__next__()) # StopIteration # 停止迭代. 迭代器里没有元素了
for循环到底做了些什么?
- 获取迭代器
- 获取元素
- 处理异常
模拟for循环:
lst = ["白蛇", "密室逃生", "来电狂响", "天气预爆"] it = lst.__iter__() # 拿到迭代器 while 1: try: # 运行下面代码 el = it.__next__() print(el) except StopIteration: # 如果运行上面的代码,出现StopIteration这个异常,就运行下面的代码 break # 执行结果: # 白蛇 # 密室逃生 # 来电狂响 # 天气预爆
lst = list("张柏芝") # list()函数内部是要进行迭代的 list => for => 迭代器
print(lst)
结果: ['张', '柏', '芝']
用官方的办法来判断xxx数据是否是可迭代对象, 迭代器(isinstance函数)
Iterable: 可迭代的
Iterator: 迭代器
from collections import Iterable, Iterator lst = [1,2,3] print(isinstance(lst, Iterable)) # 判断xxx数据是否是xxx类型的 print(isinstance(lst, Iterator)) # 判断xxx数据是否是xxx类型的 it = lst.__iter__() print(isinstance(it, Iterable)) # 判断xxx数据是否是xxx类型的 print(isinstance(it, Iterator)) # 判断xxx数据是否是xxx类型的 f = open("扑了儿子", mode="r") print(isinstance(f, Iterator)) print(isinstance(f, Iterable))
总结:
Iterable: 可迭代对象. 内部包含__iter__()函数
Iterator: 迭代器. 内部包含__iter__() 同时包含__next__().
迭代器的特点::
- 节省内存.
- 惰性机制,不执行 __next__()不拿数据
- 不能反复, 只能向下执行.
lst = ["一个包子", "一碗粥", "一盘咸菜"] it = lst.__iter__() print(it.__next__()) print(it.__next__()) print(it.__next__()) # 拿光数据之后. 迭代器就废了,再拿回报错 it = lst.__iter__() # 想重新拿第一,只能重新拿到迭代器 print(it.__next__()) # 执行结果: # 一个包子 # 一碗粥 # 一盘咸菜 # 一个包子 # 一般不这么用迭代器 # 迭代器给for循环用的.
4、生成器
什么是生成成器. 生成成器实质就是迭代器.,在python中有二种方式来获取生成器:
1. 通过生成器函数
2. 通过生成器表达式来实现生成器
生成器函数:
def func(): print("111") return 222 ret = func() print(ret) #结果: # 111 # 222
# 将函数中的 return 换成 yield 就是生成器
def func(): print("111") yield 222 # yield 也代表返回,函数中如果有了yield就是一个生成器函数 print("333") yield 444 # 生成器函数运行的时候. 不会执行你的函数. 获取到一个生成器 ret = func() print(ret)
# 结果: # <generator object func at 0x0000000001E19CA8> # generator :生成器
由于函数中存在了yield. 那么这个函数就是一个生成器函数. 这个时候. 我们再执行这个函数的时候. 就不再是函数的执行了. 而是获取这个生成器。
如何使用呢? 想想迭代器. 生成器的本质是迭代器. 所以. 我们可以直接执行__next__()来执行。
以下生成器:
def func(): print("111") yield 222 gener = func() # 这个时候函数不会执行. 而是获取到生成器 ret = gener.__next__() # 这个时候函数才会执行. yield的作用和return一样. 也是返回数据 print(ret)
结果: 111 222
yield:
1. 把一个普通的函数变成生成器函数
2. 可以分段的把一个函数去运兴
def func(): print("111") yield 222 print("333") yield 444 gener = func() ret = gener.__next__() print(ret) ret2 = gener.__next__() print(ret2) ret3 = gener.__next__() # 生成器已经执行完毕. 不可以继续运行. StopIteration print(ret3) 执行结果: Traceback (most recent call last): File "E:/python-25期课上代码/day04/课上代码/04 生成器.py", line 41, in <module> ret3 = gener.__next__() StopIteration 111 222 333 444
当程序运行完最后一个yield. 那么后面继续进行__next__()程序会报错.
生成器有什么作用?
