一、ceph概念
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。ceph 的统一体现在可以提供文件系统、块存储和对象存储,分布式体现在可以动态扩展。
什么是块存储/对象存储/文件系统存储?
1)对象存储:
也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL 和其他扩展,代表主要有 Swift 、S3 以及 Gluster 等;
2)块存储:
这种接口通常以 QEMU Driver 或者 Kernel Module 的方式存在,这种接口需要实现 Linux 的 Block Device 的接口或者 QEMU 提供的 Block Driver 接口,如 Sheepdog,AWS 的 EBS,青云的云硬盘和阿里云的盘古系统,还有 Ceph 的 RBD(RBD是Ceph面向块存储的接口)。在常见的存储中 DAS、SAN 提供的也是块存储;
3)文件系统存储:
通常意义是支持 POSIX 接口,它跟传统的文件系统如 Ext4 是一个类型的,但区别在于分布式存储提供了并行化的能力,如 Ceph 的 CephFS (CephFS是Ceph面向文件存储的接口),但是有时候又会把 GlusterFS ,HDFS 这种非POSIX接口的类文件存储接口归入此类。当然 NFS、NAS也是属于文件系统存储;
特点:
(1)高性能:
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
(2)高可用性:
a. 副本数可以灵活控制。
b. 支持故障域分隔,数据强一致性。
c. 多种故障场景自动进行修复自愈。
d. 没有单点故障,自动管理。
(3)高可扩展性:
a. 去中心化。
b. 扩展灵活。
c. 随着节点增加而线性增长。
(4)特性丰富:
a. 支持三种存储接口:块存储、文件存储、对象存储。
b. 支持自定义接口,支持多种语言驱动。
二、ceph组件
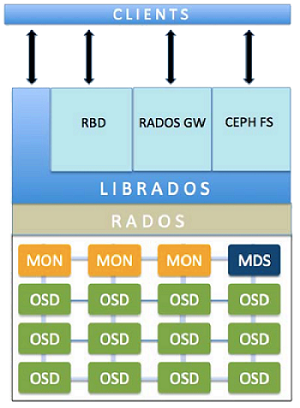
(1)Monitors:监视器,维护集群状态的多种映射,同时提供认证和日志记录服务,包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过 "ceph mon dump"查看 monitor map。
(2)MDS(Metadata Server):Ceph 元数据,主要保存的是Ceph文件系统的元数据。注意:ceph的块存储和ceph对象存储都不需要MDS。
(3)OSD:即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor
(4)RADOS:Reliable Autonomic Distributed Object Store。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
(5)librados:librados库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
(6)RADOSGW:网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift(openstack) 兼容的RESTful API接口。
(7)RBD:块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。
(8)CephFS:Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口。
三、ceph数据存储过程
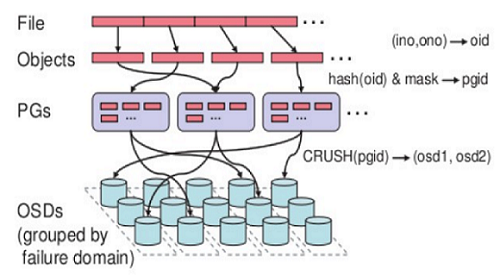
无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成Objects。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成。
ino:即是文件的File ID,用于在全局唯一标识每一个文件
ono:则是分片的编号
Ceph中的寻址至少要经历以下三次映射:
(1)File -> object映射
(2)Object -> PG映射,hash(oid) & mask -> pgid
(3)PG -> OSD映射,CRUSH算法
pool:是ceph存储数据时的逻辑分区,它起到namespace的作用。每个pool包含一定数量(可配置) 的PG。PG里的对象被映射到不同的Object上。pool是分布到整个集群的。 pool可以做故障隔离域,根据不同的用户场景不统一进行隔离。
四、ceph IO流程
1、正常IO流程
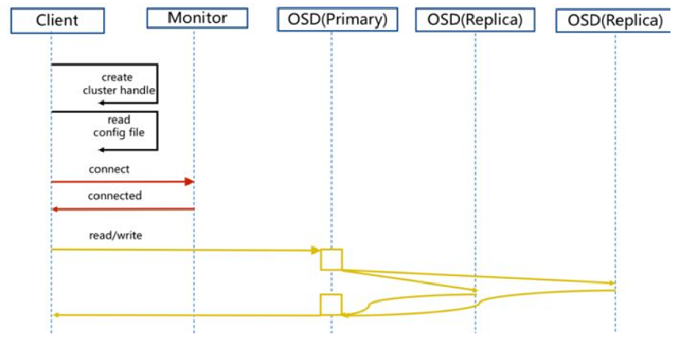
步骤:
1)client 创建cluster handler。
2)client 读取配置文件。
3)client 连接上monitor,获取集群map信息。
4)client 读写io 根据crshmap 算法请求对应的主osd数据节点。
5)主osd数据节点同时写入另外两个副本节点数据。
6)等待主节点以及另外两个副本节点写完数据状态。
7)主节点及副本节点写入状态都成功后,返回给client,io写入完成。
2、新主IO流程
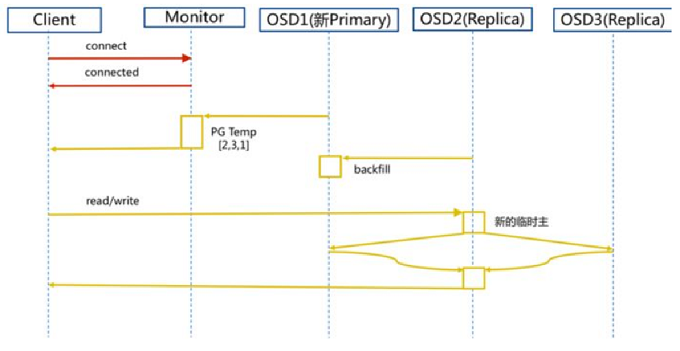
新主IO流程步骤:
