EasyTransfer
简介:近日,阿里云正式开源了深度迁移学习框架EasyTransfer,这是业界首个面向NLP场景的深度迁移学习框架。该框架由阿里云机器学习PAI团队研发,让自然语言处理场景的模型预训练和迁移学习开发与部署更加简单和高效。
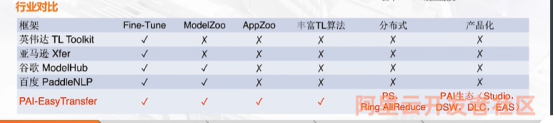
我们从以下4个部分来介绍EasyTransfer:1 挑战和亮点,架构总览。核心功能和实践使用。
面向自然语言处理场景的深度迁移学习在现实场景里有巨大的需求,因为大量新的领域不断涌现,传统的机器学习需要对每个领域都积累大量训练数据,这将会耗费大量标注的人力与物力。深度迁移学习技术可以将源领域学到的知识迁移到新的领域的任务,进而大大减少标注的资源。
尽管面向自然语言场景的深度迁移学习有很多的需求,目前开源社区还没有一个完善的框架,而且构建一个简单易用且高性能的框架有巨大挑战。
- 首先,预训练模型加知识迁移现在是主流的NLP应用模式,通常预训练模型尺寸越大学习到的知识表征越有效,然而超大的模型给框架的分布式架构带来了巨大挑战。如何提供一个高性能的分布式架构,从而有效支持超大规模的模型训练。
- 其次,用户应用场景的多样性很高,单一的迁移学习算法无法适用,如何提供一个完备的迁移学习工具来提升下游场景的效果。
- 第三,从算法开发到业务落地通常需要很长的链路,如何提供一个简单易用的从模型训练到部署的一站式服务。
面对这三大挑战,PAI团队推出了EasyTransfer,一个简单易用且高性能的迁移学习框架。框架支持主流的迁移学习算法,支持自动混合精度、编译优化和高效的分布式数据/模型并行策略,适用于工业级的分布式应用场景。
值得一提的是,配合混合精度、编译优化和分布式策略,EasyTransfer支持的ALBERT模型比社区版的ALBERT在分布式训练的运算速度上快4倍多。
同时,经过了阿里内部10多个BU,20多个业务场景打磨,给NLP和迁移学习用户提供了多种便利,包括业界领先的高性能预训练工具链和预训练ModelZoo,丰富易用的AppZoo,高效的迁移学习算法,以及全面兼容阿里巴巴PAI生态产品,给用户提供一个从模型训练到部署的一站式服务。
阿里云机器学习PAI团队负责人林伟表示:本次开源EasyTransfer代码,希望把阿里能力赋能给更多的用户,降低NLP的预训练和知识迁移的门槛,同时也和更多伙伴一起深入合作打造一个简单,易用,高性能的NLP和迁移学习工具。
一 EasyTransfer六大亮点
简单高性能的框架
屏蔽复杂的底层实现,用户只需关注模型的逻辑结构,降低了NLP和迁移学习的入门门槛;同时,框架支持工业级的分布式应用场景,改善了分布式优化器,配合自动混合精度,编译优化,和高效的分布式数据/模型并行策略,做到比社区版的多机多卡分布式训练在运算速度上快4倍多。
语言模型预训练工具链
支持完整的预训练工具链,方便用户预训练语言模型如T5和BERT,基于该工具链产出的预训练模型在中文CLUE 榜单和英文SuperGLUE 榜单取得很好的成绩。
