rebase失败后的恢复
记一次翻车现场
记一次翻车的现场,很早之前提的PR后面由于需求的变便去忙别的事情了,等到要做这个需求的我时候,发现已经 落后版本了,并且有很多文件的冲突,然后就用rebase去拉代码解决冲突,然后解完之后推代码,但是之后发现一 个文件在解决冲突的时候丢失了。这时候去查看git提交历史,发现rebase之后找不到这个文件了。
最后如何解决呢,要是把丢失的文件在写一遍,那就真的变成了一名咸鱼了。这时候我们就需要去弄明白rebase 的原理了。

rebase的使用流程
rebase就是把主分支的最新代码拉取自己当前的开发分之上,只不过使用rebase,会形成 更加干净的git线。
那么它的使用流程:
基于forked模式的开发。
1、forked代码仓库 2、 git clone <个⼈仓库地址> 3、 添加远程仓库 git remote add remote <远程仓库地址> 4、 查看远程仓库版本 git remote -v 5、 rebase git pull remote master --rebase 6、 遇到冲突 git add . git rebase --continue git push -f origin XXXXX
rebase失败如何恢复
使用reflog撤销变基
$ git reflog 8c79a588 HEAD@{0}: checkout: moving from JM-5995 to JM-5997 e7b1f794 HEAD@{1}: checkout: moving from JM-5876 to JM-5995 97c945d8 HEAD@{2}: commit: fix response 81888803 HEAD@{3}: commit: sql的整理 427423c2 HEAD@{4}: checkout: moving from master to JM-5876 438a1d75 HEAD@{5}: rebase finished: returning to refs/heads/master 438a1d75 HEAD@{6}: pull remote master --rebase: checkout 438a1d75c4faf8056216980d6538de1fe11e0e4e 753e6308 HEAD@{7}: checkout: moving from JM-5876 to master 427423c2 HEAD@{8}: rebase finished: returning to refs/heads/JM-5876 427423c2 