原创作品,转载请注明出处:点我
在前两篇文章中,我们介绍了什么是Generator和coroutine,在这一篇文章中,我们会介绍coroutine在模拟pipeline(管道 )和控制Dataflow(数据流)方面的运用。
coroutine可以用来模拟pipeline行为。通过把多个coroutine串联在一起来实现pipe,在这个管道中,数据是通过send()函数在各个coroutine之间传递的:

但是这些在pipe中传递的数据哪里来的呢?这就需要一个数据源,或者说producer.这个producer驱动整个pipe的运行:

通常情况下,source只是提供数据,驱动整个pipe的运行,其本身并不是一个coroutine,通常行为类似于下面这个模式:

其中,target就是一个coroutine,当调用target.send()函数的时候,数据将会传入整个pipe。
既然pipeline有一个起点,同样的也就必须要有一个sink(end-point,也就是终点)

sink是收集接受coroutine传送过来的数据并对这些数据进行处理。sink通常的模式为:

在前面讲述Generetor的文章中,我们用Generator实现了unix中的tail -f命令和tail -f | grep 命令,在这里,我们也用coroutine来实现这两个命令。
先来看看作为source的代码unix_tail_f_co()函数
1 # A source that mimics Unix "tail -f" 2 def unix_tail_f_co(thefile, target): 3 ''' 4 target是一个coroutine 5 ''' 6 thefile.seek(0, 2) # 跳到文件末尾 7 while True: 8 line = thefile.readline() 9 if not line: 10 time.sleep(0.1) 11 continue 12 # 把数据发送给coroutine进行处理 13 target.send(line)
在上面的代码中,可以看到,target是一个coroutine,函数每次读取一行数据,读取到之后,就调用target.send()函数,把数据发送给了target,由target接收进行下一步的处理。
现在来看看作为sink的printer_co()函数,这个sink很简单,就是简单地打印它收到的数据。
1 # A sink just prints the lines 2 @coroutine 3 def printer_co(): 4 while True: 5 # 在这个地方挂起,等待接收数据 6 line = (yield) 7 print line,
其中coroutine函数装饰器使我们在上一篇介绍coroutine的文章中定义的。从代码中可以看到,作为sink,print_co()函数有一个死循环,从第6行可以看到,在这个死循环中,
函数会一直挂起,等到数据的到来,然后每次接收到数据后,打印输出,然后再次挂起等待数据的到来。
现在可以把上面两个函数结合起来实现tail -f命令:
1 f = open("access-log") 2 unix_tail_f_co(f,printer_co())
代码首先打开一个文件f,f作为数据源,把f和printer_co()传递给unix_tail_f_co(),这就实现了一个pipeline,只不过在这个pipeline中,数据是直接发送给作为sink的printer_co()函数的,中间没有经过其他的coroutine。

在sink和source之间,可以根据需要,添加任何的coroutine,比如数据变换(transformation)、过滤(filter)和路由(routing)等

现在,我们添加一个coroutine,grep_filter_co(pattern,target),其中,target是一个coroutine
1 @coroutine 2 def grep_filter_co(pattern,target): 3 while True: 4 # 挂起,等待接收数据 5 line = (yield) 6 if pattern in line: 7 # 接收到的数据如果符合要求, 8 # 则发送给下一个coroutine进行处理 9 target.send(line)
从代码中可以看到,grep_filter_co()有一个死循环,在循环中挂起等待接收数据,一旦接收到了数据,如果数据中存在pattern,则把接收到的数据发送给target,让target对数据进行下一步处理,然后再次等待接收数据并挂起。
同样的,现在把这三个函数组合起来,实现tail -f | grep命令,组成一个新的pipeline:
f = open("access-log") unix_tail_f_co(f,grep_filter_co("python",printer_co()))
unix_tail_f_co()作为source,从f文件处每次读取一行数据,发送给grep_filter_co()这个coroutine,grep_filer_co()对接收到的数据进行过滤(filter):如果接收到的数据包含了"python"这个单词,就把数据发送给printer_co()进行处理,然后source再把下一行数据发送到pipeline中进行处理。

