Scala 语言特性
- Unit 表示无值, 等价于java, C++中的void
- Null 表示空值或空引用
- Nothing 所有其他类型的子类型, 表示没有值
- Any 所有类型的超类, 任何实例都属于Any类型
- AnyRef 所有引用类型的超类
- AnyVal 所有值类型的超类

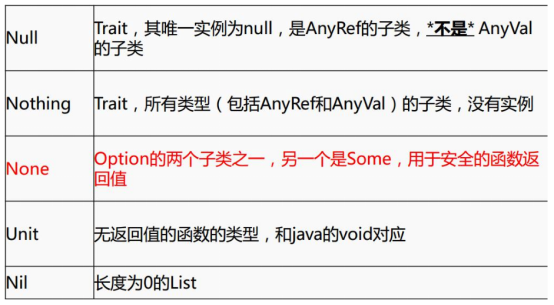
-
变量: var(variable) 可修改
-
常量: val(value) 不可修改
-
伴生类和伴生对象
package com.ronnie.hero /** 伴生类 名称必须一致, 与java不同的是构造器就跟在类名称之后 * 通过.调用, 不用写getter, setter * @param heroLevel * @param heroName */ class Hero(heroLevel : Int, heroName : String){ val name = heroName var hlevel = heroLevel var health = Hero.health + Hero.strength * 0.05 * heroLevel var armor = Hero.armor + Hero.agility * 0.167 * heroLevel var mana = Hero.mana + Hero.magic * 0.184 * heroLevel } /** 伴生对象 名称必须一致 * 是单例对象 */ object Hero { val health = 300 val mana = 170 val armor = 4 val agility = 50 val strength = 55 val magic = 47 def main(args: Array[String]): Unit = { val hero01 = new Hero(14, "slark") println("Name: " + hero01.name) println("Level: " + hero01.hlevel) println("Armor: " + hero01.armor) println("Health: " + hero01.health) println("Mana: " + hero01.mana) } }执行结果: Name: slark Level: 14 Armor: 120.89999999999999 Health: 338.5 Mana: 291.072 -
一些注意点:
-
l scala 中的object是单例对象,相当于java中的工具类,可以看成是定义静态的方法的类。object不可以传参数。另:Trait不可以传参数
-
scala中的class类默认可以传参数,默认的传参数就是默认的构造函数。
-
重写构造函数的时候,必须要调用默认的构造函数。
-
使用object时,不用new,使用class时要new ,并且new的时候,class中除了方法不执行,其他都执行。
-
如果在同一个文件中,object对象和class类的名称相同,则这个对象就是这个类的伴生对象,这个类就是这个对象的伴生类。可以互相访问私有变量。
-
-
to 和 until 用法(类似python中的range函数)
-
to 包含末尾数
-
until 不包含末尾数
-
可以指定步长, 默认为1
package com.ronnie.toAndUntil object toAndUntilDemo { def main(args: Array[String]): Unit = { println(1 to 10) println(1 until 10) // 1-9, 步长为2 println(1.to(9, 2) ) println(1 until(10, 2)) }
-
-
循环中可以加条件判断(写个简单的冒泡就知道了)
package com.ronnie.algorithum object BubbleSort { def sort(array: Array[Int]): Array[Int] = { // if 可以加在for循环中 for (i <- 0 until(array.length); j <- 0 until(array.length - i - 1); if (array(j) > array(j + 1))) { val temp = array(j) array(j) = array(j + 1) array(j + 1) = temp } array } def main(args: Array[String]): Unit = { val arr01 = Array[Int](3, 1, 2, 7, 4, 6) val result = sort(arr01) printArray(result) } def printArray(array: Array[Int]): Unit = { array.foreach(println) } }-
字符串API和java差不多
String 方法 char charAt(int index) 返回指定位置的字符 从0开始 int compareTo(Object o) 比较字符串与对象 int compareTo(String anotherString) 按字典顺序比较两个字符串 int compareToIgnoreCase(String str) 按字典顺序比较两个字符串,不考虑大小写 String concat(String str) 将指定字符串连接到此字符串的结尾 boolean contentEquals(StringBuffer sb) 将此字符串与指定的 StringBuffer 比较。 static String copyValueOf(char[] data) 返回指定数组中表示该字符序列的 String static String copyValueOf(char[] data, int offset, int count) 返回指定数组中表示该字符序列的 String boolean endsWith(String suffix) 测试此字符串是否以指定的后缀结束 boolean equals(Object anObject) 将此字符串与指定的对象比较 boolean equalsIgnoreCase(String anotherString) 将此 String 与另一个 String 比较,不考虑大小写 byte getBytes() 使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中 byte[] getBytes(String charsetName 使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中 void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) 将字符从此字符串复制到目标字符数组 