1)client连接monitor获取集群map信息。
2)同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
3)临时主osd2会把数据全量同步给新主osd1。
4)client IO读写直接连接临时主osd2进行读写。
5)osd2收到读写io,同时写入另外两副本节点。
6)等待osd2以及另外两副本写入成功。
7)osd2三份数据都写入成功返回给client, 此时client io读写完毕。
8)如果osd1数据同步完毕,临时主osd2会交出主角色。
9)osd1成为主节点,osd2变成副本。
五、ceph 命令
1、检测ceph集群状态:
ceph -s
2、查看osd状态:
ceph osd tree
3、列式pool列表
ceph osd lspools
4、创建pool
ceph osd pool create vms 1024
5、删除pool
ceph osd pool delete data #会提示确认信息(增加命令,如下) ceph osd pool delete data data --yes-i-really-really-mean-it
6、列出pool的详细信息
ceph osd dump | grep pool
六、ceph对接openstack环境
1、客户端要有cent用户(ceph的专有用户)
useradd cent && echo "123" | passwd --stdin cent echo -e 'Defaults:cent !requiretty cent ALL = (root) NOPASSWD:ALL' | tee /etc/sudoers.d/ceph chmod 440 /etc/sudoers.d/ceph
2、openstack部署ceph(安装软件包)
yum install python-rbd yum install ceph-common
3、在ceph部署节点上为openstack节点安装ceph
ceph-deploy install controller ceph-deploy admin controller
4、在openstack客户端执行授予权限的命令
sudo chmod 644 /etc/ceph/ceph.client.admin.keyring
5、在一个ceph节点上创建pool
ceph osd pool create images 1024 ceph osd pool create vms 1024 ceph osd pool create volumes 1024 ceph osd lspools
6、在ceph集群中创建glance和cinder用户,只需在一个ceph节点上操作即可
ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=images' ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=vms, allow rx pool=images' nova使用cinder用户,就不单独创建了
7、拷贝ceph-ring, 只需在一个ceph节点上操作即可:
ceph auth get-or-create client.glance > /etc/ceph/ceph.client.glance.keyring ceph auth get-or-create client.cinder > /etc/ceph/ceph.client.cinder.keyring
8、更改文件的权限(所有客户端节点均执行)
chown glance:glance /etc/ceph/ceph.client.glance.keyring chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring
9、更改libvirt权限(只需在nova-compute节点上操作即可,每个计算节点都做)
uuidgen 940f0485-e206-4b49-b878-dcd0cb9c70a4
cat > secret.xml <<EOF <secret ephemeral='no' private='no'> <uuid>940f0485-e206-4b49-b878-dcd0cb9c70a4</uuid> <usage type='ceph'> <name>client.cinder secret</name> </usage> </secret> EOF
将 secret.xml 拷贝到所有compute节点,并执行::
virsh secret-define --file secret.xml ceph auth get-key client.cinder > ./client.cinder.key virsh secret-set-value --secret 940f0485-e206-4b49-b878-dcd0cb9c70a4 --base64 $(cat ./client.cinder.key)
10、配置Glance, 在所有的controller节点上做如下更改:
vim /etc/glance/glance-api.conf
[DEFAULT] default_store = rbd [glance_store] stores = rbd default_store = rbd rbd_store_pool = images rbd_store_user = glance rbd_store_ceph_conf = /etc/ceph/ceph.conf rbd_store_chunk_size = 8
