etcd中的Lease
前言
之前我们了解过grpc使用etcd做服务发现
之前的服务发现我们使用了 Lease,每次注册一个服务分配一个租约,通过 Lease 自动上报机模式,实现了一种活性检测机制,保证了故障机器的及时剔除。这次我们来想写的学习 Lease 租约的实现。
Lease
Lease 整体架构
这里放一个来自【etcd实战课程】的一张图片
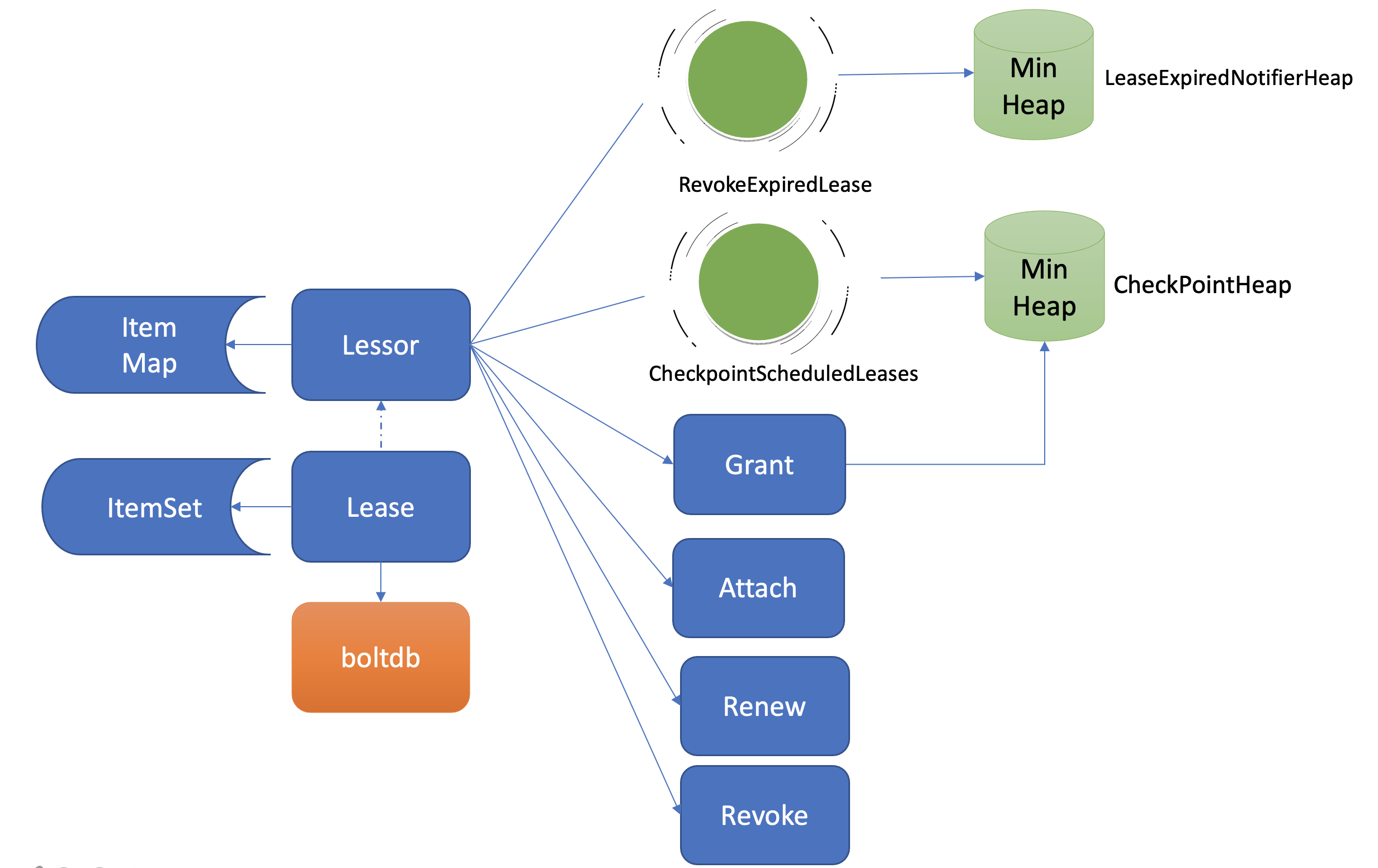
来看下服务端中Lease中的几个主要函数
// etcd/server/lease/lessor.go
// Lessor owns leases. It can grant, revoke, renew and modify leases for lessee.
type Lessor interface {
...
