一、概述
①Flume最早是由Cloudera提供的日志收集系统,后贡献给apache。
②Flume是一个高可用、高可靠、健壮性,分布式的海量日志采集、聚合和传输的系统。
③Flume支持在日志系统中定制各类数据发送方,用于收集数据(source)。
④Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力(sink)。
二、版本历史
①Flume0.9X:又称Flume-og,老版本的flume,需要引入zookeeper集群管理,性能比较低(单线程工作)。
②Flume1.X:又称Flume-ng,新版本的flume,需要引入zookeeper,和flume-og不兼容。
三、Flume特性
①可靠性:事务型的数据传递,保证数据的可靠性。一个日志交给flume来处理,不会出现日志丢失或未被处理的情况。
②可恢复性:通道可以以内存或文件的方式实现,内存更快,但不可恢复。文件方式较慢但提供了可恢复性。
四、Flume的总体架构
Flume的apache官网地址:http://flume.apache.org/
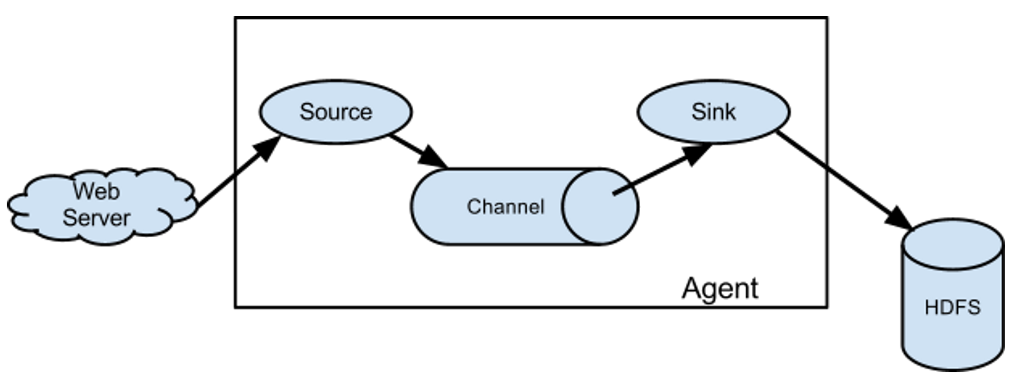
(1)event事件
①Flume的核心:把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的数据一定成功,在送到目的地之前,会缓存数据(Channel),待数据真正到底目的地(sink)之后,flume会删除缓存的数据。
②在整个数据的传输过程中,流动的是event,即事务保证是在event级别进行。event将传输的数据进行封装,是flume传输数据的基本单位。例如:文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
简而言之,在Flume中,每条日志都会封装成一个event对象。
③一个完整的event包括:even headers、event body、event信息(即文本文件的单行记录等)如下记录:

(2)Flume的运行机制
①Flume的运行核心就是agent,agent就是一个java进程。
②agent包含3个核心组件:source--->channel--->sink,类似于生产者、仓库、消费者的架构。
