由于目前在工作中一直用的dom4j+反射实现bean与xml的相互转换,记录一下,如果有不正确的地方欢迎大家指正~~~
一、反射机制
在此工具类中使用到了反射技术,所以提前也看了一些知识点,例如:http://www.51gjie.com/java/82(这里面有大量的例子可以学习)
二、dom4j
dom4j会将整个xml加载至内存,并解析成一个document对象,但是可能会造成内存溢出现象。
Document:表示整个xml文档。文档Document对象是通常被称为DOM树。
Element:表示一个xml元素。Element对象有方法来操作其子元素,它的文本,属性和名称空间
Attribute:表示元素的属性。属性有方法来获取和设置属性的值。它有父节点和属性类型。
Node:代表元素,属性或者处理指令。
三、dom4j读取xml
读取xml文档主要依赖于org.dom4j.io包,翻看其中源码可以看出提供DOMReader、SaxReader、XPPReader、XPP3Reader,我这里主要查看了SaxReader源码,其他的没有深入看过,所以使用SaxReader。
/** * 将xml字符串转换为Document对象 * @param xml * @return */ public Document getDocumentByString(String xml) { //1.字符串输入流 StringReader stringReader = new StringReader(xml); //2.获取解析器 SAXReader saxReader = new SAXReader(); //3.声明document对象 Document document = null; try { //4.解析xml,生成document对象 document = saxReader.read(stringReader); } catch (DocumentException e) { log.error("xml解析失败",e); } return document; }
四、bean与xml的互转方法
我这里测试案例,查询学生学校信息,返回学校及多个学生信息。如下准备:
1.准备bean
请求实体bean:ReqSchool.java
public class ReqSchool { //学校编号 private String number; //学校名称 private String name; //学校省份 private String province; //学校地址 private String address; //学生班级 private String stuclass; //学生姓名 private String stuname; //学生分数 private String stuscore; //省略set和get方法 }
响应实体bean:RspSchool.java
public class RspSchool { //学校编号 private String number; //学校名称 private String name; //学校省份 private String province; //学校地址 private String address; //多个学生 private List<Student> students; //模拟测试数据,返回多个学生 //省略get和set方法 }
响应实体bean的泛型:RspStudent.java
public class RspStudent { //学生班级 private String stuclass; //学生姓名 private String stuname; //学生分数 private String stuscore; //省略set和get方法 }
2.准备xml
①请求模版requestXML
这里以${元素名}作为请求模版,也可以修改工具类进行改造。
<?xml version="1.0" encoding = "GBK"?> <SCHOOL> <Head> <number>${number}</number> <name>${name}</name> <province>${province}</province> <address>${address}</address> </Head> <Body> <stuclass>${stuclass}</stuclass> <stuname>${stuname}</stuname> <stuscore>${stuscore}</stuscore> </Body> </SCHOOL>
②响应responseXML
<?xml version="1.0" encoding = "GBK"?> <SCHOOL> <Head> <number>0001</number> <name>xxx实验小学</name> <province>北京市</province> <address>西城区</address> </Head> <Body> <students> <student> <stuclass>高三二班</stuclass> <stuname>李四</stuname> <stuscore>100</stuscore> </student> <student> <stuclass>高三三班</stuclass> <stuname>张三</stuname> <stuscore>95</stuscore> </student> <student> <stuclass>高三四班</stuclass> <stuname>王五</stuname> <stuscore>0</stuscore> </student> </students> </Body> </SCHOOL>
3.工具类(可直接复制粘贴使用)
复制粘贴使用时,需保证和我这里的请求报文模版相同(即使用${元素名}),当然也可手动改造此方法。
