这个问题一般会出现在稍微高端一点的 Java 面试环节。要求面试者不仅对 Java 基础知识熟悉,更重要的是要了解内存模型。
Java 对象模型
HotSpot JVM 使用名为 oops (Ordinary Object Pointers) 的数据结构来表示对象。这些 oops 等同于本地 C 指针。 instanceOops 是一种特殊的 oop,表示 Java 中的对象实例。
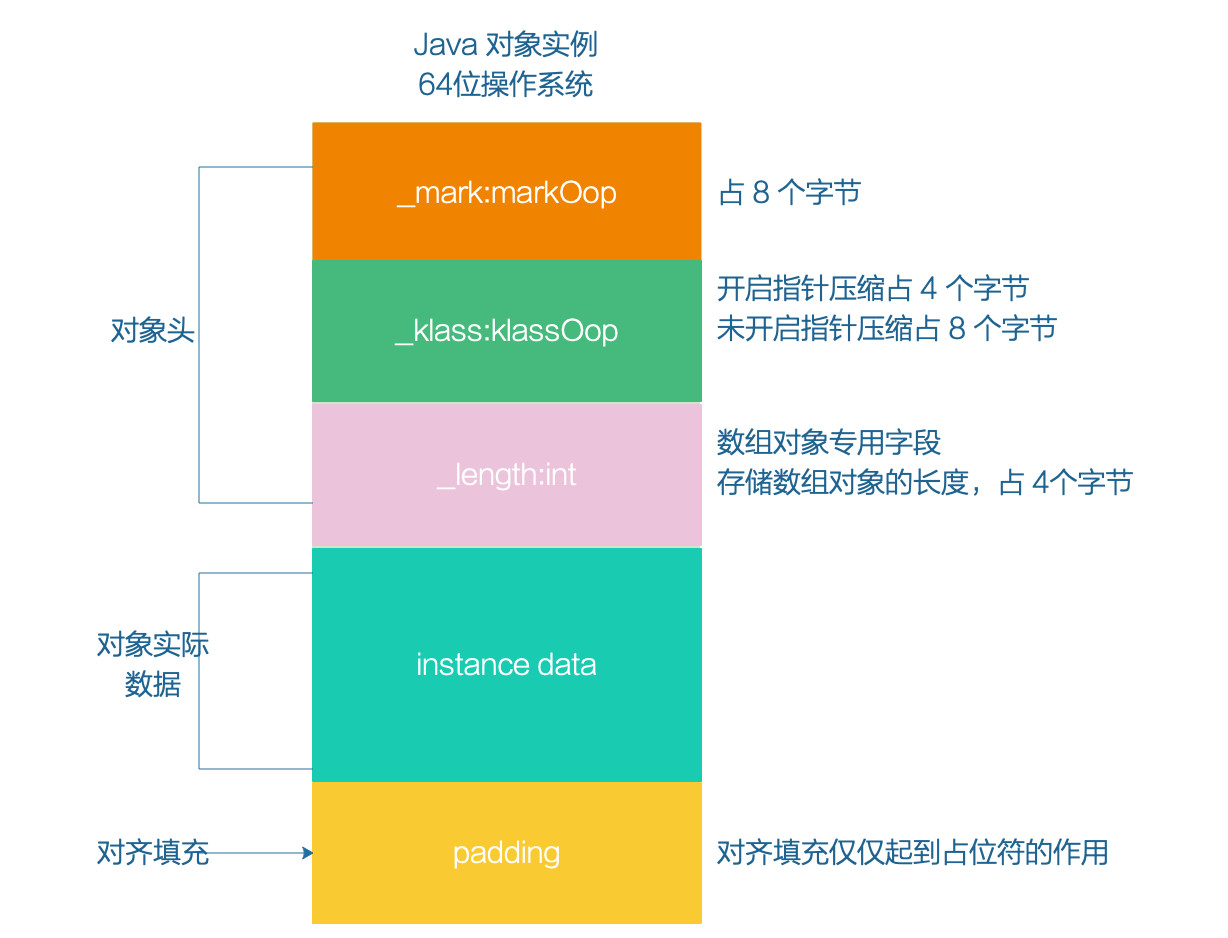
在 Hotspot VM 中,对象在内存中的存储布局分为 3 块区域:
- 对象头(Header)
- 实例数据(Instance Data)
- 对齐填充(Padding)
对象头又包括三部分:MarkWord、元数据指针、数组长度。
- MarkWord:用于存储对象运行时的数据,好比 HashCode、锁状态标志、GC分代年龄等。这部分在 64 位操作系统下占 8 字节,32 位操作系统下占 4 字节。
- 指针:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪一个类的实例。
这部分就涉及到指针压缩的概念,在开启指针压缩的状况下占 4 字节,未开启状况下占 8 字节。 - 数组长度:这部分只有是数组对象才有,若是是非数组对象就没这部分。这部分占 4 字节。
实例数据就不用说了,用于存储对象中的各类类型的字段信息(包括从父类继承来的)。
关于对齐填充,Java 对象的大小默认是按照 8 字节对齐,也就是说 Java 对象的大小必须是 8 字节的倍数。若是算到最后不够 8 字节的话,那么就会进行对齐填充。
那么为何非要进行 8 字节对齐呢?这样岂不是浪费了空间资源?