HEAD@{9}: rebase: 外审整改计划修改文档的命名 87627087 HEAD@{10}: rebase: 外审整改计划导入的细节部分修改,增加条款信息的查询 c8b18fc1 HEAD@{11}: pull remote master --rebase: 为甚整改计划修改文档的命名 9e1450c4 HEAD@{12}: pull remote master --rebase: 外审整改计划增加条款项的查询 c25f7ab4 HEAD@{13}: pull remote master --rebase: 修改参数的大小写问题 b16eb983 HEAD@{14}: pull remote master --rebase: 外审整改计划添加详情添加外审计划的信息 c5519548 HEAD@{15}: pull remote master --rebase: 外审整改计划添加是否关联不符合项的查询条件 29819e65 HEAD@{16}: pull remote master --rebase: 外审整改计划修改修改测试文件 4e3a6084 HEAD@{17}: pull remote master --rebase: 外审整改计划修改添加文件上传的功能 2e516dfa HEAD@{18}: pull remote master --rebase: 外审整改计划修改count的查询方式 8e970d7c HEAD@{19}: pull remote master --rebase: 外审整改计划初步提交 1e0fa8b3 HEAD@{20}: pull remote master --rebase: sql 9c384393 HEAD@{21}: pull remote master --rebase: checkout 9c384393b1913f67c4eef633ecdeaa23cc4ce397 8b9129ed HEAD@{22}: checkout: moving from JM-5997 to JM-5876 8c79a588 HEAD@{23}: commit: 修复外审计划错误的查询 9a08a751 HEAD@{24}: commit: fix test response 43969771 HEAD@{25}: commit: code review修改导出的状态码 6b5e693f HEAD@{26}: commit: code review调整错误的返回的位置 010c7c8e HEAD@{27}: commit: code review代码细节修改 deca577b HEAD@{28}: commit: code review代码细节修改 874fed06 HEAD@{29}: commit: 修改导入的模板的路径 9607489f HEAD@{30}: rebase finished: returning to refs/heads/JM-5997 9607489f HEAD@{31}: rebase: 包资源的替换 a4f5fb85 HEAD@{32}: rebase: 包资源的替换
上面是所有的日志 我们可以逐条分析,找到我们rebase的节点 只要输入下面的命令就好了
git reset --hard HEAD@{3}
或者
git reset --hard 81888803
rebase使用的意义
使用rebase的提交历史
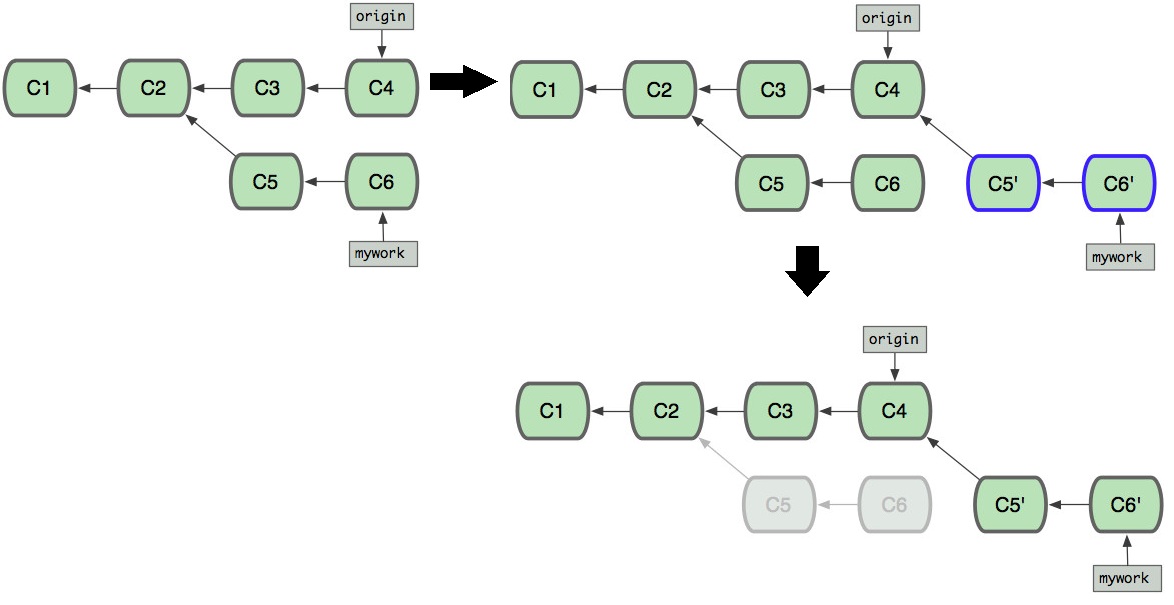
对比merge
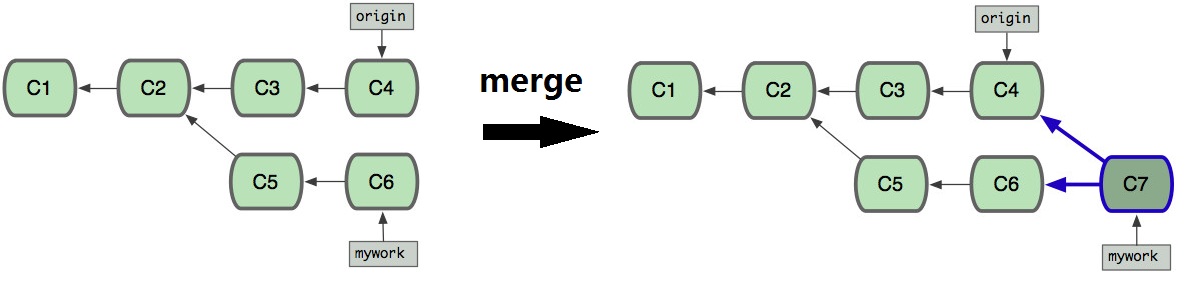
使用rebase会得到一个干净的,线性的提交历史,没有不必要的合并。 使用merge能够保存项目完整的历史,并且避免公共分之上的commit。
rebase工作的原理
为了弄清楚rebase的原理,首先需要弄清楚git的工作原理。
git工作原理
首先我们先来了解下git的模型。 首先我们可以看到在每个项目的下面都有一个.git的隐藏目录
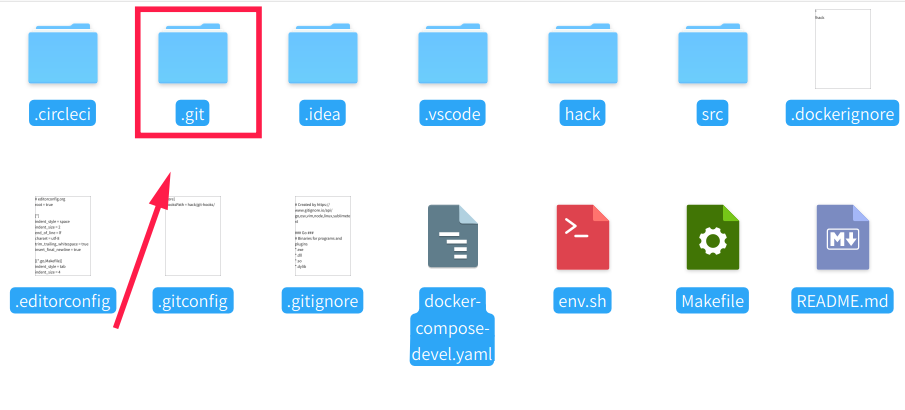
关于git的一切都存储在这个目录里面(全局配置除外)。这里面有一些子目录和文件, 记录到了git所有的信息。
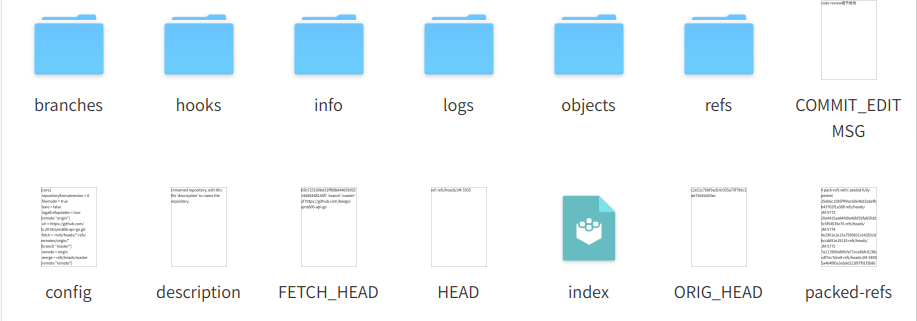
文件里面存储的都是一些配置文件:
-
info:初始化时只有这个文件,用于排除提交规则,与 .gitignore 功能类似。他们的区别在 于.gitignore 这个文件本身会提交到版本库中去,用来保存的是公共需要排除的文件;而info/exclude 这里设置的则是你自己本地需要排除的文件,他不会影响到其他人,也不会提交到版本库中去。
-
hooks:这个目录很容易理解, 主要用来放一些 git 钩子,在指定任务触发前后做一些自定义的配置,这 是另外一个单独的话题,本文不会具体介绍。
-
objects:用于存放所有 git 中的对象,里面存储所有的数据内容,下面单独介绍。
-
logs:用于记录各个分支的移动情况,下面单独介绍。
-
refs:用于记录所有的引用,下面单独介绍。
-
HEAD:文件指示目前被检出的分支
-
index:文件保存暂存区信息
git对象
git是面向对象的!
举个栗子
