之前是不会想到登陆一个豆瓣会需要写三次博客,修改三次代码的。
本来昨天上午之前的代码用的挺好的,下午时候,我重新注册了一个号,怕豆瓣大号被封,想用小号爬,然后就开始出问题了,发现无法模拟登陆豆瓣了,开始想难道是账号的问题?就又修改成原来的账号和密码,发现仍然无法登陆
想不会这么衰吧,还没开始怕就被豆瓣封了?但是浏览器登录又没有任何问题,这个时候自己完全摸不着头脑,折腾了半天还是不能解决。
最后想起来有Fiddler 这个神器,就抓了一下request和response包,发现response headers里有一个Location,Raw文件里写着302 Found,一查,是链接被重定向了,Location里的就是新的重定向的链接,浏览器能够自动重定向,所以不会出问题,但是代码不会自动给你重定向。可是!!!!!蛋疼的是!!!我看了headers返回的Location链接!!!!不是和原来一毛一样吗!!!!!
傻逼的是又折腾了好久。。。结果!!!尼玛的链接竟然从http的变成了https的,我压根没留意到s的区别。。。浪费了我个吧小时- -#

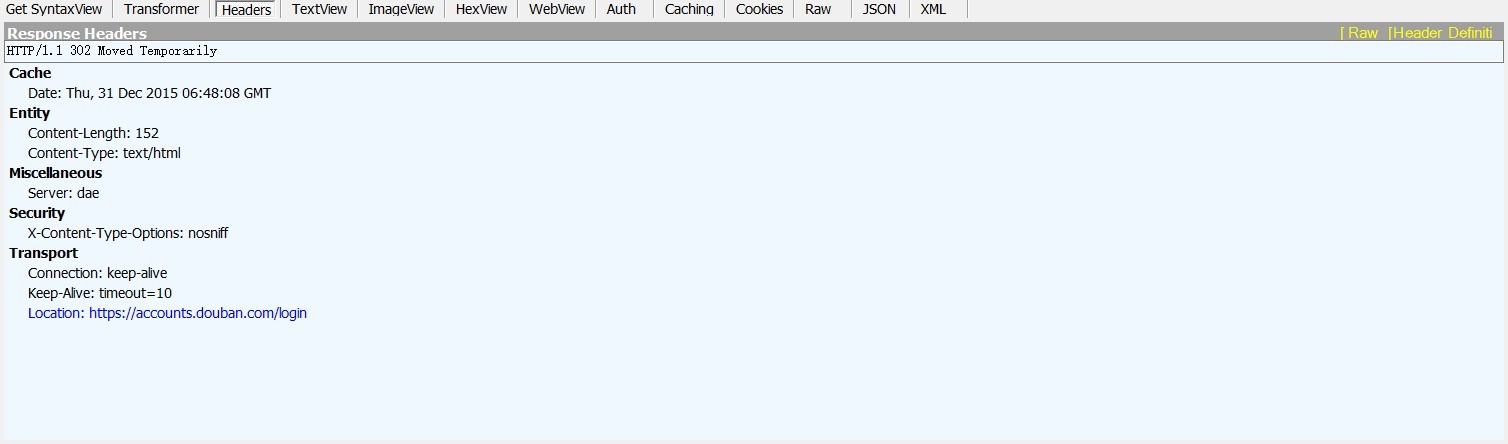
把链接都改为https以后,昨天能用了,但今天写的时候,突然又出error了,
captchaAddr = soup.find('img',id='captcha_image')['src'] line 28
TypeError: 'NoneType' object is not subscriptable
是find最后返回了一个None,这表示没有找到验证码的图片,这个就是豆瓣的一个机制,不一定要输入验证码,所以可以稍微修改一下代码,最后的代码如下:
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import urllib s = requests.Session() url1 = 'https://accounts.douban.com/login' url2 = 'https://www.douban.com/people/****/contacts' formdata={ "redir":"https://www.douban.com/", "form_email":"your email", "form_password":"your password", #'captcha-solution':'blood', #'captcha-id':'cRPGXEYPFHjkfv3u7K4Pm0v1:en', "login":u"登录" } headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36", #"Location": "https://accounts.douban.com/login" } r1 = s.post(url1,data=formdata,headers=headers) rcontent = r1.text soup = BeautifulSoup(rcontent,"html5lib") #安装了html5lib没用python本身的html解析库 captchaAddr = soup.find('img',id='captcha_image')['src'] if captchaAddr != None: reCaptchaID = r'<input type="hidden" name="captcha-id" value="(.*?)"/' captchaID = re.findall(reCaptchaID,rcontent) print(captchaID) urllib.request.urlretrieve(captchaAddr,"captcha.jpg") captcha = input('please input the captcha:') formdata['captcha-solution'] = captcha formdata['captcha-id'] = captchaID r1 = s.post(url1,data=formdata,headers=headers) r2 = s.get(url2) f = open('spider2.txt','w',encoding='utf-8') f.write(r1.text) f.close()