其实不然,由于 CPU 进行内存访问时,一次寻址的指针大小是 8 字节,正好也是 L1 缓存行的大小。如果不进行内存对齐,则可能出现跨缓存行的情况,这叫做 缓存行污染。
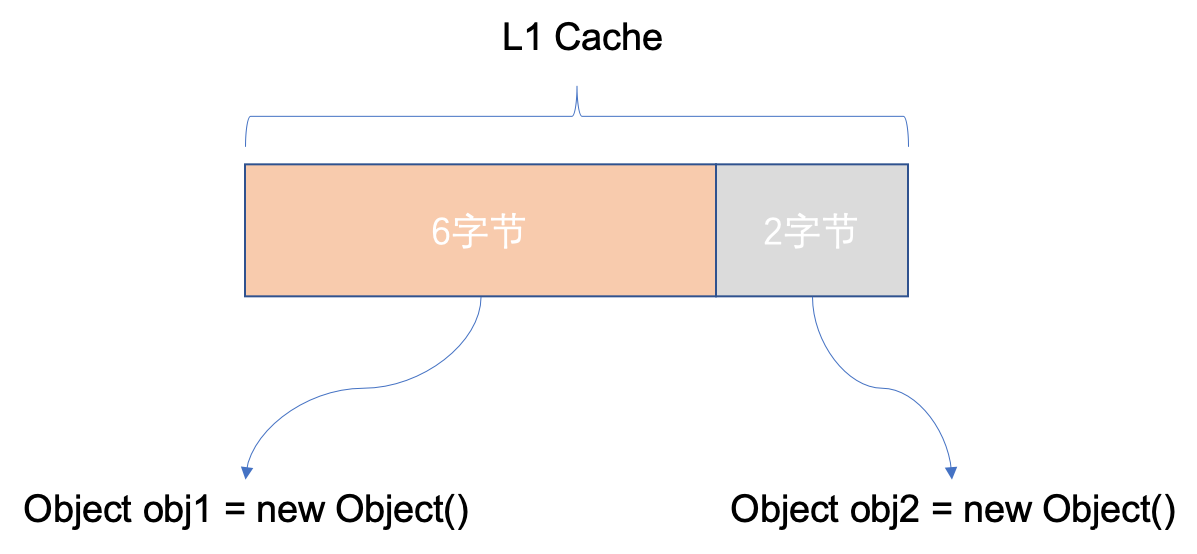
由于当 obj1 对象的字段被修改后,那么 CPU 在访问 obj2 对象时,必须将其重新加载到缓存行,因此影响了程序执行效率。
也就说,8字节对齐,是为了效率的提高,以空间换时间的一种方案。固然你还能够 16 字节对齐,可是 8 字节是最优选择。
正如我们之前看到的,JVM 为对象进行填充,使其大小变为 8 个字节的倍数。使用这些填充后,oops 中的最后三位始终为零。这是因为在二进制中 8 的倍数的数字总是以 000 结尾。
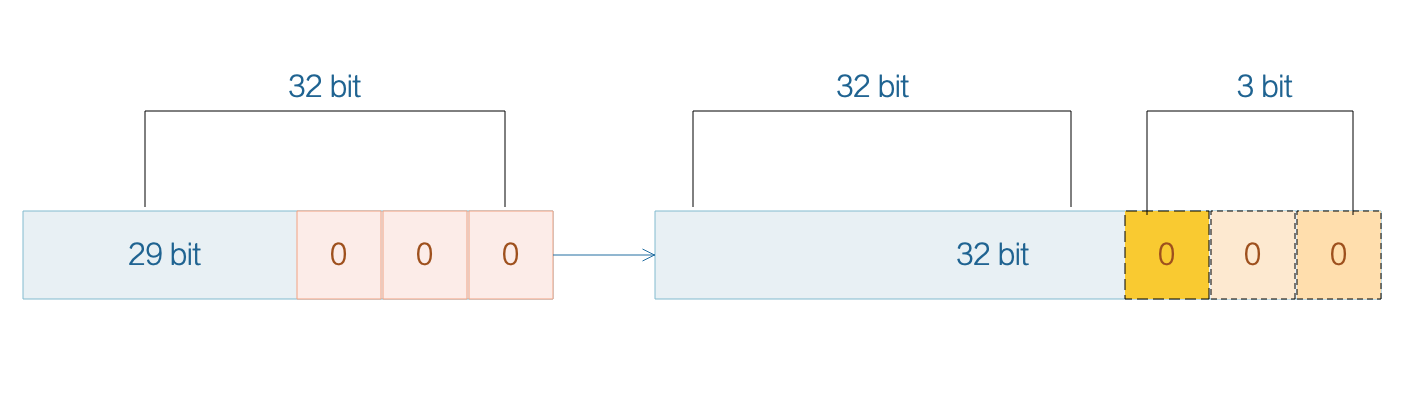
由于 JVM 已经知道最后三位始终为零,因此在堆中存储那些零是没有意义的。相反假设它们存在并存储 3 个其他更重要的位,以此来模拟 35 位的内存地址。现在我们有一个带有 3 个右移零的 32 位地址,所以我们将 35 位指针压缩成 32 位指针。这意味着我们可以在不使用 64 位引用的情况下使用最多 32 GB :
(2(32+3)=235=32 GB) 的堆空间。
当 JVM 需要在内存中找到一个对象时,它将指针向左移动 3 位。另一方面当堆加载指针时,JVM 将指针向右移动 3 位以丢弃先前添加的零。虽然这个操作需要 JVM 执行更多的计算以节省一些空间,不过对于大多数CPU来说,位移是一个非常简单的操作。
要启用 oop 压缩,我们可以使用标志 -XX:+UseCompressedOops 进行调整,只要最大堆大小小于 32 GB。当最大堆大小超过32 GB时,JVM将自动关闭 oop 压缩。
当 Java 堆大小大于 32GB 时也可以使用压缩指针。虽然默认对象对齐是 8 个字节,但可以使用 -XX:ObjectAlignmentInBytes 配置字节值。指定的值应为 2 的幂,并且必须在 8 和 256 的范围内。