int hashCode() 返回此字符串的哈希码 16 int indexOf(int ch) 返回指定字符在此字符串中第一次出现处的索引(输入的是ascii码值) int indexOf(int ch, int fromIndex) 返返回在此字符串中第一次出现指定字符处的索引,从指定的索引开始搜索 int indexOf(String str) 返回指定子字符串在此字符串中第一次出现处的索引 int indexOf(String str, int fromIndex) 返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始 String intern() 返回字符串对象的规范化表示形式 int lastIndexOf(int ch) 返回指定字符在此字符串中最后一次出现处的索引 int lastIndexOf(int ch, int fromIndex) 返回指定字符在此字符串中最后一次出现处的索引,从指定的索引处开始进行反向搜索 int lastIndexOf(String str) 返回指定子字符串在此字符串中最右边出现处的索引 int lastIndexOf(String str, int fromIndex) 返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索 int length() 返回此字符串的长度 boolean matches(String regex) 告知此字符串是否匹配给定的正则表达式 boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len) 测试两个字符串区域是否相等 28 boolean regionMatches(int toffset, String other, int ooffset, int len) 测试两个字符串区域是否相等 String replace(char oldChar, char newChar) 返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的 String replaceAll(String regex, String replacement 使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串 String replaceFirst(String regex, String replacement) 使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串 String[] split(String regex) 根据给定正则表达式的匹配拆分此字符串 String[] split(String regex, int limit) 根据匹配给定的正则表达式来拆分此字符串 boolean startsWith(String prefix) 测试此字符串是否以指定的前缀开始-
集合
-
数组 array
package com.ronnie.array object ArrayDemo { def main(args: Array[String]): Unit = { val arr = new Array[Array[String]](3) arr(0) = Array("slark", "spectre", "storm spirit") arr(1) = Array("anti-mage", "ember spirit", "huskar") arr(2) = Array("brood mother", "meepo", "visage") for (i <- 0 until arr.length; j <- 0 until arr(i).length){ print(arr(i)(j) + " ") } // 另一种遍历方式 arr.foreach{ arr => { arr.foreach(println) }} } }-
数组api
1 def apply( x: T, xs: T* ): Array[T] 创建指定对象 T 的数组, T 的值可以是 Unit, Double, Float, Long, Int, Char, Short, Byte, Boolean。 2 def concat[T]( xss: Array[T]* ): Array[T] 合并数组 3 def copy( src: AnyRef, srcPos: Int, dest: AnyRef, destPos: Int, length: Int ): Unit 复制一个数组到另一个数组上。相等于 Java's System.arraycopy(src, srcPos, dest, destPos, length)。 4 def empty[T]: Array[T] 返回长度为 0 的数组 5 def iterate[T]( start: T, len: Int )( f: (T) => T ): Array[T] 返回指定长度数组,每个数组元素为指定函数的返回值。 以上实例数组初始值为 0,长度为 3,计算函数为a=>a+1: scala> Array.iterate(0,3)(a=>a+1) res1: Array[Int] = Array(0, 1, 2) 6 def fill[T]( n: Int )(elem: => T): Array[T] 返回数组,长度为第一个参数指定,同时每个元素使用第二个参数进行填充。 7 def fill[T]( n1: Int, n2: Int )( elem: => T ): Array[Array[T]] 返回二数组,长度为第一个参数指定,同时每个元素使用第二个参数进行填充。 8 def ofDim[T]( n1: Int ): Array[T] 创建指定长度的数组 9 def ofDim[T]( n1: Int, n2: Int ): Array[Array[T]] 创建二维数组 10 def ofDim[T]( n1: Int, n2: Int, n3: Int ): Array[Array[Array[T]]] 创建三维数组 11 def range( start: Int, end: Int, step: Int ): Array[Int] 创建指定区间内的数组,step 为每个元素间的步长 12 def range( start: Int, end: Int ): Array[Int] 创建指定区间内的数组-
可变长数组(mutable array, 我记得cpp里也有mutable关键字)
package com.ronnie.array import scala.collection.mutable.ArrayBuffer object MutableArray { def main(args: Array[String]): Unit = { val arr = ArrayBuffer[String]("a", "m", "d") arr.append("y", "e", "s") // 在最后追加, 相当于append arr.+=("end") // 在最前面追加, 相当于preappend, 注意这个: arr.+=:("start") arr.foreach(println) } }