我们先看这样一个需求:你需要创建一个100000000万条数据的列表。
普通函数:
def order(): lst = [] for i in range(10000): lst.append(i) # 一次性创建10000条数据到内存中。 return lst lst = order() # 数据量很大. 存储是一个大问题 print(lst)
生成器函数:
# 大量的节省内存. 生成器内部保存的是代码. 不是数据 def order(): for i in range(10000): yield i gen = order() print(gen.__next__()) # 让生成器向下执行一次 print(gen.__next__()) print(gen.__next__()) print(gen.__next__()) for i in range(50): # 需要多少拿多少 print(gen.__next__())
send方法:
send 和 __next__() 一样都可以让生成器执行到下一个yield。
def eat(): print("我吃什么啊") a = yield "馒头" print("a =>",a) b = yield "饼" print("b =>",b) c = yield "菜盒" print("c=>",c) yield "GAME OVER" gen = eat() # 获取生成器 ret1 = gen.__next__() # 第一次执行生成器不能使用send(),因为它是给上一个yield传值,没有上一个yield。 print(ret1) ret2 = gen.send("胡辣汤") print(ret2) ret3 = gen.send("狗粮") print(ret3) ret4 = gen.send("猫粮") print(ret4) #执行结果: # 我吃什么啊 # 馒头 # a => 胡辣汤 # 饼 # b => 狗粮 # 菜盒 # c=> 猫粮 # GAME OVER
执行流程:
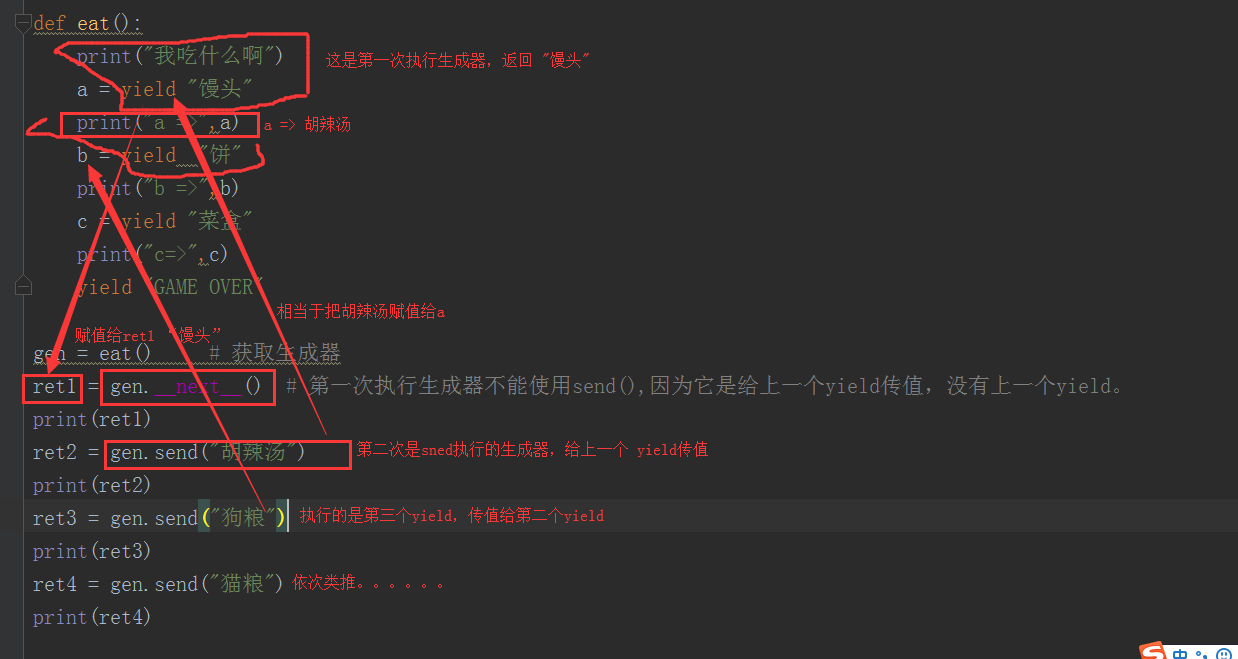
send和__next__()区别:
1. send 和 next() 都是让生成器向下走一次
2. send 可以给上一个yield的位置传递值, 不能给最后一个yield发送值. 在第一次执行生成器代码的时候不能使用send()
生成器也可以使用for循环来循环获取内部的元素:
def func1(): print("第一次") yield 111 print("第二次") yield 222 print("第三次") yield 333 gen = func1() for i in gen: print(i) # 执行结果: 第一次 111 第二次 222 第三次 333
5、推导式
创建一个列表. 里面放10000件衣服
lst = [] for i in range(10000): lst.append("衣服 %s" % i) print(lst)
列表推导式:lst = ["衣服 %s" % i for i in range(10000)] print(lst)
列表推导式是通过一行来构建你要的列表, 列表推导式看起来代码简单. 但是出现错误之后很难排查.
列表推导式的常用写法:
[ 结果 for 变量 in 可迭代对象]
筛选模式:
[ 结果 for 变量 in 可迭代对象 if 条件 ]
获取1-100内所有的偶数
lst = [i for i in range(1,100) if i % 2 ==0] print(lst)
生成器表达式和列表推导式的语法基本上是一样的. 只是把[]替换成()
gen = (i for i in range(10)) print(gen) # 结果: # <generator object <genexpr> at 0x00000000006D9CA8> # 打印的结果就是一个生成器. 可以使用for循环来循环这个生成器 for i in gen: print(i)
生成器表达式也可以进行筛选:
# 获取1-100内能被3整除的数 gen = (i for i in range(1,100) if i % 3 ==0) for num in gen: print(num) # 100以内能被3整除的数的平方 gen = (i * i for i in range(100) if i % 3 == 0) for num in gen: print(num) # 寻找名字中带有两个e的人的名字 names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']] # 不用推导式 result = [] for lst in names: for name in lst: if name.count("e") ==2: result.append(name) print(result) # 推导式 gen = [name for lst in names for name in lst if name.count("e") == 2] for name in gen: print(name)
执行流程:

生成器表达式和列表推导式的区别:
1. 列表推导式比较耗内存. 一次性加载. 生成器表达式几乎不占用内存(生成器里保存的是代码. 不是数据). 使用的时候才分配和使用内存
2. 得到的值不一样. 列表推导式得到的是一个列表. 生成器表达式获取的是一个生成器.