// Grant 表示创建一个 TTL 为你指定秒数的 Lease
Grant(id LeaseID, ttl int64) (*Lease, error)
// Revoke 撤销具有给定 ID 的租约
Revoke(id LeaseID) error
// 将给定的租约附加到具有给定 LeaseID 的租约。
Attach(id LeaseID, items []LeaseItem) error
// Renew 使用给定的 ID 续订租约。它返回更新后的 TTL
Renew(id LeaseID) (int64, error)
...
}
同时对于客户端 Lease 也提供了下面几个API
// etcd/client/v3/lease.go
type Lease interface {
// Grant 表示创建一个 TTL 为你指定秒数的 Lease,Lessor 会将 Lease 信息持久化存储在 boltdb 中;
Grant(ctx context.Context, ttl int64) (*LeaseGrantResponse, error)
// 表示撤销 Lease 并删除其关联的数据;
Revoke(ctx context.Context, id LeaseID) (*LeaseRevokeResponse, error)
// 表示获取一个 Lease 的有效期、剩余时间;
TimeToLive(ctx context.Context, id LeaseID, opts ...LeaseOption) (*LeaseTimeToLiveResponse, error)
// Leases retrieves all leases.
Leases(ctx context.Context) (*LeaseLeasesResponse, error)
// 表示为 Lease 续期
KeepAlive(ctx context.Context, id LeaseID) (<-chan *LeaseKeepAliveResponse, error)
// 使用once只在第一次调用
KeepAliveOnce(ctx context.Context, id LeaseID) (*LeaseKeepAliveResponse, error)
// Close releases all resources Lease keeps for efficient communication
// with the etcd server.
Close() error
}
服务端在启动 Lessor 模块的时候,会启动两个 goroutine ,revokeExpiredLeases() 和 checkpointScheduledLeases() 。
-
revokeExpiredLeases: 定时检查是否有过期 Lease,发起撤销过期的 Lease 操作;
-
checkpointScheduledLeases: 定时触发更新 Lease 的剩余到期时间的操作;
func newLessor(lg *zap.Logger, b backend.Backend, cfg LessorConfig) *lessor {
...
l := &lessor{
...
}
l.initAndRecover()
go l.runLoop()
return l
}
func (le *lessor) runLoop() {
defer close(le.doneC)
for {
le.revokeExpiredLeases()
le.checkpointScheduledLeases()
select {
case <-time.After(500 * time.Millisecond):
case <-le.stopC:
return
}
}
}
// revokeExpiredLeases 找到所有过期的租约,并将它们发送到过期通道被撤销
func (le *lessor) revokeExpiredLeases() {
var ls []*Lease
// rate limit
revokeLimit := leaseRevokeRate / 2
le.mu.RLock()
if le.isPrimary() {
// 在leaseExpiredNotifier中的小顶堆中删除过期的lease
ls = le.findExpiredLeases(revokeLimit)
}
le.mu.RUnlock()
if len(ls) != 0 {
select {
case <-le.stopC:
return
case le.expiredC <- ls:
default:
// the receiver of expiredC is probably busy handling
// other stuff
// let's try this next time after 500ms
}
}
}
// checkpointScheduledLeases 查找所有到期的预定租约检查点将它们提交给检查点以将它们持久化到共识日志中。
func (le *lessor) checkpointScheduledLeases() {
var cps []*pb.LeaseCheckpoint
// rate limit
for i := 0; i < leaseCheckpointRate/2; i++ {
le.mu.Lock()
if le.isPrimary() {
cps = le.findDueScheduledCheckpoints(maxLeaseCheckpointBatchSize)
}
le.mu.Unlock()
if len(cps) != 0 {
le.cp(context.Background(), &pb.LeaseCheckpointRequest{Checkpoints: cps})
}
if len(cps) < maxLeaseCheckpointBatchSize {
return
}
}
}
我们可以看到对于revokeExpiredLeases() 和 checkpointScheduledLeases() 的操作,定时是500毫秒处理一次,直到收到退出的信息。
key 如何关联 Lease
然后我们来分析下一个基于 Lease 特性实现检测一个节点存活的过程
客户端通过 Grant 创建一个 TTL 时间的 Lease
// etcd/client/v3/lease.go
func (l *lessor) Grant(ctx context.Context, ttl int64) (*LeaseGrantResponse, error) {
r := &pb.LeaseGrantRequest{TTL: ttl}
// 通过grpc低啊用服务端的创建函数
resp, err := l.remote.LeaseGrant(ctx, r, l.callOpts...)