-
-
-
列表 list
-
长度为0时是nil
-
重要的几个方法
-
filter: 过滤元素
-
count: 计算符合条件的元素个数
-
map: 对元素操作
-
flapmap: 先map, 再进行flat操作(扁平化)
package com.ronnie.list object ListDemo { def main(args: Array[String]): Unit = { val list = List(2, 1, 4, 7, 6, 5) // 遍历 list.foreach{x => println(x)} // list.foreach(println) 同样可以, 有点像jdk1.8的 :: println("-------------------------------------------------------") /* filter */ val list01 = list.filter(x => x % 2 == 0) list01.foreach(println) // count val value01 = list.count(x => x % 2 != 0) println("奇数个数为: " + value01) // map val nameList = List("apache hadoop", "apache spark", "apache storm", "apache flink") val mapResult:List[Array[String]] = nameList.map{x => x.split(" ")} mapResult.foreach(println) // flatmap val flatMapResult:List[String] = nameList.flatMap{x => x.split(" ")} flatMapResult.foreach(println) } }
-
-
list api
1 def +(elem: A): List[A] 前置一个元素列表 2 def ::(x: A): List[A] 在这个列表的开头添加的元素。 3 def :::(prefix: List[A]): List[A] 增加了一个给定列表中该列表前面的元素。 4 def ::(x: A): List[A] 增加了一个元素x在列表的开头 5 def addString(b: StringBuilder): StringBuilder 追加列表的一个字符串生成器的所有元素。 6 def addString(b: StringBuilder, sep: String): StringBuilder 追加列表的使用分隔字符串一个字符串生成器的所有元素。 7 def apply(n: Int): A 选择通过其在列表中索引的元素 8 def contains(elem: Any): Boolean 测试该列表中是否包含一个给定值作为元素。 9 def copyToArray(xs: Array[A], start: Int, len: Int): Unit 列表的副本元件阵列。填充给定的数组xs与此列表中最多len个元素,在位置开始。 10 def distinct: List[A] 建立从列表中没有任何重复的元素的新列表。 11 def drop(n: Int): List[A] 返回除了第n个的所有元素。 12 def dropRight(n: Int): List[A] 返回除了最后的n个的元素 13 def dropWhile(p: (A) => Boolean): List[A] 丢弃满足谓词的元素最长前缀。 14 def endsWith[B](that: Seq[B]): Boolean 测试列表是否使用给定序列结束。 15 def equals(that: Any): Boolean equals方法的任意序列。比较该序列到某些其他对象。 16 def exists(p: (A) => Boolean): Boolean 测试谓词是否持有一些列表的元素。 17 def filter(p: (A) => Boolean): List[A] 返回列表满足谓词的所有元素。 18 def forall(p: (A) => Boolean): Boolean 测试谓词是否持有该列表中的所有元素。 19 def foreach(f: (A) => Unit): Unit 应用一个函数f以列表的所有元素。 20 def head: A 选择列表的第一个元素 21 def indexOf(elem: A, from: Int): Int 经过或在某些起始索引查找列表中的一些值第一次出现的索引。 22 def init: List[A] 返回除了最后的所有元素 23 def intersect(that: Seq[A]): List[A] 计算列表和另一序列之间的多重集交集。 24 def isEmpty: Boolean 测试列表是否为空 25 def iterator: Iterator[A] 创建一个新的迭代器中包含的可迭代对象中的所有元素 26 def last: A 返回最后一个元素 27 def lastIndexOf(elem: A, end: Int): Int 之前或在一个给定的最终指数查找的列表中的一些值最后一次出现的索引 28 def length: Int 返回列表的长度 29 def map[B](f: (A) => B): List[B] 通过应用函数以g这个列表中的所有元素构建一个新的集合 30 def max: A 查找最大的元素 31 def min: A 查找最小元素 32 def mkString: String 显示列表的字符串中的所有元素 33 def mkString(sep: String): String 显示的列表中的字符串中使用分隔串的所有元素 34 def reverse: List[A] 返回新列表,在相反的顺序元素 35 def sorted[B >: A]: List[A] 根据排序对列表进行排序 36 def startsWith[B](that: Seq[B], offset: Int): Boolean 测试该列表中是否包含给定的索引处的给定的序列 37 def sum: A 概括这个集合的元素 38 def tail: List[A] 返回除了第一的所有元素 39 def take(n: Int): List[A] 返回前n个元素 40 def takeRight(n: Int): List[A] 返回最后n个元素 41 def toArray: Array[A] 列表以一个数组变换 42 def toBuffer[B >: A]: Buffer[B] 列表以一个可变缓冲器转换 43 def toMap[T, U]: Map[T, U] 此列表的映射转换 44 def toSeq: Seq[A] 列表的序列转换 45 def toSet[B >: A]: Set[B] 列表到集合变换 46 def toString(): String 列表转换为字符串-