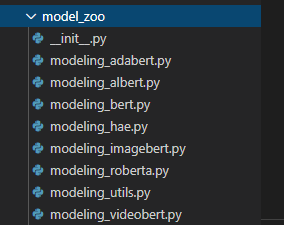
丰富且高质量的预训练模型ModelZoo
支持PAI-ModelZoo,支持Bert,Albert,Roberta,XLNet,T5等主流模型的Continue Pretrain和Finetune。同时支持自研的多模态模型服装行业的Fashionbert等。
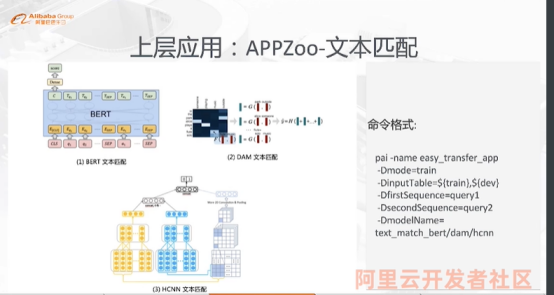
丰富且易用的应用AppZoo
支持主流的NLP应用和自研的模型应用,比方说文本匹配下支持DAM++(DAM用于处理一个连续型的问答问题,问题的答案存在于一个序列中,模型的目标是从待选择的答案中选出最合适的答案并给予评分。)、HCNN等单塔模型,以及BERT双塔+向量召回模型;阅读理解下支持BERT-HAE(history-answer-embedding)等模型。
自动知识蒸馏工具
支持知识蒸馏,可以从大的teacher模型蒸馏到小的student模型。集成了任务有感知的BERT模型压缩AdaBERT,采用了神经网路架构搜索去搜索出任务相关的架构去压缩原始的BERT模型,可以压缩最多到原来的1/17,inference最多提升29倍,且模型效果损失在3%以内。
兼容PAI生态产品
框架基于PAI-TF开发,用户通过简单的代码或配置文件修改,就可以使用PAI自研高效的分布式训练,编译优化等特性;同时框架完美兼容PAI生态的产品,包括 PAI Web组件(PAI Studio),开发平台(PAI DSW),和PAI Serving平台(PAI EAS)。
拖拽式建模(PAI Studio)
PAI命令
二 平台架构总览
EasyTransfer的整体框架如下图所示,在设计上尽可能的简化了深度迁移学习的算法开发难度。框架抽象了常用的IO,layers,losses,optimizers, models,用户可以基于这些接口开发模型,也可以直接接入预训练模型库ModelZoo快速建模。框架支持五种迁移学习(TL)范式,model finetuning,feature-based TL, instance-based TL, model-based TL和meta learning。同时,框架集成了AppZoo,支持主流的NLP应用,方便用户搭建常用的NLP算法应用。最后,框架无缝兼容PAI生态的产品,给用户从训练到部署带来一站式的体验。
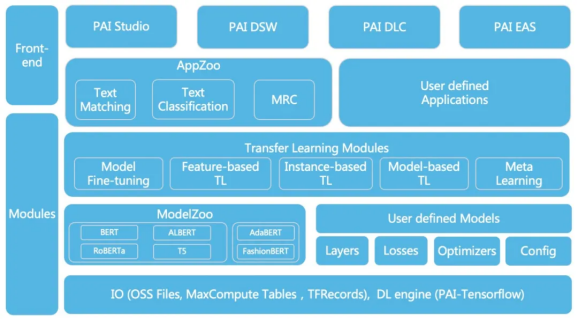
最底层 常见的IO PAI优化过的TF
预训练好的模型
5种迁移学习范式
主流NLP应用
无缝对接PAI的组件 一站式服务
三 平台功能详解
下面详细介绍下EasyTransfer框架的核心功能。
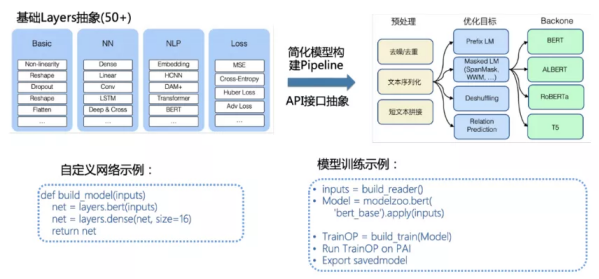
简单易用的API接口设计
预训练pipeline
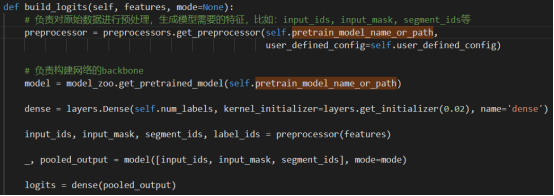
高性能分布式框架
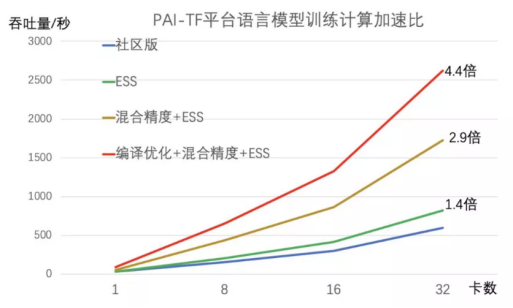