@Slf4j public class XmlUtil { //${abc}正则 public static String varRegex = "\$\{\s*(\w+)\s*(([\+\-])\s*(\d+)\s*)?\}"; /** * xml解析成document对象 * * @param xml * @return */ public Document getDocument(String xml) { StringReader stringReader = new StringReader(xml); SAXReader saxReader = new SAXReader(); Document document = null; try { document = saxReader.read(stringReader); } catch (DocumentException e) { } return document; } /** * xml与bean的相互转换 * * @param element * @param direction 1:java2xml,2:xml2java * @param obj */ public void parseXml(Element element, String direction, Object obj) { //获取当前元素的所有子节点(在此我传入根元素) List<Element> elements = element.elements(); //判断是否有子节点 if (elements != null && elements.size() > 0) { //进入if说明有子节点 //遍历 for (Element e : elements) { //判断转换方向(1:java2xml;2:xml2java) if ("2".equals(direction)) //这里是xml转bean { //声明Field Field field = null; try { //反射获取属性 field = obj.getClass().getDeclaredField(e.getName()); } catch (Exception e1) { } //获取当前属性是否为list if (field!=null&&List.class.getName().equals(field.getType().getName())) { //反射获取set方法 Method method = this.getDeclaredMethod(obj, "set".concat(this.toUpperCaseFirstOne(e.getName())), new Class[]{List.class}); //声明临时list List temList = new ArrayList(); if (method!=null) { try { //反射调用obj的当前方法,可变参数为templist method.invoke(obj, temList); } catch (Exception e1) { log.info("【{}】方法执行失败",method,e1); } } //获取List的泛型参数类型 Type gType = field.getGenericType(); //判断当前类型是否为参数化泛型 if (gType instanceof ParameterizedType) { //转换成ParameterizedType对象 ParameterizedType pType = (ParameterizedType) gType; //获得泛型类型的泛型参数(实际类型参数) Type[] tArgs = pType.getActualTypeArguments(); if (tArgs!=null&&tArgs.length>0) { //获取当前元素的所有子元素 List<Element> elementSubList=e.elements(); //遍历 for (Element e1:elementSubList) { try { //反射创建对象 Object tempObj = Class.forName(tArgs[0].getTypeName()).newInstance(); temList.add(tempObj); //递归调用自身 this.parseXml(e1, direction, tempObj); } catch (Exception e2) { log.error("【{}】对象构造失败",tArgs[0].getTypeName(),e2); } } } } } else { //说明不是list标签,继续递归调用自身即可 this.parseXml(e, direction, obj); } } else if("1".equals(direction)) //说明转换方向为:javabean转xml { //递归调用自身 this.parseXml(e, direction, obj); } //此时还在for循环遍历根元素的所有子元素 } } else { //说明无子节点 //获取当前元素的名称 String nodeName = element.getName(); //获取当前元素的对应的值 String nodeValue = element.getStringValue(); //判断转换方向:1:java2xml、2:xml2java if ("1".equals(direction))//java2xml { if (nodeValue != null && nodeValue.matches(varRegex)) { /** * 获取模板中各节点定义的变量名,例如<traceNo>${traceNo}</traceNo> */ nodeValue = nodeValue.substring(nodeValue.indexOf("${") + 2, nodeValue.indexOf("}")); Object value = null; //根据解析出的变量名,调用obj对象的getXXX()方法获取变量值 Method method = this.getDeclaredMethod(obj, "get".concat(this.toUpperCaseFirstOne(nodeValue)), null); if (method != null) { try { value = method.invoke(obj); } catch (Exception e) { log.error("方法【{}】调用异常", "get".concat(this.toUpperCaseFirstOne(nodeValue))); } } //将变量值填充至xml模板变量名位置,例如<traceNo>${traceNo}</traceNo> element.setText(value == null ? "" : value.toString()); } //叶子节点 log.debug("节点名【{}】,节点变量名【{}】",element.getName(),nodeValue); } else if ("2".equals(direction))//xml2java { if (nodeName != null && !"".equals(nodeName)) { //根据xml节点名,调用obj对象的setXXX()方法为obj设置变量值 Method method = this.getDeclaredMethod(obj, "set".concat(this.toUpperCaseFirstOne(nodeName)), new Class[]{String.class}); if(method!