可变长度List
package com.ronnie.list import scala.collection.mutable.ListBuffer object MutableList { def main(args: Array[String]): Unit = { val listBuffer: ListBuffer[Int] = ListBuffer[Int](2,1,9,7,4,3) listBuffer.append(11, 10, 13) listBuffer.+= (222) listBuffer.+=:(111) listBuffer.foreach(println) } }
-
-
-
组 set
-
常用方法
- 取交集: intersect 或 &
- 取差集: diff, &~
- 取子集: subsetOf
- 最大: max
- 最小: min
- 转成数组: toArray
- 转成List: toList
- 转成字符串: mkString("~")
package com.ronnie.set object SetDemo { def main(args: Array[String]): Unit = { val set01 = Set(4, 7, 2, 6, 9, 10, 4) val set02 = Set(2, 4, 6) // 遍历,注意 set会自动去重 set01.foreach(println) println("===================================") for (s <- set02){ println(s) } println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~") // 取交集 val set03 = set01.intersect(set02) set03.foreach(println) val set04 = set01.&(set02) set04.foreach(println) println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~") // 取差集 set01.diff(set02).foreach(println) set01.&~(set02).foreach(println) println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~") // 子集 set01.subsetOf(set02) // 最大 println(set01.max) // 最小 println(set01.min) // 转array set01.toArray.foreach(println) // 转list set01.toList.foreach(println) // mkString println(set01.mkString) // 以什么为间隔 println(set01.mkString("-")) } } -
可变长度set
import scala.collection.mutable.Set object MutableSet { def main(args: Array[String]): Unit = { val set = Set[Int](2, 7, 1, 4, 6, 9) set.add(101) set.+= (201) set.+=(1,211,300) set.foreach(println) } }-
set api
1 def +(elem: A): Set[A] 为集合添加新元素,x并创建一个新的集合,除非元素已存在 2 def -(elem: A): Set[A] 移除集合中的元素,并创建一个新的集合 3 def contains(elem: A): Boolean 如果元素在集合中存在,返回 true,否则返回 false。 4 def &(that: Set[A]): Set[A] 返回两个集合的交集 5 def &~(that: Set[A]): Set[A] 返回两个集合的差集 6 def +(elem1: A, elem2: A, elems: A*): Set[A] 通过添加传入指定集合的元素创建一个新的不可变集合 7 def ++(elems: A): Set[A] 合并两个集合 8 def -(elem1: A, elem2: A, elems: A*): Set[A] 通过移除传入指定集合的元素创建一个新的不可变集合 9 def addString(b: StringBuilder): StringBuilder 将不可变集合的所有元素添加到字符串缓冲区 10 def addString(b: StringBuilder, sep: String): StringBuilder 将不可变集合的所有元素添加到字符串缓冲区,并使用指定的分隔符 11 def apply(elem: A) 检测集合中是否包含指定元素 12 def count(p: (A) => Boolean): Int 计算满足指定条件的集合元素个数 13 def copyToArray(xs: Array[A], start: Int, len: Int): Unit 复制不可变集合元素到数组 14 def diff(that: Set[A]): Set[A] 比较两个集合的差集 15 def drop(n: Int): Set[A]] 返回丢弃前n个元素新集合 16 def dropRight(n: Int): Set[A] 返回丢弃最后n个元素新集合 17 def dropWhile(p: (A) => Boolean): Set[A] 从左向右丢弃元素,直到条件p不成立 18 def equals(that: Any): Boolean equals 方法可用于任意序列。用于比较系列是否相等。 19 def exists(p: (A) => Boolean): Boolean 判断不可变集合中指定条件的元素是否存在。 20 def filter(p: (A) => Boolean): Set[A] 输出符合指定条件的所有不可变集合元素。 