EasyTransfer框架支持工业级的分布式应用场景,改善了分布式优化器,配合自动混合精度,编译优化,和高效的分布式数据/模型并行策略,PAI-ALBERT做到比社区版的ALBERT在多机多卡分布式训练的运算速度上快4倍多。
优化参数配置。只需要简单的参数就能给出合理的配置。达到线性加速比。(快速收敛)
丰富的ModelZoo
框架提供了一套预训练语言模型的工具供用户自定义自己的预训练模型,同时提供了预训练语言模型库ModelZoo供用户直接调用。目前支持了20+预训练模型,其中在PAI平台上预训练的PAI-ALBERT-zh取得中文CLUE榜单第一名,PAI-ALBERT-en-large取得英文SuperGLUE第二名的好成绩。下面是详细的预训练模型列表:

丰富的AppZoo
EasyTransfer封装了高度易用、灵活且学习成本低的AppZoo,支持用户在仅用几行命令的条件下“大规模”运行“前沿”的开源与自研算法,即可迅速接入不同场景和业务数据下的NLP应用,包括文本向量化、匹配、分类、阅读理解和序列标注等。
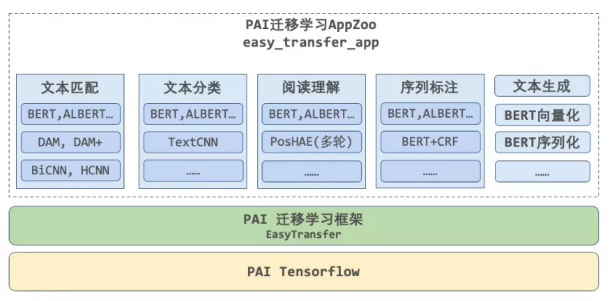
Scripts 里包含了很多NLP应用的脚本,比如文本分类、匹配、fashion bert等。直接改一下参数和数据格式就可以直接使用。
高效的迁移学习算法
EasyTransfer框架支持所有主流的迁移学习范式,包括Model Fine-tuning, Feature-based TL, Instance-based TL, Model-based TL和Meta Learning。基于这些迁移学习范式开发了10多种算法,在阿里的业务实践中取得了良好效果的效果。后续所有的算法都会开源到EasyTransfer代码库里。在具体应用的时候,用户可以根据下图来选择一种迁移学习范式来测试效果。

迁移学习范式
model fine-tuning 模型fine-tuning (数据较多丰富) 难点:超大规模的预训练模型支持 (使用的最多的) 高质量的预训练模型
数据差异和任务差异
Feature-based TL特征迁移 (标注数据比较少) 难点:领域差异 (多轮阅读理解数据不足可以从单轮数据里迁移) 学习相似领域 样本迁移的方法 对抗学校学到更好的shared和specific特征 自研 HCNN(文本匹配的方案)
Instance-based TL样本迁移 难点 :选择合适的样本 提出强化迁移学习算法 反馈(直接和间接)
Meta-Learing 元学习 高效学习元知识 不同领域不同任务 对每个领域的样本计算权重,在选了元学习是重点学习典型样本 (多领域的知识fine-tuning)
Model-based TL 模型迁移 难点:手动设计网络,任务无关的蒸馏 自适应知识蒸馏(自动搜索合适的网络架构)
预训练语言模型
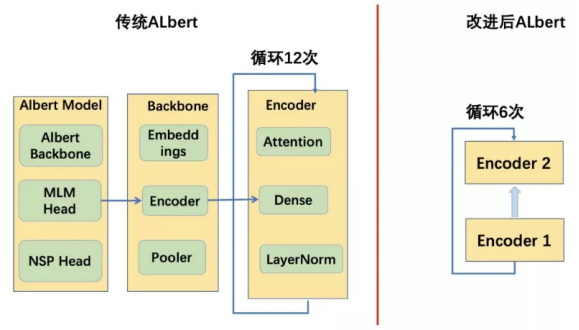