if err == nil {
gresp := &LeaseGrantResponse{
ResponseHeader: resp.GetHeader(),
ID: LeaseID(resp.ID),
TTL: resp.TTL,
Error: resp.Error,
}
return gresp, nil
}
return nil, toErr(ctx, err)
}
客户端创建的时候会通过 LeaseGrant 也就是grpc调用服务端的 Grant 的创建函数
来看下服务端的 Grant
// etcd/server/lease/lessor.go
func (le *lessor) Grant(id LeaseID, ttl int64) (*Lease, error) {
...
// TODO: when lessor is under high load, it should give out lease
// with longer TTL to reduce renew load.
l := &Lease{
ID: id,
ttl: ttl,
itemSet: make(map[LeaseItem]struct{}),
revokec: make(chan struct{}),
}
le.mu.Lock()
defer le.mu.Unlock()
// 检查内存leaseMap是否存在这个lease
if _, ok := le.leaseMap[id]; ok {
return nil, ErrLeaseExists
}
// 这里有个ttl的最小值
if l.ttl < le.minLeaseTTL {
l.ttl = le.minLeaseTTL
}
if le.isPrimary() {
l.refresh(0)
} else {
l.forever()
}
le.leaseMap[id] = l
// 将 Lease 数据保存到 boltdb 的 Lease bucket 中
l.persistTo(le.b)
...
return l, nil
}
首先 Lessor 的 Grant 接口会把 Lease 保存到内存的 ItemMap 数据结构中,将数据数据保存到 boltdb 的 Lease bucket 中,返回给客户端 leaseId
当然 Grant 只是申请了一个 Lease,将 key 和 Lease 进行关联的操作是在 Attach 中完成的
// 将给定的租约附加到具有给定 LeaseID 的租约。
func (le *lessor) Attach(id LeaseID, items []LeaseItem) error {
le.mu.Lock()
defer le.mu.Unlock()
l := le.leaseMap[id]
if l == nil {
return ErrLeaseNotFound
}
l.mu.Lock()
// 将租约放到itemMap
// 一个租约是可以关联多个key的
for _, it := range items {
l.itemSet[it] = struct{}{}
le.itemMap[it] = id
}
l.mu.Unlock()
return nil
}
一个 Lease 关联的 key 集合是保存在内存中的,那么 etcd 重启时,是如何知道每个 Lease 上关联了哪些 key 呢?
答案是 etcd 的 MVCC 模块在持久化存储 key-value 的时候,保存到 boltdb 的 value 是个结构体(mvccpb.KeyValue), 它不仅包含你的 key-value 数据,还包含了关联的 LeaseID 等信息。因此当 etcd 重启时,可根据此信息,重建关联各个 Lease 的 key 集合列表。
func (le *lessor) initAndRecover() {
tx := le.b.BatchTx()
tx.Lock()
tx.UnsafeCreateBucket(buckets.Lease)
_, vs := tx.UnsafeRange(buckets.Lease, int64ToBytes(0), int64ToBytes(math.MaxInt64), 0)
// TODO: copy vs and do decoding outside tx lock if lock contention becomes an issue.
