序言:
验证码识别平台依靠训练好的神经网络模型对未知的图形进行预判,平台实现api调用计费盈利,一个验证码识别平台除了要有比较完善的神经网络模型还要有一个能够支撑业务的网站架构。
由于api直调方式存在高并发的问题,所以依靠网站服务器来直接实现验证码识别时不显示的,这个时候就需要引入工作机与消息队列的概念:
消息队列:
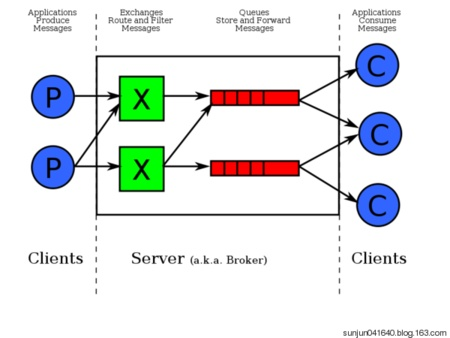
这里我使用的消息队列是RabbitMQ(https://www.rabbitmq.com/),在与传统消息队列对比,RabbitMQ增加了Exchange(交换机)的概念,并且支持direct、topic等多种灵活的规则进行转发消息。
关于RabbitMQ的详细介绍可以参考这篇文章:https://zhuanlan.zhihu.com/p/25069044
工作机:
实际上就是我们之前使用的Quartz服务差不多,用户验证码请求经过消息队列,根据规则转发后,分配给不同的专门做这个业务的服务器,因为识别验证码肯定要高IO密集类型的服务器,把事情交给专业的人来做,效率会很高。
来分析一下进化史,在没有缓存概念之前我们是这样做的:
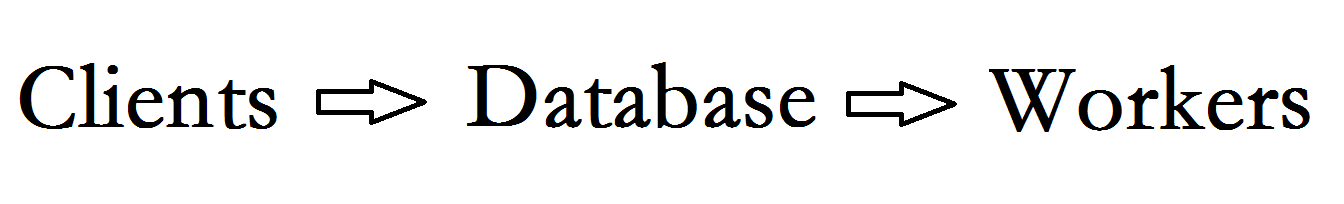
客户端请求过来直接透给数据库,工作机轮询数据库,这种做法首先,多个客户端高并发对数据库进行写操作,对数据库的压力非常大,然后工作机会不断的查询数据库以确保得到最新的消息,前台也需要轮训得到最新的消息,这种架构看来是非常失败的。
然后我们为了解决数据库层面压力过大的问题,引入了No SQL数据库,来缓解高并发读写问题,利用多级缓存架构支撑大量的请求:

引入之后我们的压力问题是解决了,新的问题又来了,因为网络波动问题,客户端的请求不一定每次都能落到数据库上,而且如果服务器发生宕机,这次消息基本就丢失了,我们要实现高可用又不能丢掉消息的持久化,所以我们引入了消息队列:
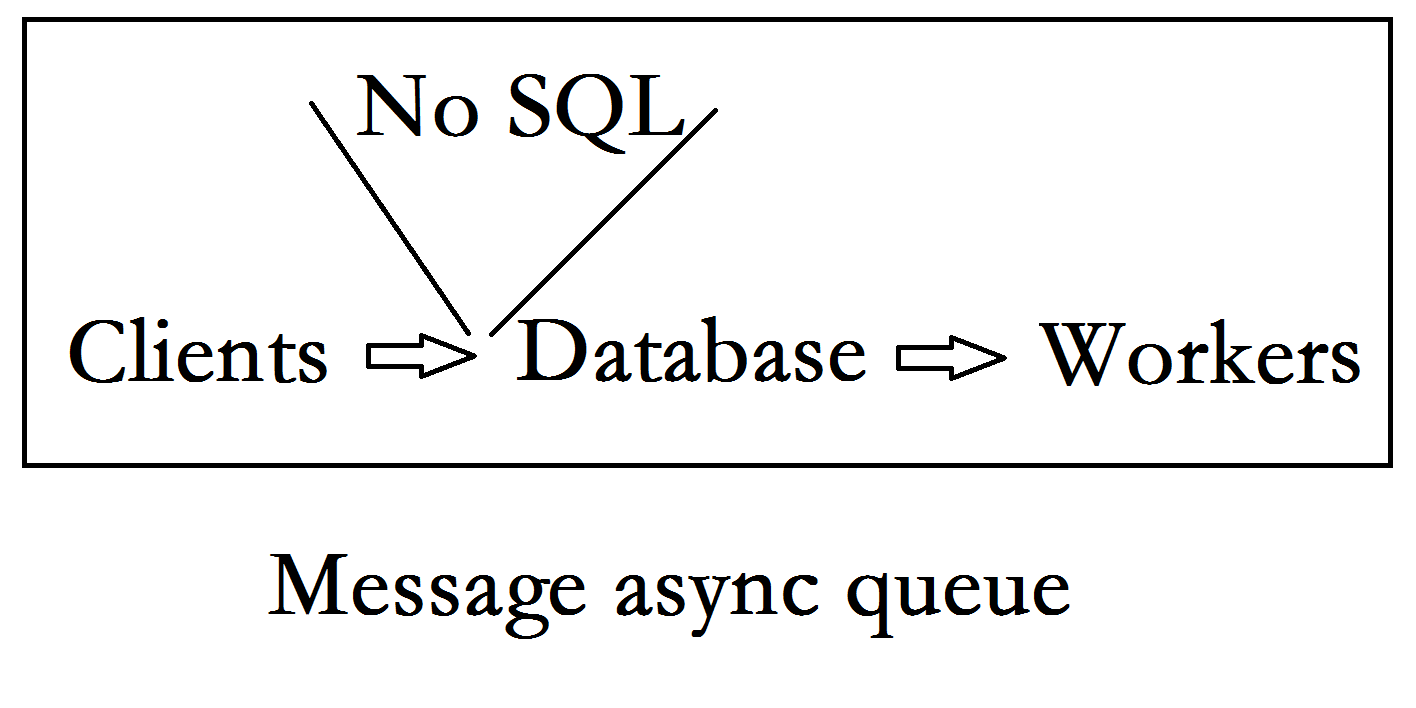
消息队列的特点就是可以让我们的消息加入到队列中,来实现异步计算,RabbitMQ具备消息持久化的特点,当工作机没有确认此次消息时,消息队列会认为你没有接到消息,下次会再次发送给工作机,工作机计算之后需要手动应答,表示消息已经收到。
那么,现在我们对验证码识别平台的基本流程就大概有个认识了:
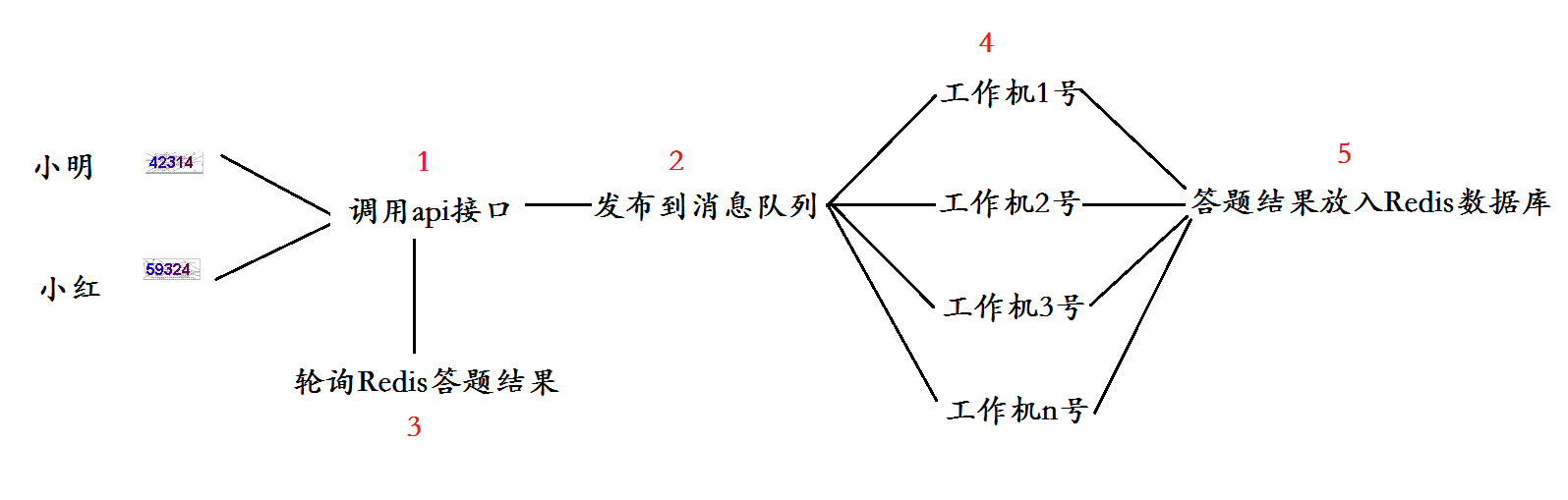
消息队列采用的是竞争模式(http://www.enterpriseintegrationpatterns.com/patterns/messaging/CompetingConsumers.html)
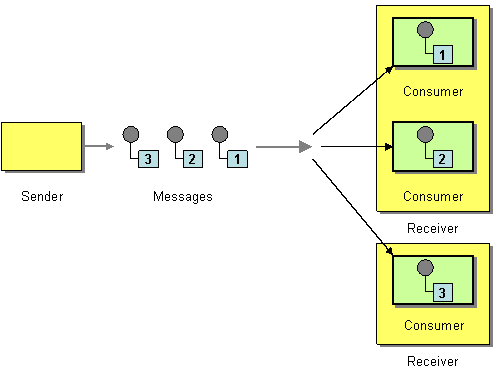
即消息会被多个工作机竞争,谁得到此消息就归属于谁,别的工作机不得再对此消息进行操作。
这样就实现了验证码识别平台的雏形,我目前使用java实现了这样的一个平台,目前能够支撑识别计算业务的运行,但还缺少很多的东西,比如都是单机配置,容易引发单点故障,缺少gateway解决接口压力与安全的问题,在计算方面还有没有引入目前火爆的TensorFlow等等,对于此项目我会持续关注,欢迎大家给我issue。
GitHub:https://github.com/wade-zh/mbus
可以下载https://github.com/wade-zh/mbus/releases/tag/v1.0版本测试一下,我已经部署好了服务。