=null) { try { method.invoke(obj, nodeValue); } catch (Exception e) { log.error("方法【{}】调用异常","set".concat(this.toUpperCaseFirstOne(nodeName))); } } } } } } private Method getDeclaredMethod(Object object, String methodName, Class<?>[] parameterTypes) { for (Class<?> superClass = object.getClass(); superClass != Object.class; superClass = superClass.getSuperclass()) { try { return superClass.getDeclaredMethod(methodName, parameterTypes); } catch (NoSuchMethodException e) { //Method 不在当前类定义, 继续向上转型 } //.. } return null; } private String toUpperCaseFirstOne(String s) { // 进行字母的ascii编码前移,效率要高于截取字符串进行转换的操作 char[] cs = s.toCharArray(); cs[0] -= 32; return String.valueOf(cs); } }
4.测试
1.准备请求实体bean
private static ReqSchool makeReq() { ReqSchool rspSchool = new ReqSchool(); //学校编号 rspSchool.setNumber("1001"); //学校名称 rspSchool.setName("实验小学"); //学校省份 rspSchool.setProvince("北京市"); //学校地区 rspSchool.setAddress("西城区"); //学生班级 rspSchool.setStuclass("高一(2)班"); //学生姓名 rspSchool.setStuname("张三"); //学生成绩 rspSchool.setStuscore("92"); return rspSchool; }
2.main方法测试(请求)
public static void main(String[] args) { //定义请求模版 String requestXml="<?xml version="1.0" encoding = "GBK"?> " + "<SCHOOL> " + "<Head> " + "<number>${number}</number> " + "<name>${name}</name> " + "<province>${province}</province> " + "<address>${address}</address> " + "</Head> " + "<Body> " + "<stuclass>${stuclass}</stuclass> " + "<stuname>${stuname}</stuname> " + "<stuscore>${stuscore}</stuscore> " + "</Body> " + "</SCHOOL>"; //这里我直接使用构造方法(实际开发应以线程安全的单例模式) XmlUtil xmlUtil = new XmlUtil(); //获取document对象 Document document = xmlUtil.getDocument(requestXml); //获取根元素 Element root = document.getRootElement(); //请求实体bean ReqSchool reqSchool = makeReq(); //解析xml,1:表示java2xml xmlUtil.parseXml(root,"1",reqSchool); //输出请求报文 System.out.println(root.asXML()); }
查看控制台结果:
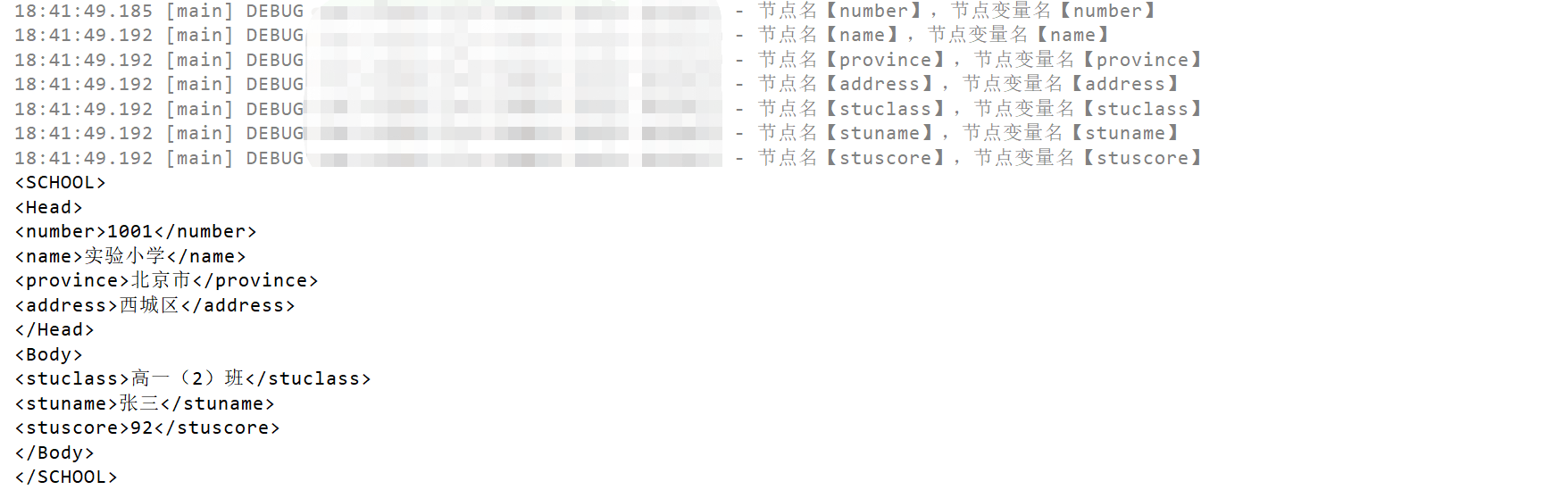
3.main方法测试(响应)
public static void main(String[] args) { //定义响应报文 String responseXML="<?xml version="1.0" encoding = "GBK"?> " + "<SCHOOL> " + "<Head> " + "<number>0001</number> " + "<name>xxx实验小学</name> " + "<province>北京市</province> " + "<address>西城区</address> " + "</Head> " + "<Body> " + " <students> " + " <student> " + " <stuclass>高三二班</stuclass> " + " <stuname>李四</stuname> " + " <stuscore>100</stuscore> " + " </student> " + " <student> " + " <stuclass>高三三班</stuclass> " + " <stuname>张三</stuname> " + " <stuscore>95</stuscore> " + " </student> " + " <student> " + " <stuclass>高三四班</stuclass> " + " <stuname>王五</stuname> " + " <stuscore>0</stuscore> " + " </student> " + " </students> " + "</Body> " + "</SCHOOL>"; //这里我直接使用构造方法(实际开发应以线程安全的单例模式) XmlUtil xmlUtil = new XmlUtil(); Document document = xmlUtil.getDocument(responseXML); Element rootElement = document.getRootElement(); RspSchool rspSchool = new RspSchool(); xmlUtil.parseXml(rootElement,"2",rspSchool); System.out.println(rspSchool); }
控制结果如下:
五、总结
1.dom4j解析xml的步骤
①获取执行xml的输入流
②创建xml读取对象(SaxReader),用于读取输入流
③通过读取对象(SaxReader)读取xml的输入流,获取文档对象(Document)
④通过文档对象,得到整个文档的 根元素对象(Element)
⑤通过根元素,得到其他层次的所有元素对象
2.反射
反射这里是重中之重,感谢大家的阅读,如有问题,欢迎大家指正~