自然语言处理的一大热点工作就是预训练语言模型比方说BERT,ALBERT等,这类模型在各大自然语言处理场景都取得了非常不错的效果。为了更好的支持用户使用预训练语言模型,我们在新版的迁移学习框架EasyTransfer里植入了一套预训练语言模型的标准范式和预训练语言模型库ModelZoo。传统Albert为了减少参数总量,取消了bert的encoder堆叠的方式,转而采用encoder循环的方式,如下图所示。全循环方式在下游任务上表现并不十分理想,于是我们将全循环改为了在2层堆叠的encoder上全循环。然后我们基于英文C4数据,重新对Albert xxlarge进行预训练。在预训练的过程中,我们仅仅使用MLM loss,配合Whole Word Masking,基于EasyTransfer的Train on the fly功能,我们实现了dynamic online masking,即可以在每次读入原始句子的同时动态生成需要masking的tokens。我们最终的预训练模型PAI-ALBERT-en-large在SuperGLUE榜单上取得国际第二,国内第一的成绩,模型参数仅仅为第一名Google T5的1/10,效果差距在3.5%以内。后续我们会继续优化模型框架,争取以1/5的模型参数达到比T5更好的效果。
多模态模型FashionBERT
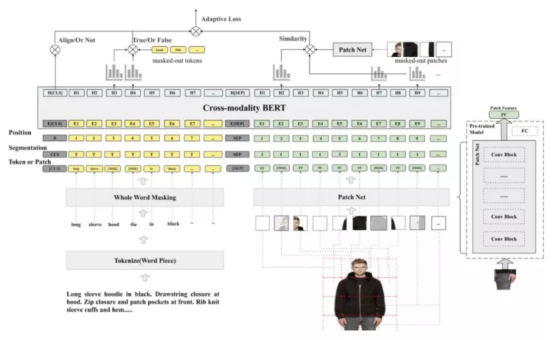
随着Web技术发展,互联网上包含大量的多模态信息,包括文本,图像,语音,视频等。从海量多模态信息搜索出重要信息一直是学术界研究重点。多模态匹配核心就是图文匹配技术(Text and Image Matching),这也是一项基础研究,在非常多的领域有很多应用,例如 图文检索(Cross-modality IR),图像标题生成(Image Caption),图像问答系统(Vision Question Answering), 图像知识推理(Visual Commonsense Reasoning)。但是目前学术界研究重点放在通用领域的多模态研究,针对电商领域的多模态研究相对较少。基于此,我们和阿里ICBU团队合作提出了FashionBERT多模态预训练模型,针对电商领域的图文信息进行预训练的研究,在多个跨模态检索和图文匹配等业务场景都有成功的应用。模型架构图如下所示。该工作提出了Adaptive Loss,用于平衡图文匹配,纯图片,和纯文本三部分loss。
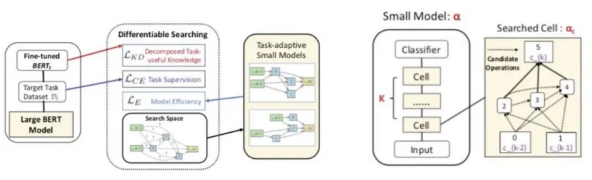
任务自适应的知识蒸馏
预训练模型从海量无监督数据中提取通用知识,并通过知识迁移的方法提升下游任务的效果,在场景里取得了优异的效果。通常预训练模型尺寸越大,学习到的知识表征对下游任务越有效,带来的指标提升也越明显。然而大模型显然无法满足工业界应用的时效性需求,因此需要考虑模型压缩。我们和阿里智能计算团队合作提出了一种全新的压缩方法 AdaBERT,利用可微神经架构搜索(Differentiable Neural Architecture Search)自动地将 BERT 压缩成任务自适应的小型模型。