21 def find(p: (A) => Boolean): Option[A] 查找不可变集合中满足指定条件的第一个元素 22 def forall(p: (A) => Boolean): Boolean 查找不可变集合中满足指定条件的所有元素 23 def foreach(f: (A) => Unit): Unit 将函数应用到不可变集合的所有元素 24 def head: A 获取不可变集合的第一个元素 25 def init: Set[A] 返回所有元素,除了最后一个 26 def intersect(that: Set[A]): Set[A] 计算两个集合的交集 27 def isEmpty: Boolean 判断集合是否为空 28 def iterator: Iterator[A] 创建一个新的迭代器来迭代元素 29 def last: A 返回最后一个元素 30 def map[B](f: (A) => B): immutable.Set[B] 通过给定的方法将所有元素重新计算 31 def max: A 查找最大元素 32 def min: A 查找最小元素 33 def mkString: String 集合所有元素作为字符串显示 34 def mkString(sep: String): String 使用分隔符将集合所有元素作为字符串显示 35 def product: A 返回不可变集合中数字元素的积。 36 def size: Int 返回不可变集合元素的数量 37 def splitAt(n: Int): (Set[A], Set[A]) 把不可变集合拆分为两个容器,第一个由前 n 个元素组成,第二个由剩下的元素组成 38 def subsetOf(that: Set[A]): Boolean 如果集合A中含有子集B返回 true,否则返回false 39 def sum: A 返回不可变集合中所有数字元素之和 40 def tail: Set[A] 返回一个不可变集合中除了第一元素之外的其他元素 41 def take(n: Int): Set[A] 返回前 n 个元素 42 def takeRight(n: Int):Set[A] 返回后 n 个元素 43 def toArray: Array[A] 将集合转换为数组 44 def toBuffer[B >: A]: Buffer[B] 返回缓冲区,包含了不可变集合的所有元素 45 def toList: List[A] 返回 List,包含了不可变集合的所有元素 46 def toMap[T, U]: Map[T, U] 返回 Map,包含了不可变集合的所有元素 47 def toSeq: Seq[A] 返回 Seq,包含了不可变集合的所有元素 48 def toString(): String 返回一个字符串,以对象来表示
-
-
-
表 map
-
常用方法:
-
filter
-
count
-
contains
-
exist
package com.ronnie.map object MapDemo { def main(args: Array[String]): Unit = { // map合并 map1.++(map2) val map1 = Map((1,"Amd"),(2, "Intel"),(3, "Microsoft")) val map2 = Map((1, "Nvdia"),(2, "Sansung"),(3, "TSMC"),(4, "Ericsson"), (5, "Qualcomm")) map1.++(map2).foreach(println) println("================================") // count val countResult = map1.count(p => {p._2.equals("Intel")}) println(countResult) // filter map2.filter(_._2.equals("Sansung")).foreach(println) // contains println(map2.contains(4)) // exists println(map2.exists(f =>{ f._2.equals("Nvdia") })) } }
-
-
map api
1 def ++(xs: Map[(A, B)]): Map[A, B] 返回一个新的 Map,新的 Map xs 组成 2 def -(elem1: A, elem2: A, elems: A*): Map[A, B] 返回一个新的 Map, 移除 key 为 elem1, elem2 或其他 elems。 3 def --(xs: GTO[A]): Map[A, B] 返回一个新的 Map, 移除 xs 对象中对应的 key 4 def get(key: A): Option[B] 返回指定 key 的值 5 def iterator: Iterator[(A, B)] 创建新的迭代器,并输出 key/value 对 6 def addString(b: StringBuilder): StringBuilder 将 Map 中的所有元素附加到StringBuilder,可加入分隔符 7 def addString(b: StringBuilder, sep: String): StringBuilder 将 Map 中的所有元素附加到StringBuilder,可加入分隔符 8 def apply(key: A): B 返回指定键的值,如果不存在返回 Map 的默认方法 10 def clone(): Map[A, B] 从一个 Map 复制到另一个 Map 11 def contains(key: A): Boolean 如果 Map 中存在指定 key,返回 true,否则返回 false。 12 def copyToArray(xs: Array[(A, B)]): Unit 复制集合到数组 13 def count(p: ((A, B)) => Boolean): Int 计算满足指定条件的集合元素数量 14 def default(key: A): B 定义 Map 的默认值,在 key 不存在时返回。 15 def drop(n: Int): Map[A, B] 返回丢弃前n个元素新集合 16 def dropRight(n: Int): Map[A, B] 返回丢弃最后n个元素新集合 17 def dropWhile(p: ((A, B)) => Boolean): Map[A, B] 从左向右丢弃元素,直到条件p不成立 18 def empty: Map[A, B] 返回相同类型的空 Map 19 def equals(that: Any): Boolean 如果两个 Map 相等(key/value 均相等),返回true,否则返回false 20 def exists(p: ((A, B)) => Boolean): Boolean 判断集合中指定条件的元素是否存在 21 def filter(p: ((A, B))=> Boolean): Map[A, B] 返回满足指定条件的所有集合 22 def filterKeys(p: (A) => Boolean): Map[A, B] 返回符合指定条件的的不可变 Map 23 def find(p: ((A, B)) => Boolean): Option[(A, B)] 查找集合中满足指定条件的第一个元素 24 def foreach(f: ((A, B)) => Unit): Unit 将函数应用到集合的所有元素 25 def init: Map[A, B] 返回所有元素,除了最后一个 26 def isEmpty: Boolean 检测 Map 是否为空 27 def keys: Iterable[A] 返回所有的key/p> 28 def last: (A, B) 返回最后一个元素 29 def max: (A, B) 查找最大元素 30 def min: (A, B) 查找最小元素 31 def mkString: String 集合所有元素作为字符串显示 32 def product: (A, B) 返回集合中数字元素的积。 