假如我们init了一个新的仓库,然后提交了两个文件,那么会有那些对象呢?
$ git init $ echo 'aaaaa'>a.txt $ echo 'bbbbb'>b.txt $ git add *.txt
上面提交了两个文件到了暂存区,我们了解到对象都存储在object文件夹中,那我们去到里面看下。
$ tree .git/objects .git/objects ├── cc │ └── c3e7b48da0932cc0f7c4ce7b4fd834c7032fe1 ├── db │ └── 754dbd326f1b7c530672afbbfef8d9223033b7 ├── info └── pack
git cat-file [-t] [-p] 号称git里面的瑞士军刀,我们来剖析下,t可以查看object的类型,-p可 以查看object储存的具体内容。
$ git cat-file -t ccc3e blob $ git cat-file -p ccc3e aaaaa
可以发现object是一个blob类型的节点,内容是aaa,这就是object存储的内容
这里我们遇到了第一种Git object,blob类型,它只储存的是一个文件的内容,不 包括文件名等其他信息。然后将这些信息经过SHA1哈希算法得到对应的哈希值 ccc3e7b48da0932cc0f7c4ce7b4fd834c7032fe1 ,作为object在git中的唯一身份证。
然后我们进行一次commit
git commit -am '[+] init' [master(根提交) d290482] [+] init 2 files changed, 2 insertions(+) create mode 100644 a.txt create mode 100644 b.txt
再次查看object
$ tree .git/objects .git/objects ├── 3b │ └── e060dffd163e01ca6f44dfc6746dda5ae19d5d ├── cc │ └── c3e7b48da0932cc0f7c4ce7b4fd834c7032fe1 ├── d2 │ └── 904827c81ba3c05072d66d1dd466e01bcdee69 ├── db │ └── 754dbd326f1b7c530672afbbfef8d9223033b7 ├── info └── pack
里面变成了四个对象了
让我们‘瑞士军刀’剖析下