③source:专门用来收集数据,可以处理各种类型、各种格式的日志数据,包括:avro、thrift、exec、spooling、directory、netcat、http、自定义等等。
④channle:source把数据收集过来以后,临时存放在channel中,即channel组件在agent中是专门用来存放数据的,简而言之,就是对采集到的数据进行简单的缓存,可以存放在memory、file、jdbc等。
⑤sink:用于把数据发送到指定目的地,目的地包括:hdfs、avro、thrift、hbase、自定义等等。
⑥完整的工作流程:source不断采集数据,将数据封装成一个一个的event,然后将event发送给channel,channel作为一个缓冲区会临时存放这些event数据,随后sink会将channel的event数据发送到指定的目的地----例如:hdfs等
⑦注:只有在sink将channel中的数据发送成功出去之后,channel才会将临时event数据进行删除,这种机制保证了数据传输的可靠性和安全性。
五、Flume的复杂流动
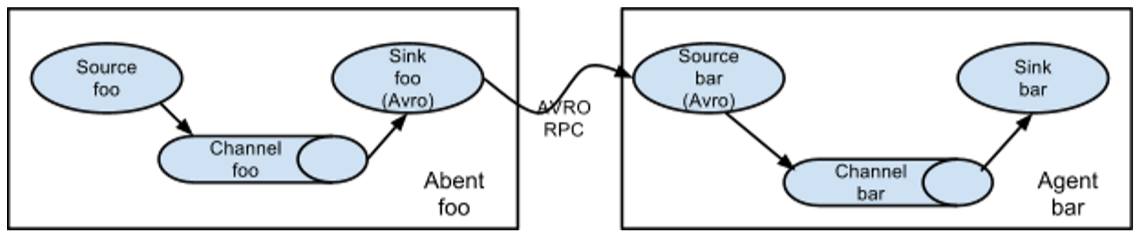
(1)多个agent(source-->channel-->sink)的多级流动
(2)数据合并流(扇入流)
在日志收集时一个非常常见的场景:大量生产日志的客户端发送数据至少量的附属与存储子系统的消费者agent。例如:从数百个web服务器收集日志,它们发送数据到十几个负责将数据写入HDFS集群的agent。
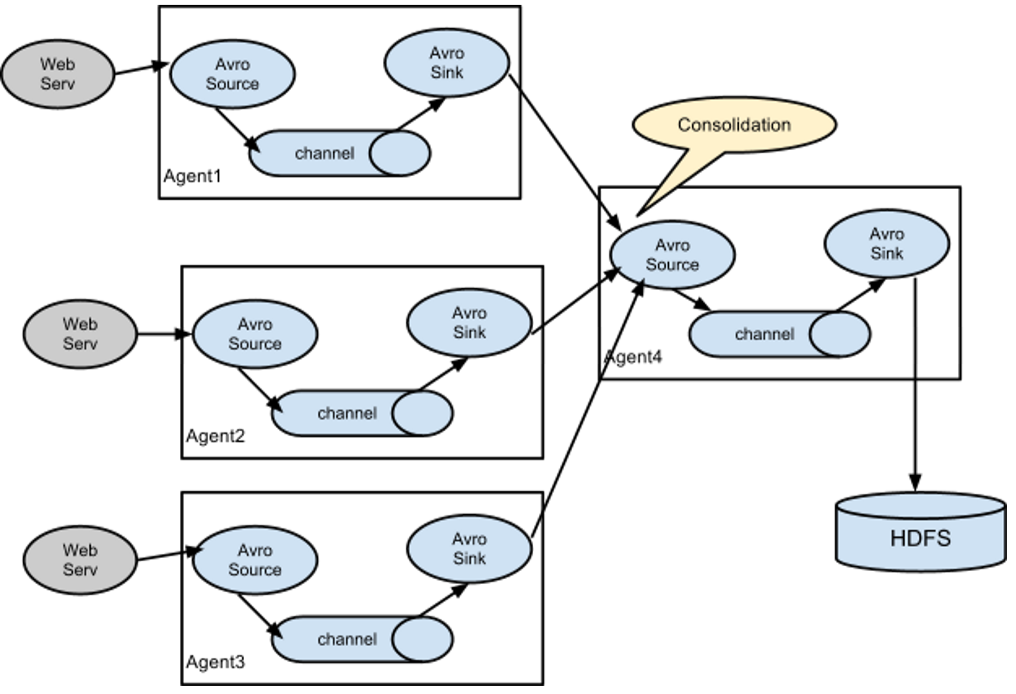
在此场景下:需要配置大量的第一层agent,每一个agent都有一个avro sink,都指向同一个avro source(当然也可以使用thrift等),在第二层agent上的source将收到的event合并到channel中,event将被sink消费到最终目的地。
(2)数据流复用(扇出流)
Flume支持多路输出event流到一个或多个目的地。
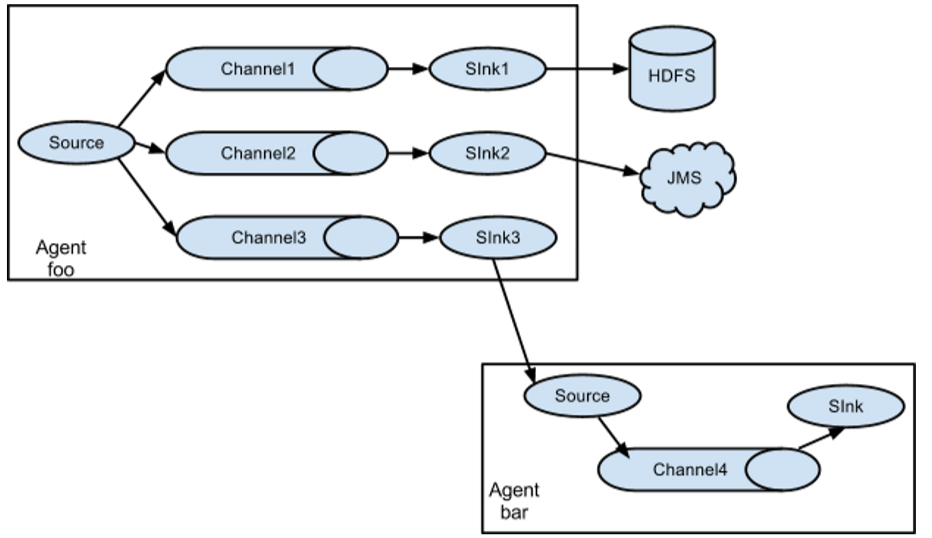