在这个过程中,我们将BERT作为老师模型,提炼它在目标任务上有用的知识;在这些知识的指导下,我们自适应地搜索一个适合目标任务的网络结构,压缩得到小规模的学生模型。我们在多个NLP公开任务上进行了实验评估,结果显示经由AdaBERT压缩后的小模型在保证精读相当的同时,推理速度比原始BERT快 12.7 到 29.3 倍,参数规模比原始BERT小 11.5 到 17.0倍 。
QA场景领域关系学习
早在2017年,我们就在阿里小蜜问答场景里面尝试了迁移学习,我们主要侧重于DNN based Supervised TL。这类算法主要有两种框架,一个是Fully-shared(FS),另外一个是Specific-shared(SS)。两者最大的差别是前者只考虑了shared representation,而后者考虑了specific representation。通常来说SS的模型效果比FS效果好,因为FS可以看作是SS的一个特例。对于SS来说,最理想的情况下是shared的部分表示的是两个领域的共性,specific的部分表示的是特性。然而往往我们发现要达到这样的效果很难,于是我们考虑用一个adversarial loss和domain correlation来协助模型学好这两部分特征。基于此,我们提出了一个新的算法,hCNN-DRSS,架构如下所示:
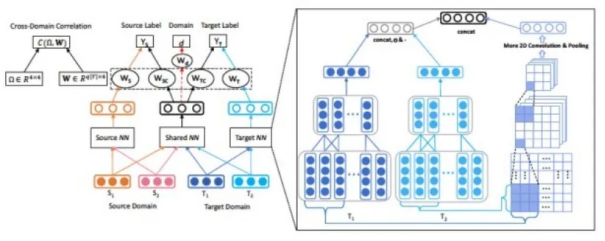
我们将这个算法应用在了小蜜的实际业务场景中,在多个业务场景里(AliExpress, 万象,Lazada)取得了不错的效果。
强化迁移学习Reinforced Transfer Learning
迁移学习的有效性,很大程度上取决于source domain和target domain之间的gap,如果gap比较大,那么迁移很可能是无效的。在小蜜QA场景,如果直接把Quora的text matching数据迁移过来,有很多是不太合适的。我们在小蜜的QA场景,基于Actor-Critic算法,搭建了一个通用的强化迁移学习框架,用RL来做样本选择,帮助TL模型取得更好的效果。整个模型分三部分,基础QA模型,迁移学习模型(TL)和强化学习模型(RL)。其中RL的policy function负责选出高质量的样本(actions),TL模型在选出来的样本上训练QA模型并提供反馈给RL,RL根据反馈(reward)来更新actions。该框架训练的模型在双11AliExpress的俄语和西语匹配模型,在西语和俄语的匹配准确率都取得了非常不错的提升。

元调优Meta Fine-tuning
预训练语言模型的广泛应用,使得Pre-training+Fine-tuning的两阶段训练模型成为主流。我们注意到,在fine-tuning阶段,模型参数仅在特定领域、特定数据集上fine-tune,没有考虑到跨领域数据的迁移调优效果。元调优(Meta Fine-tuning)算法借鉴Meta-learning的思想,旨在学习预训练语言模型跨领域的meta-learner,从而使得学习的meta-learner可以快速迁移到特定领域的任务上。这一算法学习训练数据样本的跨领域typicality(即可迁移性),同时在预训练语言模型中增加domain corruption classifier,使得模型更多地学习到领域无关的特征(domain-invariant representations)。
