a-如何创建函数。
b-给出一些指导原则,帮助思考如何创建和组织程序以使用函数。
c-如何编写函数,使随后可以询问它们的工作方式和实现的功能。
2.1将程序放在单独的文件里
为了更加方便,从现在开始,应当在python的代码编辑器中输入正在使用的程序,并将本书的事例放在一个文件中,以便以后引用和运行这个事例。一个可行的建议是将该目录命名为“Learning Python”,之后能够以程序出现的章节命名他们。
2.2函数:在一个名称下聚集代码
现代程序语言中提供来讲代码聚集在一个名称下的功能,无论何时使用,只要调用他们就行了。
为了创建一个包含代码的命名函数,可以使用def,它可以定义一个代码功能块。
我们定义一个函数:
def in_fridge(): try: count = fridge[wanted_food] except KeyError: count = 0 return count
当调用ch5.py时,如果其中只定义了in_fridge函数,这不会看到任何输出,然而,该函数将被定义,并且可以从已创建的交互式python会话中调用。
为了使用in_fridge函数,必须确保有一个包含各种食物名称的fridge字典,另外,必须有个名为wanted_food的字符串。使用in_fridge时,可以通过该字符串询问是否是有某种事物。
>>>fridge = {'apples':10,'orange':3,'milk':2}
>>>wanted_food = 'apples'
>>>in_fridge()
10
>>>wanted_food = 'orange'
>>>in_fridge()
3
这样可以减少工作量。在编写程序时,函数可以看作是一个一问一答的过程。因为当它们被调用的时候,经常会问它们一个问题,有多少个,什么时候,这个存在吗,这个可以改变吗等等。作为响应,函数会返回包含答案的值。
选择名称,给函数取好的名字,有利于回忆起他们的功能,即便是忘记代码实现,也没多大关系。
函数中描述函数
在选定函数名称后可以对函数添加一个描述,python可以用简单并且有意义的方式来完成这件事情。如果见一个字符串作为函数的第一部分内容,而没用名称引用它,python将他存储在函数中,以便以后引用。这个字符串通常叫做docstring(documentation string)。
函数的文档字符串用于描述函数,很少有计算机软件做了良好的说明。python提供了简单的文档字符串特性,相对于用缺乏友好和有帮助的约定的其他语言编写程序,python程序中有更多可用信息。
如:

文档字符通过函数中的名称引用,仿佛函数是字典一样。这个名称是_doc_。

函数还有其他信息(它保存的这组信息可以使用内置函数dir查看),dir显示你感兴趣的对象(例如函数)的所有属性,包括python内部使用的属性

不同位置相同名称:
(1)注意全局作用域。
(2)#注释
调用带参数的函数(不详细介绍)
检查参数
打算使用的参数类型可能与函数被调用时提供的类型不同,例如可能编写一个函数,期待一个字典参数,但是偶尔传进来一个列表,此时函数将一直运行,直到需要访问字典特有的运算。程序因为产生异常而退出。
python并不检查哪种类型的数据与函数的参数名称关联,大多数情况下,这不是问题,因为在给定的数据上的操作都是某个类型所特定的,如果名称引用的数据类型不正确,程序就不能正常工作了。
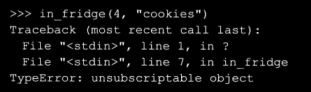
python在尝试将数值当作字典访问时,将引发一个except:捕捉不到错误。产生的typeerror错误表明python试图操作的类型做不了python期望它做的事情。
为了确认某些数据的类型,可以使用内置函数type,可以在函数开头部分验证变量类型。
def make_omelet(omelet_type): if type(omelet_type) == type({}): print("omelet_type is a dictionary with ingredients") return make_food(omelet_type,"omelet") elif type(omelet_type) == type(""): omelet_ingredients = get_omelet_ingredients(omelet_type) return make_food(omelet_ingredients,omelet_type) else: print("I dont think I can make this kind of omelet:%$"% omelet_type)
现在make_omelet的定义不能工作,因为它还依赖于其他几个没有编写的函数。
使用字符串比较类型
python中许多对象可以表示成字符串,许多对象内置的方法可以将他们转换成字符串
例如:
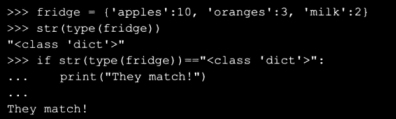
由于事先可以知道一个类型的字符串表示是什么样子,可以将那个字符串与一个通过str函数转换成字符串的对象进行比较。
在函数中调用其它函数
在顶层或者全局作用域声明的函数可以被其他函数以及其他包含的函数使用。全局作用域的名称可在任何地方使用,因为最有用的函数需要在其他函数中可用。
为了使make_omelet函数能像之前看到的那样工作,它依赖的其他函数应当可用,以便被make_omerlet使用。
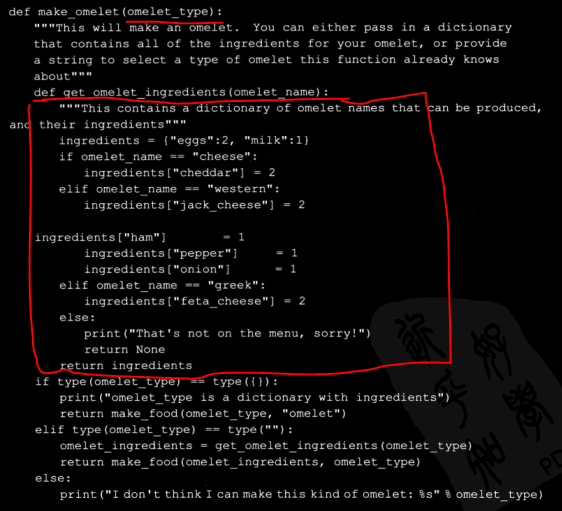
它的工作方式是L一个函数扮演了一个食谱的角色,它被给予一个指定煎蛋卷类型的字符串,并且返回一个包含所有成分及其分量的字典,该函数将被叫做get_omelet_ingredients,他需要一个参数,即为煎蛋卷的名称:
def get_omelet_ingredients(omelet_name): ingredients = {"eggs":2,"milk":1} if omelet_name == "cheese": ingredients["cheddar"] = 2 elif omelet_name == "westren": ingredients["jack_cheese"] = 2 ingredients["ham"] =1 ingredients["pepper"] =1 ingredients["onion"] =1 elif omelet_name == "greek": ingredients["feta_cheese"] =2 ingredients["spinach"] =2 else: print("thats not on the menu,sorry!") return None return ingredients
做煎蛋卷所需的第二个函数叫做make_food,它需要两个参数,第一个参数是包含所需成分的列表,这些成分完全从get_omelet_ingredients函数得来。第二个参数是食物名称,它应当是一种煎蛋卷的类型:
def make_food(ingredients_needed,food_name): for ingredient in ingredients_needed.keys(): print("adding %d of %s to make a %s"%(ingredients_needed[ingredient],ingredient,food_name)) print("made %s"% food_name) return food_name
现在可以使用make_omelet函数,他需要调用函数get_omelet_ingredients和make_food来完成工作。每个函数都提供了制作一个煎蛋卷的部分过程。
调用已完成的函数

所有函数已经就绪,可以被逐个调用,所以只需要指定希望制作的煎蛋卷的名称,然后就可以使用make_omelet了。
函数嵌套函数
使用函数之前定义函数非常重要,如果试图在定义一个函数之前就调用它,那么在调用时python不知道函数的存在,因此不能调用它!当然,这将导致一个错误并引起一个异常。因此,在文件开始定义函数,这样可以一直用到最后。
2.3函数的层次
我们来考虑它们的调用方式以及python如何记录调用层次非常有用。
当程序调用函数时,或者一个函数调用一个函数时,python在其内部创建一个叫做栈的列表,有时叫做调用栈。
当调用函数时,python将停止片刻,记住程序调用函数时所处的位置,之后将该信息贮藏在它的内部列表。之后进入函数并且执行它。下面这段代码记录如何进入和离开函数的:

在最上层python从第一行开始记录,之后当函数make_omelet在第64行被调用时对其进行记录,然后make_food被make_omelet调用,当make_food函数结束时,python确定它在第64行,于是返回第64行并继续执行,这个事例中的函数都是虚构的,但是您可以了解其中的意思。这个列表叫做栈,形象地表示出了进入函数的方式。可以想象直到退出时,一个函数位于栈顶部,当去掉它时,栈的长度缩减1.
如何解读深层的错误
假设传递一个包含列表而不是数值的字典,这将导致一个如下错误:
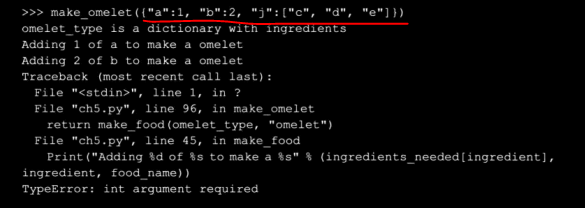
当文件进入一个函数后python将指出您在栈中的位置,(这意味着错误发生时有多少层以及栈中的每层在程序的哪一行被调用),因此可以打开有问题的文件来确认发生什么。
当调用更多的函数或者使用函数调用其它函数,创建了深层的栈时,就获得了使用栈跟踪(这是引发一个异常或者是一个错误时,python对输出使用的通用名称)的经验。前面的栈跟踪深度为3,可以看到在第45行,当调用make_food时,参数类型有问题。栈跟踪是栈的可读形式,可以检查他们来确认问题所在。