上述例子:source扇出数据流到三个不同的channel,这个扇出可以是复制或者多路输出。在复制数据流的情况下,每个event被发送所有的channel;在多路输出的情况下,一个event可以被发送到一部分可用的channel中,它们是根据event的属性和预先配置的值选择channel的,这些映射关系应该被填写在agent的配置文件中。
六、Flume的事务机制
(1)概述
①flume的事务机制与可靠性保证的实现,最核心的组件就是Channel(通道)。
②文件通道指的是将事件储存到agent本地文件系统中的通道。虽然比内存通道要慢一些,但是它提供了持久化的存储路径,可以应对大多数情况,它应用在数据流中不允许出现缺口的场合。
③File Channel虽然提供了持久化,但是性能比较差,吞吐量会受到一定的限制。相反,Memory Channel则牺牲可靠性换取吞吐量。当然,如果机器断电重启,则无法恢复。然而在实际应用中,大多数都选择内存通道,因为在通过flume收集海量数据的情况下,File Channel所带来的性能下降是很大甚至是无法忍受的。
(2)put事务流程(source与channel之间)
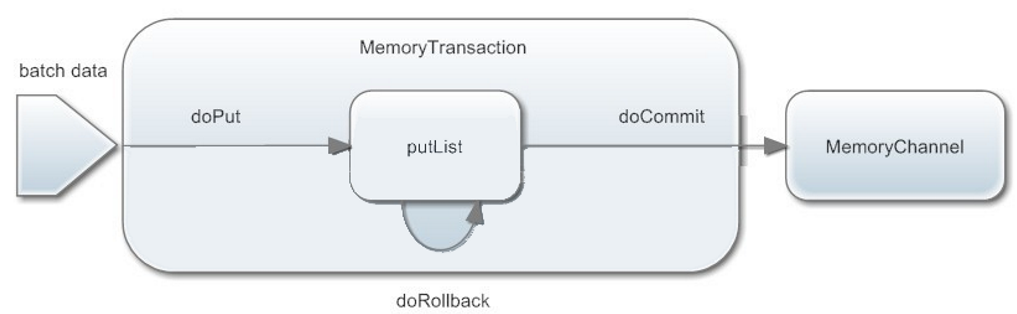
①doPut:将批量数据先写入临时缓冲区putList(本质是LinkedBlockingdequeue)
②doCommit:检查Channel内存队列是否足够合并
③doRollback:channel内存队列空间不足,回滚,等待内存通道的容量满足合并
④putList就是一个临时的缓冲区,数据会先put到putList,最后由doCommit方法会检查channel是否有足够的缓冲区,有则合并到channel队列
(3)take事务流程(channel与sink之间)
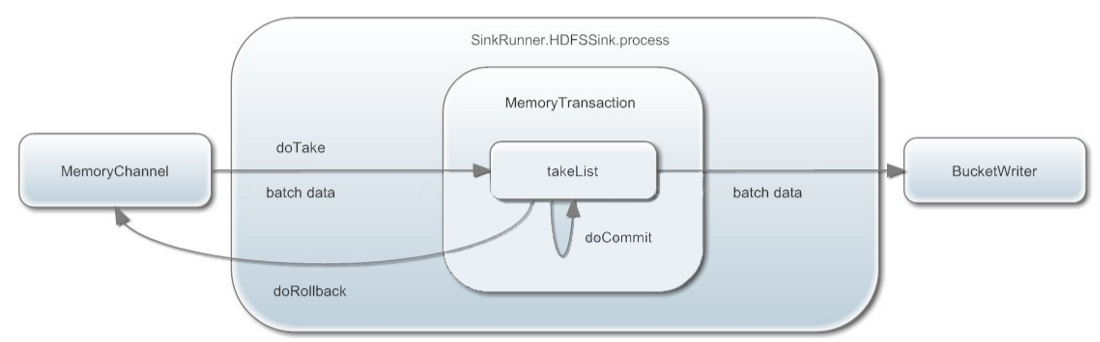
①doTake:先将数据提取到临时缓冲区(本质是linkedBlockingDequeue)
②将数据发往下一个节点
③doCommit:如果数据全部发送成功,则清除临时缓冲区内容takeList
④doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takelist中的数据归还给channel内存队列。
七、Flume的安装
(1)安装JDK