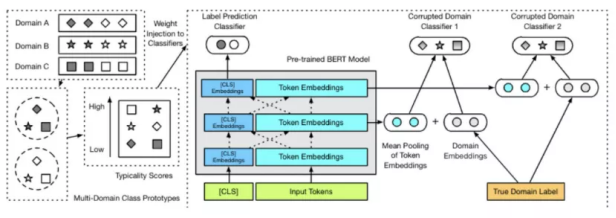
我们将该fine-tuning算法应用于BERT,在自然语言推理和情感分析等多个任务上进行了实验。实验结果表明,元调优算法在这些任务上都优于BERT的原始fine-tuning算法和基于transfer learning的fine-tuning算法。
元知识蒸馏Meta-Knowledge Distillation
随着BERT等预训练语言模型在各项任务上都取得了SOTA效果,BERT这类模型已经成为 NLP 深度迁移学习管道中的重要组成部分。但 BERT 并不是完美无瑕的,这类模型仍然存在以下两个问题:模型参数量太大和训练/推理速度慢的问题,因此一个方向是将BERT知识蒸馏到一个小模型。但是大部分的知识蒸馏工作都聚焦在同一个领域,而忽略了跨领域对蒸馏任务提升的问题。我们提出了用Meta Learning的方式将跨领域的可迁移知识学出,在蒸馏阶段额外对可迁移的知识进行蒸馏。这样的做法使得学习到的Student模型在相应的领域的效果显著提升,我们在多个跨领域的任务上都蒸馏出了较好的学生模型,逼近教师模型的效果。我们近期会梳理这个工作,发布代码和文章。
四 创新文章
EasyTransfer框架已在阿里集团内数十个NLP场景落地,包括智能客服、搜索推荐、安全风控、大文娱等,带来了显著业务效果的提升。目前EasyTransfer日常服务有上亿次调用,月均训练调用量超过5万次。EasyTransfer团队在落地业务的同时也沉淀了很多的创新的算法解决方案,包括元学习,多模态预训练,强化迁移学习,特征迁移学习等方向的工作,共合作发表了几十篇顶级会议文章,下面列举一些代表性工作。后续这些算法都会在EasyTransfer框架里开源供广大用户使用。
视频内容
迁移学习解决的内容:
大数据vs 少标注
大数据vs 计算资源不足
通用模型vs 个性化应用场景
提升超大规模预训练模型能效
业务场景多样化
训练-部署 一体化解决方案
上层应用APPZoo
Pai命令
实践 : 1 AppZoo实践
2 ModelZoo实践
3 分布式训练
4 多模态
一 App Zoo实践
以文本分类为例

1 做好数据
2 设定参数和模式
运行 .sh脚本

PS.同自己找个文本分类的代码 统一格式,设定一些参数(lr , batch_size, epoch 等)
优点:集成了很多文本的处理,分类,相似,匹配,阅读理解,序列化标注等。
二 ModelZoo实践

DSW-自定义文本分类
集成了很多层 layer,集成了很多预训练模型

三 分布式训练实践 DSW
RDMA remote direct memory access (可以跨机高速通信,通信梯度,累积求和 得到全局梯度)
数据并行 增加机器 数据放在不同的GPU上计算
用阿里的资源(云资源,收费)
四 多模态fashionbert