我们可以使用压缩指针计算最大可能的堆大小,如下所示:
4 GB * ObjectAlignmentInBytes
例如,当对象对齐为 16 个字节时,通过压缩指针最多可以使用 64 GB 的堆空间。
基本类型占用存储空间和指针压缩
基础对象占用存储空间
Java 基础对象在内存中占用的空间如下:
| 类型 | 占用空间(byte) |
|---|---|
| boolean | 1 |
| byte | 1 |
| short | 2 |
| char | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
另外,引用类型在 32 位系统上每个引用对象占用 4 byte,在 64 位系统上每个引用对象占用 8 byte。
对于 32 位系统,内存地址的宽度就是32位,这就意味着我们最大能获取的内存空间是 2^32(4 G)字节。在 64 位的机器中,理论上我们能获取到的内存容量是 2^64 字节。
当然这只是一个理论值,现实中因为有一堆有关硬件和软件的因素限制,我们能得到的内存要少得多。比如说,Windows 7 Home Basic 64 位最大仅支持 8GB 内存、Home Premium 为 192GB,此外高端的Enterprise、Ultimate 等则支持支持 192GB 的最大内存。
因为系统架构限制,Windows 32位系统能够识别的内存最大在 3.235GB 左右,也就是说 4GB 的内存条有 0.5GB 左右用不了。2GB 内存条或者 2GB+1GB 内存条用 32 位系统丝毫没有影响。
现在一般都是使用 64 位的系统,虽然能支持更大的内存空间,但是也会有另一些问题。
像引用类型在 64 位系统上占用 8 个字节,那么引用对象将会占用更多的堆空间。从而加快了 GC 的发生。其次会降低CPU缓存的命中率,缓存大小是固定的,对象越大能缓存的对象个数就越少。
Java 中基础数据类型是在栈上分配还是在堆上分配?
