参考:https://zhuanlan.zhihu.com/p/35709485
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
交叉熵损失函数优点
在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:一、学习率;二、偏导值。其中,学习率是我们需要设置的超参数,所以我们重点关注偏导值。一共有两项需要关注,我们重点关注后者,后者的大小值反映了我们模型的错误程度,该值越大,说明模型效果越差,但是该值越大同时也会使得偏导值越大,从而模型学习速度更快。所以,使用逻辑函数得到概率,并结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
交叉熵损失函数 缺点
sigmoid(softmax)+cross-entropy loss 擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。基于这个问题的优化有很多,比如对softmax进行改进,如L-Softmax、SM-Softmax、AM-Softmax等。
参考:https://www.cnblogs.com/aijianiula/p/9651879.html
收敛速度:
1.对于square mean在更新w,b时候,w,b的梯度跟激活函数的梯度成正比,激活函数梯度越大,w,b调整就越快,训练收敛就越快,但是Simoid函数在值非常高时候,梯度是很小的,比较平缓。2.对于cross entropy在更新w,b时候,w,b的梯度跟激活函数的梯度没有关系了,bz已经表抵消掉了,其中bz-y表示的是预测值跟实际值差距,如果差距越大,那么w,b调整就越快,收敛就越快。函数图像:二次代价函数存在很多局部最小点,而交叉熵就不会。
分类问题,都用 onehot + cross entropytraining 过程中,分类问题用 cross entropy,回归问题用 mean squared error。
training 之后,validation / testing 时,使用 classification error,更直观,而且是我们最关注的指标。
分类问题,最后必须是 one hot 形式算出各 label 的概率, 然后通过 argmax 选出最终的分类。
在计算各个 label 概率的时候,用的是 softmax 函数。
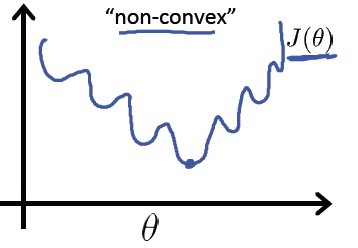
如果用 MSE 计算 loss, 输出的曲线是波动的,有很多局部的极值点。 即,非凸优化问题 (non-convex)
cross entropy 计算 loss,则依旧是一个凸优化问题,
用梯度下降求解时,凸优化问题有很好的收敛特性。