systemctl restart openstack-glance-api.service
创建image验证:
openstack image create "cirros" --file cirros-0.3.3-x86_64-disk.img.img --disk-format qcow2 --container-format bare --public rbd ls images #有输出镜像说明成功了
11、配置cinder(/etc/cinder/cinder.conf)
[DEFAULT] enabled_backends = lvm,ceph [ceph] volume_driver = cinder.volume.drivers.rbd.RBDDriver rbd_pool = volumes rbd_ceph_conf = /etc/ceph/ceph.conf rbd_flatten_volume_from_snapshot = false rbd_max_clone_depth = 5 rbd_store_chunk_size = 4 rados_connect_timeout = -1 glance_api_version = 2 rbd_user = cinder rbd_secret_uuid = 940f0485-e206-4b49-b878-dcd0cb9c70a4 volume_backend_name=ceph
systemctl restart openstack-cinder-api.service openstack-cinder-scheduler.service openstack-cinder-volume.service rbd ls volumes
12、配置nova(/etc/nova/nova.conf)
[libvirt] virt_type=qemu images_type = rbd images_rbd_pool = vms images_rbd_ceph_conf = /etc/ceph/ceph.conf rbd_user = cinder rbd_secret_uuid = 940f0485-e206-4b49-b878-dcd0cb9c70a4
systemctl restart openstack-nova-api.service openstack-nova-consoleauth.service openstack-nova-scheduler.service openstack-nova-compute.service openstack-nova-cert.service
七、ceph添加/删除osd
1、添加osd
(1)选择一个osd节点,添加好新的硬盘:
(2)显示osd节点中的硬盘,并重置新的osd硬盘:
列出节点磁盘:ceph-deploy disk list rab1 擦净节点磁盘:ceph-deploy disk zap rab1 /dev/sbd(或者)ceph-deploy disk zap rab1:/dev/vdb1
(3)准备Object Storage Daemon:
ceph-deploy osd prepare rab1:/var/lib/ceph/osd1
(4)激活Object Storage Daemon:
ceph-deploy osd activate rab1:/var/lib/ceph/osd1
2、删除osd
(1)把 OSD 踢出集群
ceph osd out osd.4
(2)在相应的节点,停止ceph-osd服务
systemctl stop ceph-osd@4.service systemctl disable ceph-osd@4.service
(3)删除 CRUSH 图的对应 OSD 条目,它就不再接收数据了
ceph osd crush remove osd.4
(4)删除 OSD 认证密钥
ceph auth del osd.4
(5)删除osd.4
ceph osd rm osd.4
3、故障硬盘更换
(1)关闭ceph集群数据迁移(osd硬盘故障,状态变为down)
for i in noout nobackfill norecover noscrub nodeep-scrub;do ceph osd set $i;done
(2)定位故障osd
ceph osd tree | grep -i down
(3)进入osd故障的节点,卸载osd挂载目录
umount /var/lib/ceph/osd/ceph-5
(4)从crush map 中移除osd
ceph osd crush remove osd.5
(5)删除故障osd的密钥
ceph auth del osd.5
(6)删除故障osd
ceph osd rm 5
(7)更换完新硬盘后,注意新硬盘的盘符,并创建osd
(8)添加新的osd(cent用户)
ceph-deploy osd create --data /dev/sdd node3
(9)待新osd添加crush map后,重新开启集群禁用标志
for i in noout nobackfill norecover noscrub nodeep-scrub;do ceph osd unset $i;done
ceph集群经过一段时间的数据迁移后,恢复active+clean状态