我们继续深究一下,基本数据类占用内存大小是固定的,那具体是在哪分配的呢,是在堆还是栈还是方法区?大家不妨想想看! 要解答这个问题,首先要看这个数据类型在哪里定义的,有以下三种情况。
- 如果在方法体内定义的,这时候就是在栈上分配的
- 如果是类的成员变量,这时候就是在堆上分配的
- 如果是类的静态成员变量,在方法区上分配的
指针压缩
引用类型在 64 位系统上占用 8 个字节,虽然一个并不大,但是耐不住多。
所以为了解决这个问题,JDK 1.6 开始 64 bit JVM 正式支持了 -XX:+UseCompressedOops (需要jdk1.6.0_14) ,这个参数可以压缩指针。
启用 CompressOops 后,会压缩的对象包括:
- 对象的全局静态变量(即类属性);
- 对象头信息:64 位系统下,原生对象头大小为 16 字节,压缩后为 12 字节;
- 对象的引用类型:64 位系统下,引用类型本身大小为 8 字节,压缩后为 4 字节;
- 对象数组类型:64 位平台下,数组类型本身大小为 24 字节,压缩后 16 字节。
当然压缩也不是万能的,针对一些特殊类型的指针 JVM是不会优化的。 比如:
- 指向非 Heap 的对象指针
- 局部变量、传参、返回值、NULL指针。
CompressedOops 工作原理
32 位内最多可以表示 4GB,64 位地址为 堆的基地址 + 偏移量,当堆内存 < 32GB 时候,在压缩过程中,把 偏移量 / 8 后保存到 32 位地址。在解压再把 32 位地址放大 8 倍,所以启用 CompressedOops 的条件是堆内存要在 4GB * 8=32GB 以内。
JVM 的实现方式是,不再保存所有引用,而是每隔 8 个字节保存一个引用。例如,原来保存每个引用 0、1、2...,现在只保存 0、8、16...。因此,指针压缩后,并不是所有引用都保存在堆中,而是以 8 个字节为间隔保存引用。
在实现上,堆中的引用其实还是按照 0x0、0x1、0x2... 进行存储。只不过当引用被存入 64 位的寄存器时,JVM 将其左移 3 位(相当于末尾添加 3 个0),例如 0x0、0x1、0x2... 分别被转换为 0x0、0x8、0x10。而当从寄存器读出时,JVM 又可以右移 3 位,丢弃末尾的 0。(oop 在堆中是 32 位,在寄存器中是 35 位,2的 35 次方 = 32G。也就是说使用 32 位,来达到 35 位 oop 所能引用的堆内存空间)。
Java 对象到底占用多大内存
前面我们分析了 Java 对象到底都包含哪些东西,所以现在我们可以开始剖析一个 Java 对象到底占用多大内存。
由于现在基本都是 64 位的虚拟机,所以后面的讨论都是基于 64 位虚拟机。 首先记住公式,对象由 对象头 + 实例数据 + padding 填充字节组成,虚拟机规范要求对象所占内存必须是 8 的倍数,padding 就是干这个的。
上面说过对象头由 Markword + 类指针kclass(该指针指向该类型在方法区的元类型) 组成。
Markword
Hotspot 虚拟机文档 “oops/oop.hp” 有对 Markword 字段的定义:
64 bits:
--------
unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
JavaThread:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
PromotedObject:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
size:64 ----------------------------------------------------->| (CMS free block)
这里简单解释下这几种 object:
- normal object,初始 new 出来的对象都是这种状态
- biased object,当某个对象被作为同步锁对象时,会有一个偏向锁,其实就是存储了持有该同步锁的线程 id,关于偏向锁的知识这里就不再赘述了,大家可以自行查阅相关资料。
- CMS promoted object 和 CMS free block 我也不清楚到底是啥,但是看名字似乎跟CMS 垃圾回收器有关,这里我们也可以暂时忽略它们
