一、知识总结:
1、什么是大数据
大数据是指无法在一定时间范围内用传统的计算机技术进行处理的海量数据集。
2、什么是Hadoop
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。
Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上运行或重新运行。此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。它使应用程序与成千上万的独立计算的计算机和PB级的数据连接起来。现在普遍认为整个Apache Hadoop“平台”包括Hadoop内核、MapReduce、Hadoop分布式文件系统(HDFS)以及一些相关项目,有Apache Hive和Apache HBase等等。
Hadoop里面包括几个重要组件HDFS、MapReduce和YARN。
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用,通俗说MapReduce是一套从海量源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
3、什么是数据仓库
数据仓库是为查询和分析而不是事务处理而设计的数据库。
数据仓库是通过整合不同的异构数据源而构建起来的。
数据仓库的存在使得企业或组织能够将整合、分析数据工作与事务处理工作分离。
数据能够被转换、整合为更高质量的信息来满足企业级用户不同层次的需求。
4、什么是zookeeper
Apache ZooKeeper是Apache软件基金会的一个软件项目,他为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。[需要解释] ZooKeeper曾经是Hadoop的一个子项目,但现在是一个独立的顶级项目。
ZooKeeper的架构通过冗余服务实现高可用性。因此,如果第一次无应答,客户端就可以询问另一台ZooKeeper主机。ZooKeeper节点将它们的数据存储于一个分层的命名空间,非常类似于一个文件系统或一个前缀树结构。
这是个万金油,安装Hadoop的HA的时候就会用到它,以后的Hbase也会用到它。它一般用来存放一些相互协作的信息,这些信息比较小一般不会超过1M,都是使用它的软件对它有依赖,对于我们个人来讲只需要把它安装正确,让它正常的run起来就可以了。
5、什么是Hbase
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以对稀疏文件提供极高的容错率。
HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。
这是Hadoop生态体系中的NOSQL数据库,他的数据是按照key和value的形式存储的并且key是唯一的,所以它能用来做数据的排重,它与MYSQL相比能存储的数据量大很多。所以他常被用于大数据处理完成之后的存储目的地。
6、Hive:这个东西对于会SQL语法的来说就是神器,它能让你处理大数据变的很简单,不会再费劲的编写MapReduce程序。有的人说Pig那?它和Pig差不多掌握一个就可以了。
7、Kafka:这是个比较好用的队列工具,队列是干什么的?排队买票你知道不?数据多了同样也需要排队处理,我们可以利用这个工具来做线上实时数据的入库或入HDFS,这时你可以与一个叫Flume的工具配合使用,它是专门用来提供对数据进行简单处理,并写到各种数据接受方的。
8、Spark:它是用来弥补基于MapReduce处理数据速度上的缺点,它的特点是把数据装载到内存中计算而不是去读慢的要死进化还特别慢的硬盘。特别适合做迭代运算,所以算法流们特别稀饭它。它是用scala编写的。Java语言或者Scala都可以操作它,因为它们都是用JVM的。
(1)Spark的Shuffle过程
在进行一个key对应的values的聚合时,首先,上一个stage的每个map task就必须保证将自己处理的当前分区中的数据相同key写入一个分区文件中,可能会多个不同的分区文件,接着下一个stage的reduce task就必须从上一个stage的所有task所在的节点上,将各个task写入的多个分区文件中找到属于自己的分区文件,然后将属于自己的分区数据拉取过来,这样就可以保证每个key对应的所有values都汇聚到一个节点上进行处理和聚合,这个过程就称之为shuffle!
shuffle操作,会导致大量的数据在不同的节点之间进行传输,因此,shuffle过程是Spark中最复杂、最消耗性能的一种操作
比如:reduceByKey算子会将上一个RDD中的每个key对应的所有value都聚合成一个value,然后生成一个新的RDD,新的RDD的元素类型就是<key, value>的格式,每个key对应一个聚合起来的value,在这里,最大的问题在于,对于上一个RDD来说,并不是一个key对应的所有的value都在一个partition中的,更不太可能key的所有value都在一个节点上,对于这种情况,就必须在集群中将各个节点上同一个key对应的values统一传输到一个节点上进行聚合处理,这个过程势必会发生大量的网络IO。
(2)一般的理解就是:Spark是基于内存的计算,而Hadoop是基于磁盘的计算;Spark是一种内存计算技术。