$ git cat-file -t 3be0 tree git cat-file -p 3be0 100644 blob ccc3e7b48da0932cc0f7c4ce7b4fd834c7032fe1 a.txt 100644 blob db754dbd326f1b7c530672afbbfef8d9223033b7 b.txt
我们发现这里出现了另一种object类型-tree。它将当前的提交目录打了一个快照,存储了当前提交的目录结构。
再看下两一个object里面的信息
$ git cat-file -p d2904 tree 3be060dffd163e01ca6f44dfc6746dda5ae19d5d author liz <rick.lizhan@gmail.com> 1576828975 +0800 committer liz <rick.lizhan@gmail.com> 1576828975 +0800
里面存储的是提交者的信息
那么有一个问题,一次commit生成的快照是全局的还是提交部分的呢? 我们再来看。 修改a.txt,然后提交,看看新的提交
修改a.txt文件里面的内容为
aaaaa
aaaaa
提交commit
$ git commit -am '[+] init' [master f5af32c] [+] init 1 file changed, 1 insertion(+)
我们再次打印树结构
$ tree .git/objects .git/objects ├── 1c │ └── 30d6ba3439ec5e8e68aed15a79371db2f9be8d ├── 3b │ └── e060dffd163e01ca6f44dfc6746dda5ae19d5d ├── 51 │ └── 200a14c72d35c97979bea3b46bee414e86185b ├── cc │ └── c3e7b48da0932cc0f7c4ce7b4fd834c7032fe1 ├── da │ └── 8ebda5480840ecde47656e10317c55b965ad3b ├── db │ └── 754dbd326f1b7c530672afbbfef8d9223033b7 ├── f5 │ └── af32c14e49bb408de53e4ed22f1b8dd95c2353 ├── info └── pack
对象数量变成了8个也就是之前的2倍,所以可以看出存储的是当前全新的文件快照,而不 是仅仅提交部分的快照。 那么问题来了,这样有什么好处呢,每次会新建一个全新的blob object 其实是Git在时间很空间上的一个取舍,如果我们需要checkout或commit。或对比两个commit 之间的差异。如果存储的只是变更的部分,如果需要拿到一个commit的内容都需要从第一个 提交开始查找,会浪费很多的时间,而存储权限快照的方法就很快了,这种策略相当于通过 空间换时间。