for i := range vs {
var lpb leasepb.Lease
err := lpb.Unmarshal(vs[i])
if err != nil {
tx.Unlock()
panic("failed to unmarshal lease proto item")
}
ID := LeaseID(lpb.ID)
if lpb.TTL < le.minLeaseTTL {
lpb.TTL = le.minLeaseTTL
}
le.leaseMap[ID] = &Lease{
ID: ID,
ttl: lpb.TTL,
// itemSet will be filled in when recover key-value pairs
// set expiry to forever, refresh when promoted
itemSet: make(map[LeaseItem]struct{}),
expiry: forever,
revokec: make(chan struct{}),
}
}
le.leaseExpiredNotifier.Init()
heap.Init(&le.leaseCheckpointHeap)
tx.Unlock()
le.b.ForceCommit()
}
Lease的续期
续期我们通过定期发送 KeepAlive 请求给 etcd 续期健康状态的 Lease
// etcd/client/v3/lease.go
// KeepAlive尝试保持给定的租约永久alive
func (l *lessor) KeepAlive(ctx context.Context, id LeaseID) (<-chan *LeaseKeepAliveResponse, error) {
ch := make(chan *LeaseKeepAliveResponse, LeaseResponseChSize)
l.mu.Lock()
// ensure that recvKeepAliveLoop is still running
select {
case <-l.donec:
err := l.loopErr
l.mu.Unlock()
close(ch)
return ch, ErrKeepAliveHalted{Reason: err}
default:
}
ka, ok := l.keepAlives[id]
if !ok {
// create fresh keep alive
ka = &keepAlive{
chs: []chan<- *LeaseKeepAliveResponse{ch},
ctxs: []context.Context{ctx},
deadline: time.Now().Add(l.firstKeepAliveTimeout),
nextKeepAlive: time.Now(),
donec: make(chan struct{}),
}
l.keepAlives[id] = ka
} else {
// add channel and context to existing keep alive
ka.ctxs = append(ka.ctxs, ctx)
ka.chs = append(ka.chs, ch)
}
l.mu.Unlock()
go l.keepAliveCtxCloser(ctx, id, ka.donec)
// 使用once只在第一次调用
l.firstKeepAliveOnce.Do(func() {
// 500毫秒一次,不断的发送保持活动请求
go l.recvKeepAliveLoop()
// 删除等待太久没反馈的租约
go l.deadlineLoop()
})
return ch, nil
}
// deadlineLoop获取在租约TTL中没有收到响应的任何保持活动的通道
func (l *lessor) deadlineLoop() {
for {
select {
case <-time.After(time.Second):
// donec 关闭,当 recvKeepAliveLoop 停止时设置 loopErr
case <-l.donec:
return
}
now := time.Now()
l.mu.Lock()
for id, ka := range l.keepAlives {
if ka.deadline.Before(now) {
// 等待响应太久;租约可能已过期
ka.close()
delete(l.keepAlives, id)
}
}
l.mu.Unlock()
}
}
func (l *lessor) recvKeepAliveLoop() (gerr error) {
defer func() {
l.mu.Lock()
close(l.donec)
l.loopErr = gerr
for _, ka := range l.keepAlives {
ka.close()
}
l.keepAlives = make(map[LeaseID]*keepAlive)
l.mu.Unlock()
}()
for {
// resetRecv 打开一个新的lease stream并开始发送保持活动请求。
stream, err := l.resetRecv()
if err != nil {
if canceledByCaller(l.stopCtx, err) {
return err
}
} else {
for {
// 接收lease stream的返回返回
resp, err := stream.Recv()
if err != nil {
if canceledByCaller(l.stopCtx, err) {
return err
}
if toErr(l.stopCtx, err) == rpctypes.ErrNoLeader {
l.closeRequireLeader()
}
break
}
// 根据LeaseKeepAliveResponse更新租约
// 如果租约过期删除所有alive channels
l.recvKeepAlive(resp)
}
}
select {
case <-time.After(retryConnWait):
continue
case <-l.stopCtx.Done():
return l.stopCtx.Err()
}
}
}
// resetRecv 打开一个新的lease stream并开始发送保持活动请求。
func (l *lessor) resetRecv() (pb.Lease_LeaseKeepAliveClient, error) {
sctx, cancel := context.WithCancel(l.stopCtx)
// 建立服务端和客户端连接的lease stream
stream, err := l.remote.LeaseKeepAlive(sctx, l.callOpts...)