下载JDK:https://download.oracle.com/otn/java/jdk/8u221-b11/230deb18db3e4014bb8e3e8324f81b43/jdk-8u221-linux-x64.tar.gz
解压JDK:tar -xvf jdk-8u221-linux-x64.tar.gz
配置环境变量:vim /etc/profile,添加如下配置:,保存退出后,source /etc/profile使配置生效
#java环境变量
JAVA_HOME=/home/software/jdk1.8
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME PATH CLASSPATH
(2)安装nc
yum install -y nc
(3)下载安装Flume
下载地址:http://flume.apache.org/download.html
解压安装包:tar -xvf xxx.tar.gz
进入conf目录,创建一个配置文件,例如test.conf(前后缀都可以不固定):
#配置Agent a1 的组件
a1.sources=r1
a1.channels=c1
a1.sinks=s1
#描述/配置a1的r1
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
#描述a1的s1
a1.sinks.s1.type=logger
#描述a1的c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#为channel 绑定 source和sink
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
注意:channel与sink之间是一对一的。
(4)启动Flume
进入bin目录执行一下命令:
./flume-ng agent -n a1 -c ../conf -f ../conf/test.conf -Dflume.root.logger=INFO,console

出现上述说明flume启动成功,此时新建一个窗口如下命令:

刚刚启动的窗口会查看到flume收集到的日志:
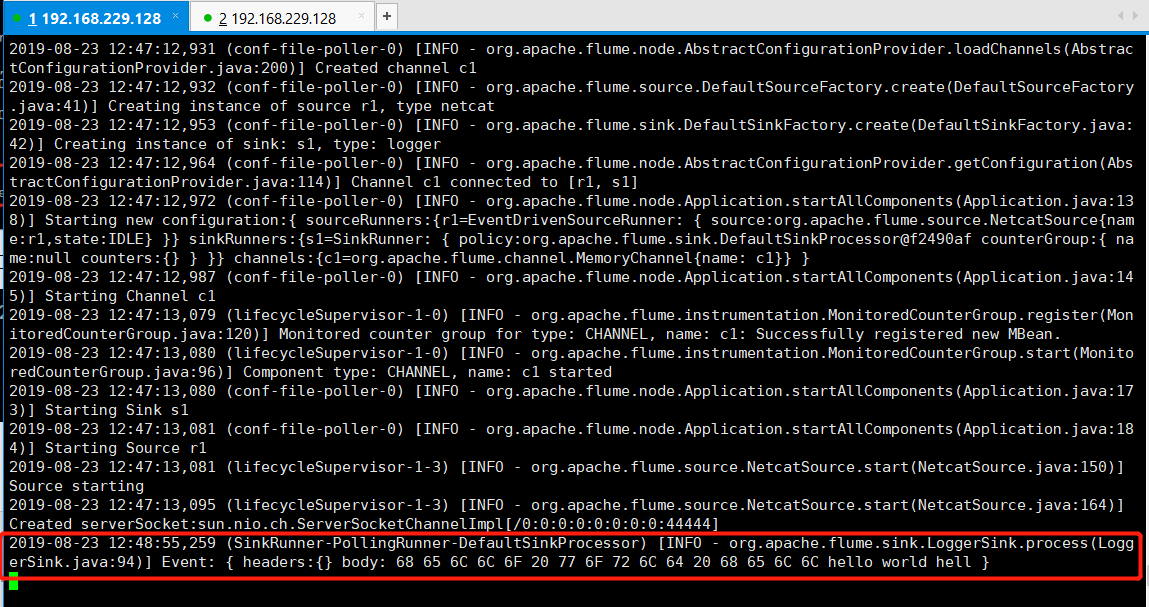
至此,Flume的安装已经完成!