在前面也用Generator实现了tail -f | grep 命令,现在可以把两者做一个比较:
Generator实现的流程为:

而coroutine实现的流程为:

可以看出,Generator 在最后的的迭代过程中从pipe中获取数据,而coroutine通过send()函数把数据发送到pipeline中去。
通过coroutine,可以把数据发送到不同的目的地,如下图:
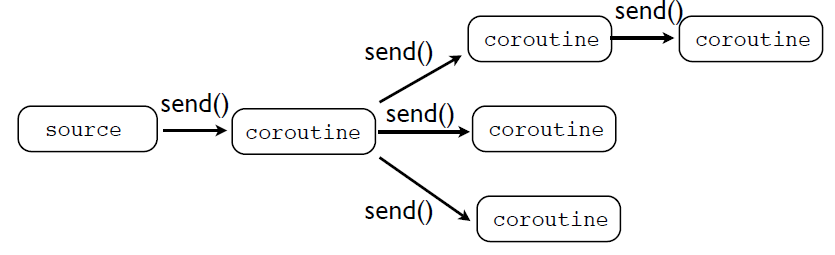
下面我们来实现消息广播(Broadcasting)机制,首先要先定义一个函数broadcast_co(targets)
1 # 把数据发送给多个不同的coroutine 2 @coroutine 3 def broadcast_co(targets): 4 while True: 5 # 挂起,等待接收数据 6 item = (yield) 7 for target in targets: 8 # 接收到了数据,然后分别发送给不同的coroutine 9 target.send(item)
broadcats_co()函数接受一个参数targets,这个参数是一个列表(list),其中的每一个成员都是coroutine,在一个死循环中,函数接收到数据之后,把数据依次发送给不同的coroutine进行处理,然后会挂起等待接收数据。
f = open("access-log") unix_tail_f_co(f, broadcast_co([grep_filter_co('python',printer_co()), grep_filter_c0('ply',printer_co()), grep_filter_co('swig',printer_co())]) )
unix_tail_f_co每次从f读取一行数据,发送给broadcast_co(),broadcast_co()会把接收到的数据依次发送给gerp_filter_co(),每个grep_filter_co()再会把数据发送给相应的printer_co()进行处理。
|---------------> grep_filter_co("python") ------> printer_co() unix_tail_f_co()--->broadcast_co() ----> grep_filter_co("ply") ---------> printer_co() |---------------> grep_filter_co("swig")---------> printer_co()
需要注意的是:broadcast_co()会先把数据发送给grep_filter_co("python"),grep_filter_co("python")会把数据发送给printer_co(),当printer_co()执行后挂起再次等待接受数据时,执行权返回到grep_filter_co("python")函数,此时grep_filter_co("python")也会挂起等待接收数据,执行权回到broadcast_co()函数,此时broadcast_co()才会把消息发送给grep_filter_co("ply"),也只有当grep_filter_co("ply")执行完毕挂起之后,broadcast_co()才会接着把数据发送给下一个coroutine。
如果把上面的代码改成这样,就会有另外一种broadcast的模式:
f = open("access-log") p = printer_co() unix_tail_f_co(f, broadcast_co([grep_filter_co('python',p)), grep_filter_co('ply',p), grep_filter_co('swig',p)]) )
此时,broadcast的模式为
|---------------> grep_filter_co("python") ---------->| unix_tail_f_co()--->broadcast_co() ----> grep_filter_co("ply") ---------> printer_co() |---------------> grep_filter_co("swig")------------->|
最后数据都会传送到同一个print_co()函数,也就是说最后数据的目的地为同一个。
好了,这篇讲解coroutine在模拟pipeline和控制dataflow上的应用已经完毕了,可以看出coroutine在数据路由方面有很强大的控制能力,可以把多个不同的处理方式组合在一起使用。
下一篇文章会讲解如何用coroutine是下班一个简单的多任务(Multitask)的操作系统,尽请期待O(∩_∩)O。