33 def remove(key: A): Option[B] 移除指定 key 34 def retain(p: (A, B) => Boolean): Map.this.type 如果符合满足条件的返回 true 35 def size: Int 返回 Map 元素的个数 36 def sum: (A, B) 返回集合中所有数字元素之和 37 def tail: Map[A, B] 返回一个集合中除了第一元素之外的其他元素 38 def take(n: Int): Map[A, B] 返回前 n 个元素 39 def takeRight(n: Int): Map[A, B] 返回后 n 个元素 40 def takeWhile(p: ((A, B)) => Boolean): Map[A, B] 返回满足指定条件的元素 41 def toArray: Array[(A, B)] 集合转数组 42 def toBuffer[B >: A]: Buffer[B] 返回缓冲区,包含了 Map 的所有元素 43 def toList: List[A] 返回 List,包含了 Map 的所有元素 44 def toSeq: Seq[A] 返回 Seq,包含了 Map 的所有元素 45 def toSet: Set[A] 返回 Set,包含了 Map 的所有元素 46 def toString(): String 返回字符串对象 -
可变长度Map
import scala.collection.mutable.Map object MutableMap { def main(args: Array[String]): Unit = { val map = Map[String, Int]() map.put("ronnie", 101) map.put("alex", 102) map.put("jogy", 103) map.foreach(println) } }
-
-
元组 tuple
-
与列表一样,与列表不同的是元组可以包含不同类型的元素。
-
元组的值是通过将单个的值包含在圆括号中构成的。
-
tuple最多支持22个参数
package com.ronnie.tuple object TupleDemo { def main(args: Array[String]): Unit = { //创建,最多支持22个 val tuple = Tuple1(1) val tuple2 = Tuple2("ronnie",2) val tuple3 = Tuple3(1,2,3) val tuple4 = (1,2,3,4) val tuple18 = Tuple18(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18) val tuple22 = Tuple22(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22) //使用 println(tuple2._1 + " "+tuple2._2) val t = Tuple2((1,2),("ronnie","yuan")) println(t._1._2) //遍历 val tupleIterator = tuple22.productIterator while(tupleIterator.hasNext){ println(tupleIterator.next()) } //翻转,只针对二元组 println(tuple2.swap) //toString println(tuple3.toString()) } }
-
-
-
Trait
-
类比java中的接口, 功能比接口更强
-
与接口不同的是,它还可以定义属性和方法的实现。
-
继承的多个trait中如果有同名的方法和属性,必须要在类中使用“override”重新定义。
-
trait中不可以传参数
package com.ronnie.traitDemo trait Read { val readType = "Read" val gender = "m" def read(name:String){ println(name+" is reading") } } trait Listen { val listenType = "Listen" val gender = "m" def listen(name:String){ println(name + " is listenning") } } class Person() extends Read with Listen{ override val gender = "f" } object test { def main(args: Array[String]): Unit = { val person = new Person() person.read("Sam") person.listen("Tracy") println(person.listenType) println(person.readType) println(person.gender) } }
-
-
模式匹配match
-
一个模式匹配包含了一系列备选项,每个都开始于关键字 case
-
每个备选项都包含了一个模式及一到多个表达式。
-
符号 => 隔开了模式和表达式。
-
注意点:
- 模式匹配不仅可以匹配值还可以匹配类型
- 从上到下顺序匹配,如果匹配到则不再往下匹配
- 都匹配不上时,会匹配到case _ ,相当于default
- match 的最外面的”{ }”可以去掉看成一个语句
package com.ronnie.matchDemo object Lesson_match { def main(args: Array[String]): Unit = { val tuple = Tuple6(1,2,3f,4,"abc",55d) val tupleIterator = tuple.productIterator while(tupleIterator.hasNext){ matchTest(tupleIterator.next()) } } /** * 注意点: * 1.模式匹配不仅可以匹配值,还可以匹配类型 * 2.模式匹配中,如果匹配到对应的类型或值,就不再继续往下匹配 * 3.模式匹配中,都匹配不上时,会匹配到 case _ ,相当于default */ def matchTest(x:Any) ={ x match { case x:Int=> println("type is Int") case 1 => println("result is 1") case 2 => println("result is 2") case 3=> println("result is 3") case 4 => println("result is 4") case x:String => println("type is String") // case x :Double => println("type is Double") case _ => println("no match") } } }