我们主要关注 normal object, 这种类型的 Object 的 Markword 一共是 8 个字节(64位),其中 25 位暂时没有使用,31 位存储对象的 hash 值(注意这里存储的 hash 值对根据对象地址算出来的 hash 值,不是重写 hashcode 方法里面的返回值),中间有 1 位没有使用,还有 4 位存储对象的 age(分代回收中对象的年龄,超过 15 晋升入老年代),最后三位表示偏向锁标识和锁标识,主要就是用来区分对象的锁状态(未锁定,偏向锁,轻量级锁,重量级锁)
biased object 的对象头 Markword 前 54 位来存储持有该锁的线程 id,这样就没有空间存储 hashcode了,所以 对于没有重写 hashcode 的对象,如果 hashcode 被计算过并存储在对象头中,则该对象作为同步锁时,不会进入偏向锁状态,因为已经没地方存偏向 thread id 了,所以我们在选择同步锁对象时,最好重写该对象的 hashcode 方法,使偏向锁能够生效。
我们来 new 一个空对象:
class ObjA {
}
理论上一个空对象占用内存大小只有对象头信息,对象头占 12 个字节。那么 ObjA.class 应该占用的存储空间就是 12 字节,考虑到 8 字节的对齐填充,那么会补上 4 字节填充到 8 的 2倍,总共就是 16字节。怎么验证我们的结论呢?JDK 提供了一个工具,JOL 全称为 Java Object Layout,是分析 JVM 中对象布局的工具,该工具大量使用了 Unsafe、JVMTI 来解码布局情况。下面我们就使用这个工具来获取一个 Java 对象的大小。
首先引入 Maven 依赖:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.14</version>
</dependency>
我们来看使用:
package com.trace.agent;
import org.openjdk.jol.info.ClassLayout;
import java.util.List;
/**
* @author rickiyang
* @date 2020-12-27
* @Desc TODO
*/
public class ObjSiZeTest {
public static void main(String[] args) {
ClassLayout classLayout = ClassLayout.parseInstance(new ObjA());
System.out.println(classLayout.toPrintable());
}
}
class ObjA {
}
输出:
com.trace.agent.ObjA object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
从上面的结果能看到对象头是 12 个字节,还有 4 个字节的 padding,一共 16 个字节。我们的推测结果没有错。
接着看另一个案例:
package com.trace.agent;
import org.openjdk.jol.info.ClassLayout;
/**
* @author rickiyang
* @date 2020-12-27
* @Desc TODO
*/
public class ObjSiZeTest {
public static void main(String[] args) {
ClassLayout classLayout = ClassLayout.parseInstance(new ObjA());
System.out.println(classLayout.toPrintable());
}
}
class ObjA {
private int i;
private double d;
private Integer io;
}
一共三个属性:
int 类型占 4 个字节 ,double 类型占 8 个字节,Integer 是引用类型,64 位系统占 4 个字节。一共 16 个字节。
加上对象头 12 字节,显然不够 8 的倍数,所以还得 4 字节的填充,加起来就是 32 字节
接着使用 JOL 来分析一下:
com.trace.agent.ObjA object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)
12 4 int ObjA.i 0
16 8 double ObjA.d 0.0
24 4 java.lang.Integer ObjA.io null
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
一共 32 字节。