举个栗子.
同样一篮子鸡蛋. 列表推导式: 直接拿到一篮子鸡蛋. 生成器表达式: 拿到一个老母鸡. 需要鸡蛋就给你下鸡蛋.
生成器的惰性机制: 生成器只有在访问的时候才取值. 说白了. 你找他要他才给你值. 不找他要. 他是不会执行的.
def func(): # 生成器函数 print(111) yield 222 g = func() # 创建生成器 g1 = (i for i in g) # 生成器表达式, 没有人拿过数据. g1和g都是新的 g2 = (i for i in g1) # 生成器表达式, 没有人拿过数据. g1和g2, g都是新的 print(list(g)) # list => for => __iter__() => __next__() # list函数 内部有for循环机制 print(list(g1)) print(list(g2)) # 执行结果: # [222] # [] # []
字典推导式: {k:v for循环 if条件}
lst = ["莫丽清", "莫厉害", "魔力红", "魔力瘦"] dic = {i:lst[i] for i in range(len(lst))} print(dic)
集合推导式:
集合推导式可以帮我们直接生成一个集合. 集合的特点: 无序, 不重复. 所以集合推导式自带去重功能
dic = {} # key必须可哈希 dic[1] = "张无忌"
dic[1] = "赵敏" print(dic) # 集合 {} # 其实就是不存value的字典 s = set() s.add("胡辣汤") s.add("胡辣汤") s = {i for i in range(1,5,2)} print(s)
总结: 推导式有, 列表推导式, 字典推导式, 集合推导式, 没有元组推导式
生成器表达式: (结果 for 变量 in 可迭代对象 if 条件筛选)
生成器表达式可以直接获取到生成器对象. 生成器对象可以直接进行for循环. 生成器具有惰性机制.
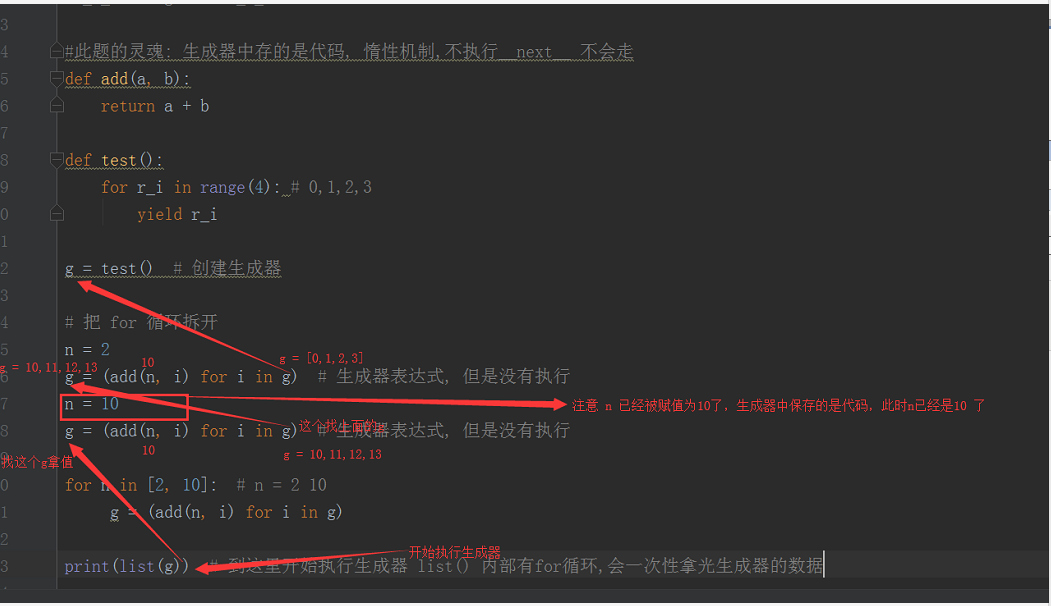
# 一个面试题. 难度系数500000000颗星:
# def add(a, b): # return a + b # # def test(): # for r_i in range(4): # yield r_i # # g = test() # # for n in [2, 10]: # g = (add(n, i) for i in g) # print(list(g)) #友情提: 惰性机制, 不到最后不会拿值
执行流程:
yield from:
在python3中提供了一种可以直接把可迭代对象中的每一个数据作为生成器的结果进行返回
def gen(): lst = ["麻花藤", "胡辣汤", "微星牌饼铛", "Mac牌锅铲"] yield from lst g = gen() for el in g: print(el)
yield from是将列表中的每一个元素返回. 所以. 如果写两个yield from 并不会产生交替的效果。
def gen(): lst = ["麻花藤", "胡辣汤"] lst2 = ["饼铛还是微星的好", "联想不能煮鸡蛋"] yield from lst yield from lst2 g = gen() for el in g: print(el)