-
-
偏函数
-
如果一个方法中没有match 只有case,这个函数可以定义成PartialFunction偏函数。偏函数定义时,不能使用括号传参,默认定义PartialFunction中传入一个值,匹配上了对应的case,返回一个值,只能匹配同种类型。
package com.ronnie.partialFunction object Lesson_PartialFunction { def MyTest : PartialFunction[String, String] = { case "java" => {"java"} case "scala" => {"scala"} case "python" => {"python"} case "golang" => {"golang"} case _ => {"no match"} } def main(args: Array[String]): Unit = { println(MyTest("scala")) println(MyTest("java")) println(MyTest("python")) println(MyTest("golang")) println(MyTest("julia")) } }
-
-
样例类
-
使用了case关键字的类定义就是样例类(case classes)
-
样例类是种特殊的类。实现了类构造参数的getter方法(构造参数默认被声明为val),当构造参数是声明为var类型的,它将帮你实现setter和getter方法。
-
样例类默认帮你实现了toString,equals,copy和hashCode等方法。
-
样例类可以new, 也可以不用new
package com.ronnie.caseClasses case class Creature(xname:String, xage:Int){ val name = xname val age = xage } object Lesson_CaseClass { def main(args: Array[String]): Unit = { val seal = new Creature("bomb", 6) val penguin = new Creature("jojo", 7) val polar_fox = new Creature("dio", 8) val creatureList = List(seal, penguin, polar_fox) creatureList.foreach{x => { x match { case Creature("bomb",6) => println("bomb is coming") case Creature("jojo", 7) => println("欧拉欧拉欧拉") case Creature("dio", 8) => println("萝泽萝路哒!食我压路机啦,JOJO!") case _ => println("WTF is this?") } }} } }
-
-
隐式转换
-
隐式转换是在Scala编译器进行类型匹配时,如果找不到合适的类型,那么隐式转换会让编译器在作用范围内自动推导出来合适的类型。
-
隐式值与隐式参数
-
隐式值是指在定义参数时前面加上implicit。隐式参数是指在定义方法时,方法中的部分参数是由implicit修饰
-
必须使用柯里化的方式,将隐式参数写在后面的括号中
-
隐式转换作用就是:当调用方法时,不必手动传入方法中的隐式参数,Scala会自动在作用域范围内寻找隐式值自动传入。
-
隐式值和隐式参数注意点:
-
同类型的参数的隐式值只能在作用域内出现一次,同一个作用域内不能定义多个类型一样的隐式值。
-
implicit 关键字必须放在隐式参数定义的开头
-
一个方法只有一个参数是隐式转换参数时,那么可以直接定义implicit关键字修饰的参数,调用时直接创建类型不传入参数即可。
-
一个方法如果有多个参数,要实现部分参数的隐式转换,必须使用柯里化这种方式,隐式关键字出现在后面,只能出现一次
package com.ronnie.implicitDemo object Lesson_ImplicitValue { def Student(age: Int)(implicit name:String, i:Int)={ println(s"student :$name, age = $age, score = $i") } def Tutor(implicit name:String)={ println(s"Tutor's name: = $name") } def main(args: Array[String]): Unit = { implicit val fbk= "fubuki" implicit val mzlij = 100 Student(18) Tutor } }
-
-
隐式转换函数
-
隐式转换函数是使用关键字implicit修饰的方法。
-
当Scala运行时,假设如果A类型变量调用了method()这个方法,发现A类型的变量没有method()方法,而B类型有此method()方法,会在作用域中寻找有没有隐式转换函数将A类型转换成B类型
-
如果有隐式转换函数,那么A类型就可以调用method()这个方法
-
隐式转换函数注意点
- 隐式转换函数只与函数的参数类型和返回类型有关,与函数名称无关,所以作用域内不能有相同的参数类型和返回类型的不同名称隐式转换函数。
package com.ronnie.implicitDemo class Animal(name:String){ def canSwim():Unit={ println(s"$name can swim ...") } } class Lutra(xname:String){ val name = xname } object Lesson_ImplicitFunction { implicit def LutraToAnimal(lutra:Lutra):Animal = { new Animal(lutra.name) } def main(args: Array[String]): Unit = { val lutra = new Lutra("kano") lutra.canSwim() } }