if err != nil {
cancel()
return nil, err
}
l.mu.Lock()
defer l.mu.Unlock()
if l.stream != nil && l.streamCancel != nil {
l.streamCancel()
}
l.streamCancel = cancel
l.stream = stream
go l.sendKeepAliveLoop(stream)
return stream, nil
}
// sendKeepAliveLoop 在给定流的生命周期内发送保持活动请求
func (l *lessor) sendKeepAliveLoop(stream pb.Lease_LeaseKeepAliveClient) {
for {
var tosend []LeaseID
now := time.Now()
l.mu.Lock()
for id, ka := range l.keepAlives {
if ka.nextKeepAlive.Before(now) {
tosend = append(tosend, id)
}
}
l.mu.Unlock()
for _, id := range tosend {
r := &pb.LeaseKeepAliveRequest{ID: int64(id)}
if err := stream.Send(r); err != nil {
// TODO do something with this error?
return
}
}
select {
// 每500毫秒执行一次
case <-time.After(500 * time.Millisecond):
case <-stream.Context().Done():
return
case <-l.donec:
return
case <-l.stopCtx.Done():
return
}
}
}
关于续期的新能优化
对于 TTL 的选择,TTL 过长会导致节点异常后,无法及时从 etcd 中删除,影响服务可用性,而过短,则要求 client 频繁发送续期请求。
etcd v3 通过复用 lease 和引入 gRPC,提高了续期的效率
1、etcd v3 版本引入了 lease,上面的代码我们也可以看到,不同 key 若 TTL 相同,可复用同一个 Lease, 显著减少了 Lease 数。
2、同时 etcd v3 版本引入了 gRPC 。通过 gRPC HTTP/2 实现了多路复用,流式传输,同一连接可支持为多个 Lease 续期,能够大大减少连接数,提高续期的效率。
过期 Lease 的删除
上面的代码我们介绍了 etcd 在启动 lease 的时候会启动一个 goroutine revokeExpiredLeases(),他会没500毫秒执行一次清除操作。
func (le *lessor) runLoop() {
defer close(le.doneC)
for {
// 函数最终调用expireExists来完成清除操作
le.revokeExpiredLeases()
le.checkpointScheduledLeases()
select {
case <-time.After(500 * time.Millisecond):
case <-le.stopC:
return
}
}
}
// expireExists returns true if expiry items exist.
// It pops only when expiry item exists.
// "next" is true, to indicate that it may exist in next attempt.
func (le *lessor) expireExists() (l *Lease, ok bool, next bool) {
if le.leaseExpiredNotifier.Len() == 0 {
return nil, false, false
}
item := le.leaseExpiredNotifier.Poll()
l = le.leaseMap[item.id]
if l == nil {
// lease has expired or been revoked
// no need to revoke (nothing is expiry)
le.leaseExpiredNotifier.Unregister() // O(log N)
return nil, false, true
}
now := time.Now()
if now.Before(item.time) /* item.time: expiration time */ {
// Candidate expirations are caught up, reinsert this item
// and no need to revoke (nothing is expiry)
return l, false, false
}
// recheck if revoke is complete after retry interval
item.time = now.Add(le.expiredLeaseRetryInterval)
le.leaseExpiredNotifier.RegisterOrUpdate(item)
return l, true, false
}
etcd Lease 高效淘汰方案最小堆的实现方法的,每次新增 Lease、续期的时候,它会插入、更新一个对象到最小堆中,对象含有 LeaseID 和其到期时间 unixnano,对象之间按到期时间升序排序。
etcd Lessor 主循环每隔 500ms 执行一次撤销 Lease 检查(RevokeExpiredLease),每次轮询堆顶的元素,若已过期则加入到待淘汰列表,直到堆顶的 Lease 过期时间大于当前,则结束本轮轮询。
Lessor 模块会将已确认过期的 LeaseID,保存在一个名为 expiredC 的 channel 中,而 etcd server 的主循环会定期从 channel 中获取 LeaseID,发起 revoke 请求,通过 Raft Log 传递给 Follower 节点。
各个节点收到 revoke Lease 请求后,获取关联到此 Lease 上的 key 列表,从 boltdb 中删除 key,从 Lessor 的 Lease map 内存中删除此 Lease 对象,最后还需要从 boltdb 的 Lease bucket 中删除这个 Lease。
// revokeExpiredLeases finds all leases past their expiry and sends them to expired channel for
// to be revoked.
