一、引言
上一节我们总结了跳跃表的知识,我们知道了有序数组可以用跳跃表实现,也可以用压缩列表来实现,这一篇文章我们来总结一下压缩列表相关的知识。
二、压缩列表简介
定义:压缩列表 ziplist 本质上是一个字节数组,每个元素可以是一个字节数组或一个整数。
PS:Redis的有序集合、散列、列表都直接或间接用到了压缩列表。
三、压缩列表的存储结构
我们通过一张图来直观地分析压缩列表的结构:

- zlbytes :压缩列表的字节长度,占4个字节,因此压缩列表最多有232-1个字节 。
- zltail :压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节。
- zllen :压缩列表的元素个数,占2个字节。zllen无法储存元素个数超过65535(216-1)的压缩列表。
- entryX:压缩列表储存的元素,可以是字节数组或者整数,长度不限。
- zlend:压缩列表的结尾,占1个字节,恒为0xFF。
PS:1字节=8位,二进制里,每位对应2的n次方,1字节最大值为28-1个元素。
PS:必须遍历整个压缩列表才能获取到元素个数。
四、压缩列表的元素的结构
还是通过一张图来说明就比较直观一些:

- previous_entry_length :表示前一个元素的字节长度,占用1个字节或者5个字节,根据前一个元素的长度大小来定:
- 小于254字节 :用1个字节表示previous_entry_length
- 大于或等于254字节 :用5个字节表示previous_entry_length,此时previous_entry_length的第一个字节为固定的0xFE,后面4个字节才真正表示前一个元素的长度。
- encoding :表示当前元素的编码,即content字段储存的数据类型(整数或者字节数组)占用1、2或5个字节,根据content类型来定【详见压缩列表的元素编码表】
- content :储存数据内容,长度不限
PS:假设已知当前元素的首地址p,就可以根据 p-previous_entry_length 推算出前一个元素的首地址。
压缩列表的元素编码
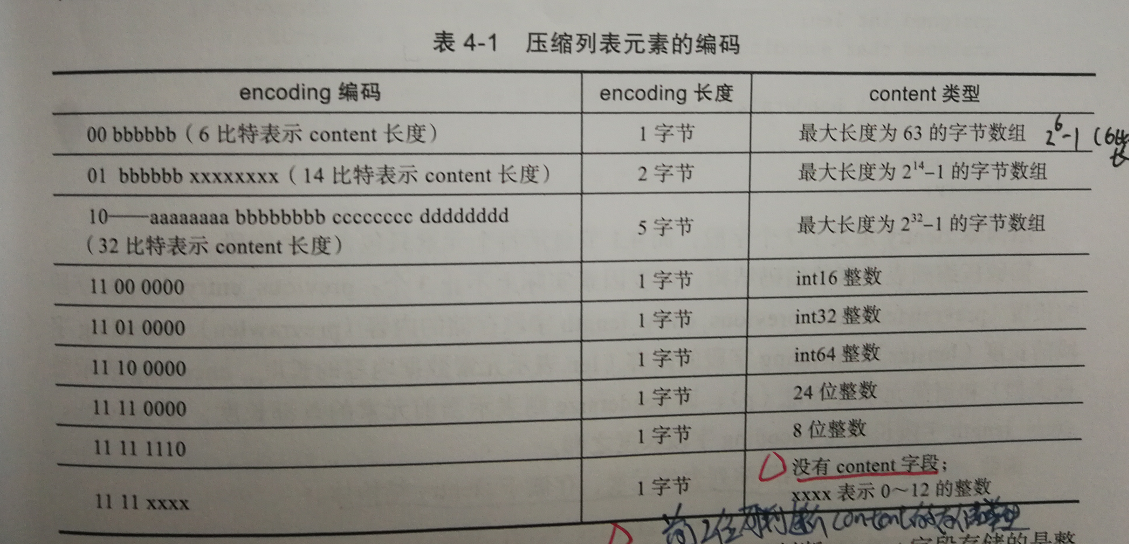
简单总结一下:
- 前两位 :判断类型(整数 OR 字节数组)PS:若为字节数组还可根据前两位判断最大长度
- 字节数组时 :后面的位数标识字节数组的实际长度(2n-1)
- 整数时 :3、4位判断类型,后4为用于表示整数值
五、结构体
意义:由于每次获取前一个元素的内容都需要经过复杂的解码运算,影响效率,所以定义结构体 zlentry 用于表示解码后的压缩列表元素。
PS:结构体实际上是对每个元素的首部【 previous_entry_length 和 encoding 】结构的细分描述。
结构体的字段
- prevrawlensize :previous_entry_length 字段的长度
- prevrawlen :previous_entry_length 字段的内容
- lensize :encoding 字段的长度
- encoding :表示数据类型
- len :数据内容的长度
- p :当前元素的首地址
- headersize :当前元素的首部长度【 previous_entry_length + encoding 】
解码步骤
解码主要用到的是 zipEntry 方法,解码出来的信息储存于 zlentry 结构体:
- 1、解码元素的 previous_entry_length 字段
- 2、解码元素的 encoding 字段
- 3、设置好结构体的相关字段
六、创建压缩列表
创建压缩列表主要用到的方法为:ziplistNew【返回参数为压缩列表的首地址】
创建一个空的压缩列表需要分配的初始空间为:11(4+4+2+1)个字节:
- 4 :zlbytes【压缩列表的字节长度:4字节】
- 4 :zltail【尾元素对起始地址的偏移量:4字节】
- 2 :zlbytes【压缩列表的元素个数:2字节】
- 1 :zlbytes【压缩列表的结尾,固定0xFF:1字节】
七、插入元素
插入元素主要用到的方法为:ziplistInsert【返回参数为压缩列表的首地址】
步骤:
- 将元素内容编码
- 重新分配空间
- 复制数据
将元素内容编码
含义:将元素内容编码就是计算 previous_entry_length 字段、 encoding 字段、 content 字段的内容。
计算前一个元素的长度又根据插入位置分为三种情况:

- P0【插入第一个元素】 :即不存在前一个元素,则 previous_entry_length 为0。
- P1【插入列表中间】 :则entryX+1储存的 previous_entry_length 就是entryX元素的长度,也就是我们需要的长度。
- P1【插入列表末尾】 :则需要进行解码操作,参考上面的解码步骤
重新分配空间
首先定义几个变量:
- curlen :插入元素前列表的长度
- reqlen :新插入元素的长度
- nextdiff :entryX+1元素长度的变化
- forcelarge :标识当nextdiff=4而reqlen<4的情况
PS:需要考虑连锁更新的情况~
详见书本解释~
数据复制
含义:插入元素以后,插入点之后的元素都要向后进行移动,此时底层实现为复制元素到新的内存地址上。
几个名词:
- 偏移量 :待插入元素entryNew的长度
- 移动的数据块长度 :插入位置P后所有元素长度之和 + nextdiff
PS:数据移动之后还需要更新entryX+1元素的 previous_entry_length 字段
八、删除元素
删除元素主要用到的方法为:ziplistDelete【返回参数为压缩列表的首地址】
步骤:
- 计算待删除元素的总长度
- 复制数据
- 重新分配空间
PS:新增元素是从新分配空间小于指针指向的空间时,可能会出现问题;而删除元素时,内存空间是肯定减小的,但是由于是先复制数据再发分配空间,则多余空间的数据已经复制好了,所以从新分配空间就不会产生这个问题。
九、遍历压缩列表
向前遍历:
- 通过 previous_entry_length 字段可以计算前一个元素的首地址,则相对容易遍历
向后遍历:
- 解码当前元素
- 计算当前元素长度
- 获取到最后一个元素的首地址
十、连锁更新
连锁更新其实很好理解,就是更新一个元素的同时引发其他元素的同时更新,这种现象就叫连锁更新:
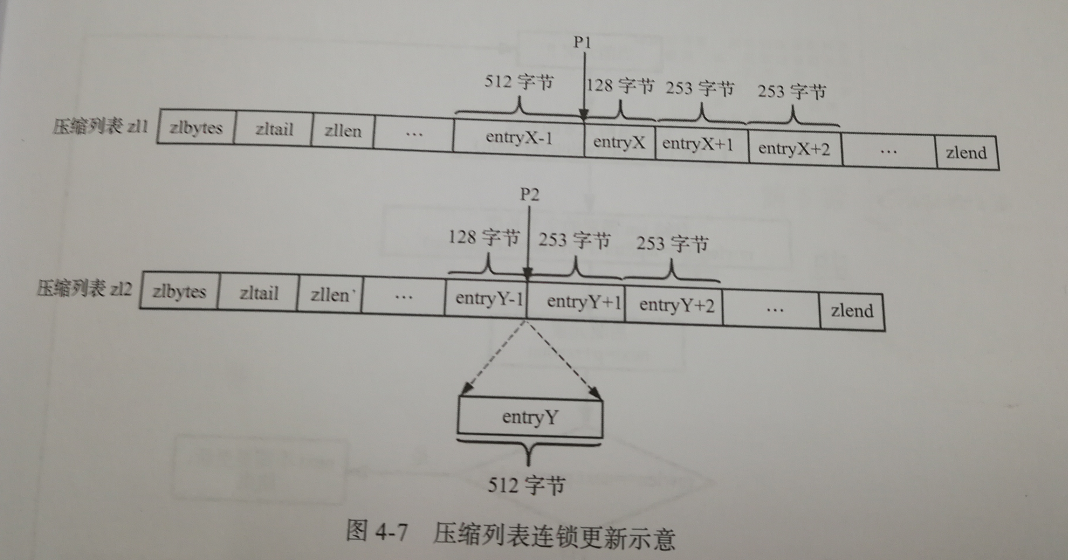
我们可以看到,当在以下两种情况:
- P1位置删除entryX元素
- P2位置插入entryY元素
都会导致连锁更新的发生,为什么呢?
P1位置删除entryX元素
① 删除前,entryX的长度是128字节,所以entryX+1的 previous_entry_length 字段只需要1个字节就可以储存。
② 但是当删除了entryX元素时,entryX+1的前一个元素变成了entryX-1,而entryX-1的长度为512字节,所以此时entryX+1的 previous_entry_length 字段需要用5个字节来储存
③ entryX+1的 previous_entry_length 字段从1个字节变成5个字节以后,entryX+1的长度变成257字节,同时引发entryX+2也需要去改变它的 previous_entry_length 字段长度,从而引发连锁更新...
P2位置插入entryY元素
与上面类似,就不再过多描述了。