总结下: 当我们新增两个文件的时候,就会有两个数据对象,每个文件都对应一个数据对象。当文件被 修改时,即使新增了一个字母,也会生成一个数据对象。
其次会有一个树对象来维护一些列的数据对象,叫树对象的原因是它持有的不仅可以是数据 对象,还可以是两一个对象。比如某次提交了两个文件和一个文件夹,那么树对象里面就有三 个对象,两个是数据对象,文件夹则用另一个树对象表示。这样递归下去就可以表示任意层 次的文件了。
最后则是提交对象,每个提交对象都有一个树对象,用来表示某一次提交所涉及的文件。除此 以外,每一个提交还有自己的父提交,指向上一次提交的对象。
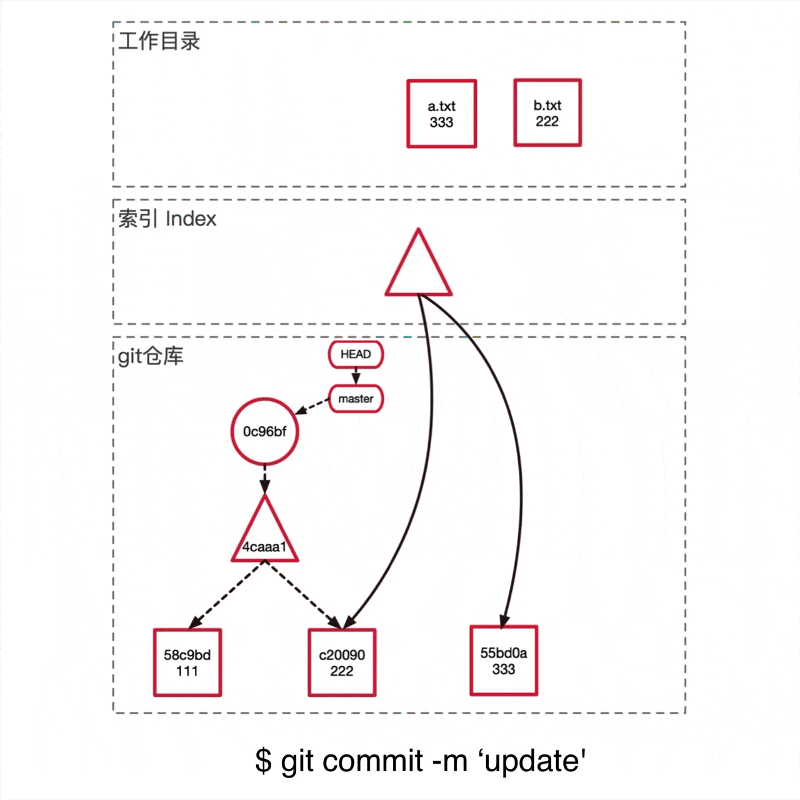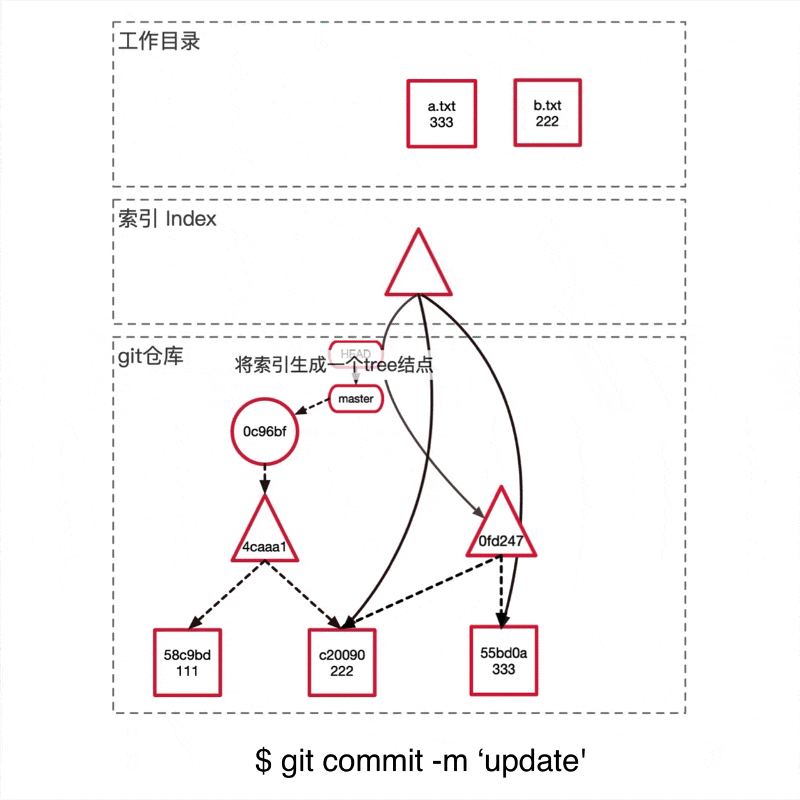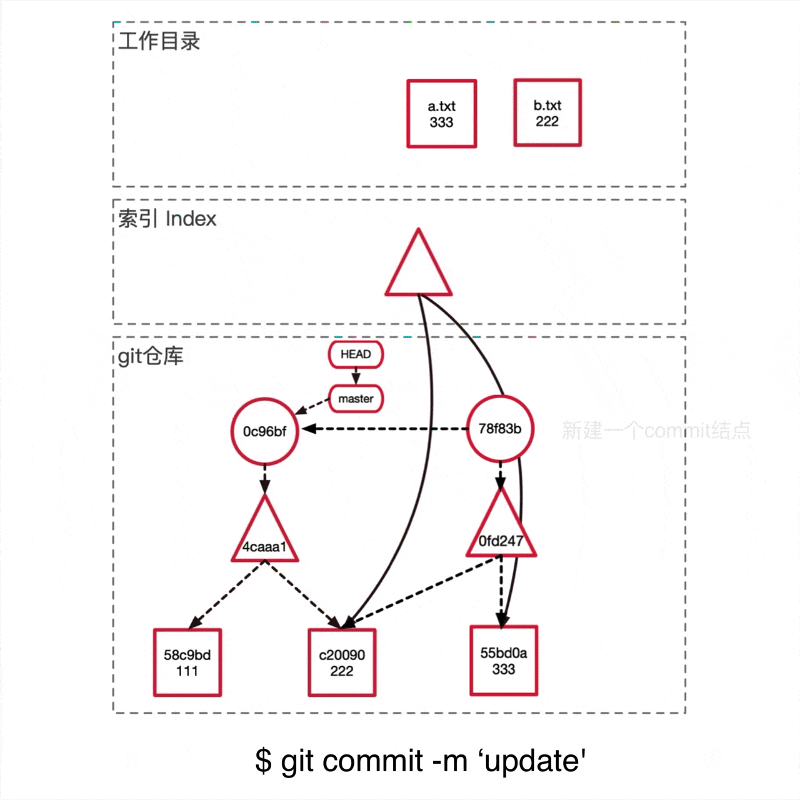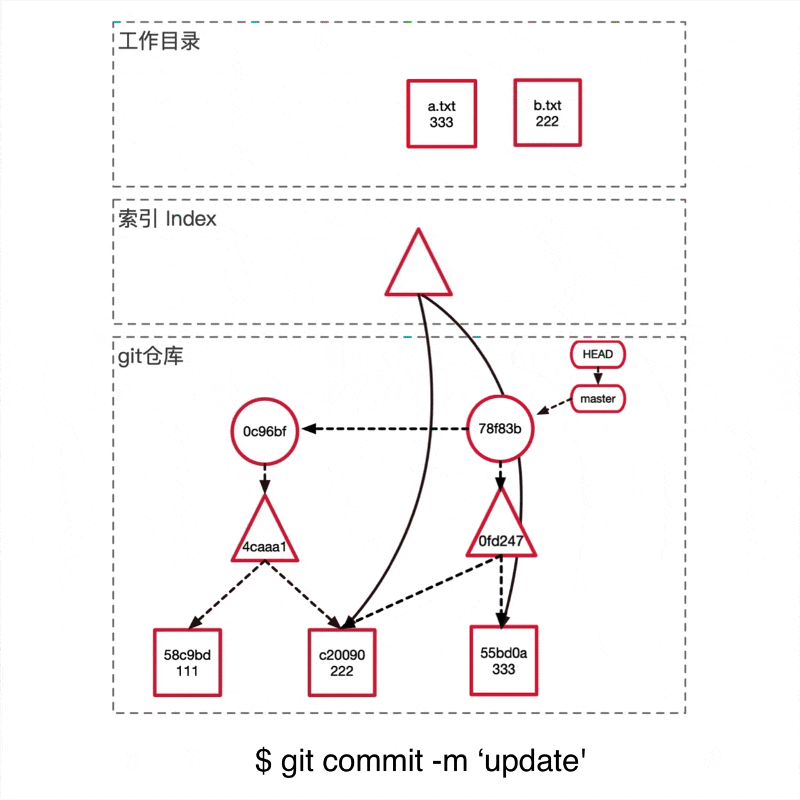
git引用
git是面向对象的,里面的标签和分支都是指向提交对象的指针。
git日志
在 .git/logs 目录中,有一个文件夹和一个 HEAD 文件,每当 HEAD 引用改变了指向的位置,就会在 .git/logs/HEAD 中 添加了一个记录。而 .git/logs/refs/heads 这个目录中则有多个文件,每个文件对应一个分支,记录了这个分支 的指向位置 发生改变的情况。 当我们执行 git reflog 的时候,其实就是读取了 .git/logs/HEAD 这个文件。
rebase的原理
对于rebase的撤销,其实并不是真正意义上的撤销,只是通过reset修改HEAD和当前分支的指向,后面的提交只是没有指针的指向。 但是还是真实存在的。
参考
- 【Git Rebase原理以及黄金准则详解】 https://segmentfault.com/a/1190000005937408
- 【图片引用】https://blog.csdn.net/chenansic/article/details/44122107
- 【从撤销 rebase 谈谈 git 原理】https://juejin.im/post/5a65ac67f265da3e330473f7
- 【这才是真正的Git——Git内部原理】https://juejin.im/post/5df1fc42518825127a036b03