一、数据准备
1、表结构
CREATE TABLE `emp` (
`ename` varchar(50),
`sex` varchar(50),
`height` double,
`weight` double,
`dept` varchar(50)
)
2、表数据
INSERT INTO emp (ename, sex, height, weight, dept) VALUES('刘备', '男', 170.0, 150.0, 'EP');
INSERT INTO emp (ename, sex, height, weight, dept) VALUES('关羽', '男', 180.0, 190.0, 'EP');
INSERT INTO emp (ename, sex, height, weight, dept) VALUES('张飞', '男', 190.0, 200.0, 'EP');
INSERT INTO emp (ename, sex, height, weight, dept) VALUES('貂蝉', '女', 160.0, 100.0, 'IBT');
INSERT INTO emp (ename, sex, height, weight, dept) VALUES('小乔', '女', 150.0, 90.0, 'IBT');
INSERT INTO emp (ename, sex, height, weight, dept) VALUES('吕布', '男', 200.0, 210.0, 'IBT');
二、开始实验
1、group by sex,dept,ename
SELECT
sex,
dept,
ename,
COUNT(*) AS emp_cnt,
SUM(weight) AS weight_num
FROM emp
GROUP BY
sex,
dept,
ename
WITH ROLLUP
;
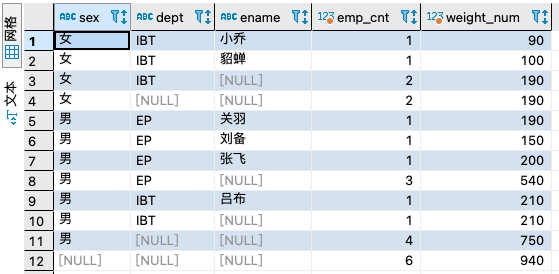
2、group by dept,sex,ename
SELECT
dept,
sex,
ename,
COUNT(*) AS emp_cnt,
SUM(weight) AS weight_num
FROM emp
GROUP BY
dept,
sex,
ename
WITH ROLLUP
;

三、实验总结
rollup,上卷、汇总之意
通过此次试验可以看出,上卷的规律是从group by col3 > col2 > col1
想汇总出较为工整的结果集,需要将group by的col,按粒度大小进行排列,粗粒度的放到前面,细粒度的放到后面
四、参考资料
1、mysql聚合函数rollup和cube
https://blog.csdn.net/liuxiao723846/article/details/48970443