-
-
隐式类
-
使用implicit关键字修饰的类就是隐式类。
-
若一个变量A没有某些方法或者某些变量时,而这个变量A可以调用某些方法或者某些变量时,可以定义一个隐式类,隐式类中定义这些方法或者变量,隐式类中传入A即可。
-
隐式类注意点:
-
-
隐式类必须定义在类,包对象,伴生对象中。
- 隐式类的构造必须只有一个参数,同一个类,包对象,伴生对象中不能出现同类型构造的隐式类。
package com.ronnie.implicitDemo class Elephant(s:String){ val name = s } object Lesson_ImplicitClass { implicit class Animal(elephant: Elephant){ val tp = "Animal" def canSleep()={ println(elephant.name + " can sleep ") } } def main(args: Array[String]): Unit = { val elephant = new Elephant("Elephant") elephant.canSleep() println(elephant.tp) } }
-
-
-
Actor模型
-
Actor Model是用来编写并行计算或分布式系统的高层次抽象(类似java中的Thread)让程序员不必为多线程模式下共享锁而烦恼,被用在Erlang 语言上, 高可用性99.9999999 % 一年只有31ms 宕机Actors将状态和行为封装在一个轻量的进程/线程中,但是不和其他Actors分享状态,每个Actors有自己的世界观,当需要和其他Actors交互时,通过发送事件和消息,发送是异步的,非堵塞的(fire-andforget),发送消息后不必等另外Actors回复,也不必暂停,每个Actors有自己的消息队列,进来的消息按先来后到排列,这就有很好的并发策略和可伸缩性,可以建立性能很好的事件驱动系统。
-
Actor特征:
-
ActorModel是消息传递模型,基本特征就是消息传递
-
消息发送是异步的,非阻塞的
-
消息一旦发送成功,不能修改
-
-
Actor之间传递时,自己决定决定去检查消息,而不是一直等待,是异步非阻塞的
-
这个demo用比较新的版本会报错因为:
Starting from Scala
2.10Scala Actors are moved to an external package (and deprecated in favour of Akka).从scala 2.10 开始Actors被移到了一个外部工具包, 而且在akka中已经过时
import scala.actors.Actor class myActor extends Actor{ def act(){ while(true){ receive { case x:String => println("save String ="+ x) case x:Int => println("save Int") case _ => println("save default") } } } } object Lesson_Actor { def main(args: Array[String]): Unit = { //创建actor的消息接收和传递 val actor =new myActor() //启动 actor.start() //发送消息写法 actor ! "i love you !" } }case class Message(actor:Actor,msg:Any) class Actor1 extends Actor{ def act(){ while(true){ receive{ case msg :Message => { println("i sava msg! = "+ msg.msg) msg.actor!"i love you too !" } case msg :String => println(msg) case _ => println("default msg!") } } } } class Actor2(actor :Actor) extends Actor{ actor ! Message(this,"i love you !") def act(){ while(true){ receive{ case msg :String => { if(msg.equals("i love you too !")){ println(msg) actor! "could we have a date !" } } case _ => println("default msg!") } } } } object Lesson_Actor2 { def main(args: Array[String]): Unit = { val actor1 = new Actor1() actor1.start() val actor2 = new Actor2(actor1) actor2.start() } } -
-
Akka
-
Akka 是一个用 Scala 编写的库,用于简化编写容错的、高可伸缩性的 Java 和Scala 的 Actor 模型应用,底层实现就是Actor,Akka是一个开发库和运行环境,可以用于构建高并发、分布式、可容错、事件驱动的基于JVM的应用。使构建高并发的分布式应用更加容易。
-
spark1.6版本之前,spark分布式节点之间的消息传递使用的就是Akka,底层也就是actor实现的。1.6及1.6之后使用的netty传输。
写个wordCount压压惊, 记得在pom.xml中导入spark坐标
-
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.rdd.RDD.rddToPairRDDFunctions object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setMaster("local").setAppName("WC") val sc = new SparkContext(conf) val lines :RDD[String] = sc.textFile("./words.txt") val word :RDD[String] = lines.flatMap{lines => { lines.split(" ") }} val pairs : RDD[(String,Int)] = word.map{ x => (x,1) } val result = pairs.reduceByKey{(a,b)=> {a+b}} result.sortBy(_._2,false).foreach(println) //简化写法 lines.flatMap { _.split(" ")}.map { (_,1)}.reduceByKey(_+_).foreach(println) } } -
-
-