果真如此吗?事实上,不光Spark是内存计算,Hadoop其实也是内存计算。Spark和Hadoop的根本差异是多个任务之间的数据通信问题:Spark多个任务之间数据通信是基于内存,而Hadoop是基于磁盘。
Spark SQL比Hadoop Hive快,是有一定条件的,而且不是Spark SQL的引擎一定比Hive的引擎快,相反,Hive的HQL引擎还比Spark SQL的引擎更快。
Spark是允许我们利用缓存技术和LRU算法缓存数据的。Spark的所有运算并不是全部都在内存中,当shuffle发生的时候,数据同样是需要写入磁盘的。所以,Spark并不是基于内存的技术,而是使用了缓存机制的技术。
(3)Spark比Hadoop快的主要原因有:
1.消除了冗余的HDFS读写
Hadoop每次shuffle操作后,必须写到磁盘,而Spark在shuffle后不一定落盘,可以cache到内存中,以便迭代时使用。如果操作复杂,很多的shufle操作,那么Hadoop的读写IO时间会大大增加。
2.消除了冗余的MapReduce阶段
Hadoop的shuffle操作一定连着完整的MapReduce操作,冗余繁琐。而Spark基于RDD提供了丰富的算子操作,且reduce操作产生shuffle数据,可以缓存在内存中。
3.JVM的优化
Spark Task的启动时间快。Spark采用fork线程的方式,Spark每次MapReduce操作是基于线程的,只在启动。而Hadoop采用创建新的进程的方式,启动一个Task便会启动一次JVM。
Spark的Executor是启动一次JVM,内存的Task操作是在线程池内线程复用的。
每次启动JVM的时间可能就需要几秒甚至十几秒,那么当Task多了,这个时间Hadoop不知道比Spark慢了多少。
9、什么是ETL
ETL是Extract-Transform-Load的缩写(提取-转换-载入),是一个完整的从源系统提取数据,进行转换处理,载入至数据仓库的过程。
我们从联机事务数据库中提取数据,进行转换处理,匹配数据仓库模式,然后载入至数据仓库数据库中。
在通常情况下,大多数的数据仓库要整合非联机事务数据库系统的数据,例如来源文本文件、日志、电子表格等等。
下面我们一起看看ETL是怎么工作的。
例如一个公司,有关于其不同部门的数据记录,销售、市场、物流等等。每个部门所处理的客户信息是独立的,而且存储的数据也是相对不同的,假如销售团队有存储客户的姓名,而物流团队存储的是用户 的ID。
现在我们想要去检查客户的历史数据,并且想要了解他/她在不同的营销活动中购买的不同产品是什么。这将是一项非常枯燥的工作。
该解决方案就是使用数据仓库应用统一的结构来存储经过ETL处理过的不同源的数据。
ETL能够转换不同结构/类型的数据集为统一的结构,以便后续使用BI工具生成有意义的分析和表报。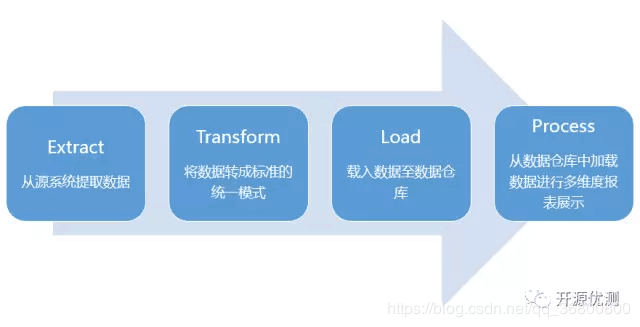
- Extract
(1)提取有效的数据 - Transform
(1)将提取的数据转换为数据仓库模式/格式
(2)构建keys:一个key是一个或多个数据属性的惟一标识实例,key的类型可以是主键(primary key)、外键(foreign key)、替代键(alternate key)、复合键(composite key)以及代理键(surrogate key)。这些key只允许数据仓库进行维护管理,且不允许其他任何实体进行分配。
(3)数据清理:在提取好数据后,则进入下一个节点:数据清理。对提取的数据中的错误进行标识和修复。解决不同数据集之间的不兼容的冲突问题,使数据一致性,以便数据集能用于目标数据仓库。通常,通过转换系统的处理,我们能创建一些元数据(meta data)来解决源数据的问题,并改进数据的质量。 - Load
(1)将转换后的数据载入数据仓库
(2)构建聚集:创建聚集对数据进行汇总并存储数据至表中,以改进终端用户的查询体验。
10、什么是BI?
BI(Business Intelligence)即商务智能,它是一套完整的解决方案,用来将企业中现有的数据(原始数据或商业数据或业务数据等)进行有效的整合,快速准确地提供报表并提出决策依据,帮助企业做出明智的业务经营决策。
原始数据记录了企业日常事务,例如与客户交互的信息、财务信息,员工相关记录等等。
这些数据可以用于汇报、分析、挖掘、数据质量、交互、预测分析等等。
二、大数据应用测试步骤
上面罗列了这么多,下面我们一起看看大数据应用的测试过程是怎么样的。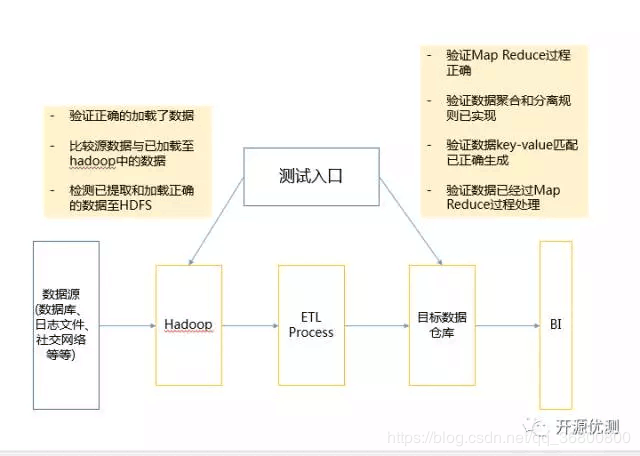
整体而言,大数据测试大体可以分为三大步骤:
步骤一,数据预处理验证
在进行大数据测试时,首先要预hadoop前验证数据的准确性等等。
我们数据来源可能是关系数据库、日志系统、社交我那个落等等,所有我们应该确保数据能正确的加载到系统中
我们要验证加载的数据和源数据是一致的
我们要确保正确的提取和加载数据至hdfs中
步骤二,Map Reduce验证 在进行大数据测试时,第二个关键步骤是“Map Reduce”验证。在本阶段,我们主要验证每一个处理节点的业务逻辑是否正确,并验证在多个运行后,确保:
Map Reduce过程工作正常
数据聚合、分离规则已经实现
数据key-value关系已正确生成
验证经过map reduce后数据的准确性等特性
步骤三,结果验证 在本阶段主要验证在经过大数据工具/框架处理后,生成的最终数据的成果。
主要验证:
验证数据转换规则是否正确应用
验证数据的完整性和是否成功持久化到目标系统
验证无数据损坏