func (le *lessor) revokeExpiredLeases() {
var ls []*Lease
// rate limit
revokeLimit := leaseRevokeRate / 2
le.mu.RLock()
if le.isPrimary() {
ls = le.findExpiredLeases(revokeLimit)
}
le.mu.RUnlock()
if len(ls) != 0 {
select {
case <-le.stopC:
return
// 已经过期的lease会被放入到expiredC中,然后被上游进行处理
case le.expiredC <- ls:
default:
// the receiver of expiredC is probably busy handling
// other stuff
// let's try this next time after 500ms
}
}
}
checkpoint 机制
对于 lease 的处理都是发生在 leader 节点,如果leader节点挂掉了呢?我们知道会重新发起选举选出新的 leader,那么问题就来了
当你的集群发生 Leader 切换后,新的 Leader 基于 Lease map 信息,按 Lease 过期时间构建一个最小堆时,etcd 早期版本为了优化性能,并未持久化存储 Lease 剩余 TTL 信息,因此重建的时候就会自动给所有 Lease 自动续期了。
然而若较频繁出现 Leader 切换,切换时间小于 Lease 的 TTL,这会导致 Lease 永远无法删除,大量 key 堆积,db 大小超过配额等异常。
为了解决这个问题,所以引入了 checkpoint 机制
一方面,etcd 启动的时候,Leader 节点后台会运行此异步任务,定期批量地将 Lease 剩余的 TTL 基于 Raft Log 同步给 Follower 节点,Follower 节点收到 CheckPoint 请求后,更新内存数据结构 LeaseMap 的剩余 TTL 信息。
另一方面,当 Leader 节点收到 KeepAlive 请求的时候,它也会通过 checkpoint 机制把此 Lease 的剩余 TTL 重置,并同步给 Follower 节点,尽量确保续期后集群各个节点的 Lease 剩余 TTL 一致性。
总结
对于 TTL 的选择,TTL 过长会导致节点异常后,无法及时从 etcd 中删除,影响服务可用性,而过短,则要求 client 频繁发送续期请求。
etcd v3 通过复用 lease 和引入 gRPC,提高了续期的效率
1、etcd v3 版本引入了 lease,上面的代码我们也可以看到,不同 key 若 TTL 相同,可复用同一个 Lease, 显著减少了 Lease 数。
2、同时 etcd v3 版本引入了 gRPC 。通过 gRPC HTTP/2 实现了多路复用,流式传输,同一连接可支持为多个 Lease 续期,能够大大减少连接数,提高续期的效率。
Lease 中过期的删除,使用的结构是最小堆,主循环每隔 500ms 执行一次撤销 Lease 检查(RevokeExpiredLease),每次轮询堆顶的元素,若已过期则加入到待淘汰列表,直到堆顶的 Lease 过期时间大于当前,则结束本轮轮询。
如果 leader 发生频繁节点切换,切换时间小于 Lease 的 TTL,这会导致 Lease 永远无法删除,大量 key 堆积,db 大小超过配额等异常,引入了 checkpoint 机制。
参考
【Load Balancing in gRPC】https://github.com/grpc/grpc/blob/master/doc/load-balancing.md
【文中的代码示例】https://github.com/boilingfrog/etcd-learning/tree/main/discovery
【06 | 租约:如何检测你的客户端存活?】https://time.geekbang.org/column/article/339337
【ETCD中Lease如何续期】https://boilingfrog.github.io/2021/09/06/etcd中lease的续期/