纲要
boss说增加项目平台分析方法:
T检验(独立样本T检验)、线性回归、二元Logistics回归、因子分析、可靠性分析
根本不懂,一脸懵逼状态,分析部确实有人才,反正我是一脸懵
首先解释什么是二元Logistic回归分析吧

官方简介:
链接:https://pythonfordatascience.org/logistic-regression-python/



Logistic regression models are used to analyze the relationship between a dependent variable (DV) and independent variable(s) (IV) when the DV is dichotomous. The DV is the outcome variable, a.k.a. the predicted variable, and the IV(s) are the variables that are believed to have an influence on the outcome, a.k.a. predictor variables. If the model contains 1 IV, then it is a simple logistic regression model, and if the model contains 2+ IVs, then it is a multiple logistic regression model. Assumptions for logistic regression models: The DV is categorical (binary) If there are more than 2 categories in terms of types of outcome, a multinomial logistic regression should be used Independence of observations Cannot be a repeated measures design, i.e. collecting outcomes at two different time points. Independent variables are linearly related to the log odds Absence of multicollinearity Lack of outliers

理解了什么是二元以后,开始找库
需要用的包
这里需要特别说一下,第一天晚上我就用的logit,但结果不对,然后用机器学习搞,发现结果还不对,用spss比对的值
奇怪,最后没办法,只能抱大腿了,因为他们纠结Logit和Logistic的区别,然后有在群里问了下,有大佬给解惑了
而且也有下面文章给解惑
1. 是 statsmodels 的logit模块
2. 是 sklearn.linear_model 的 LogisticRegression模块
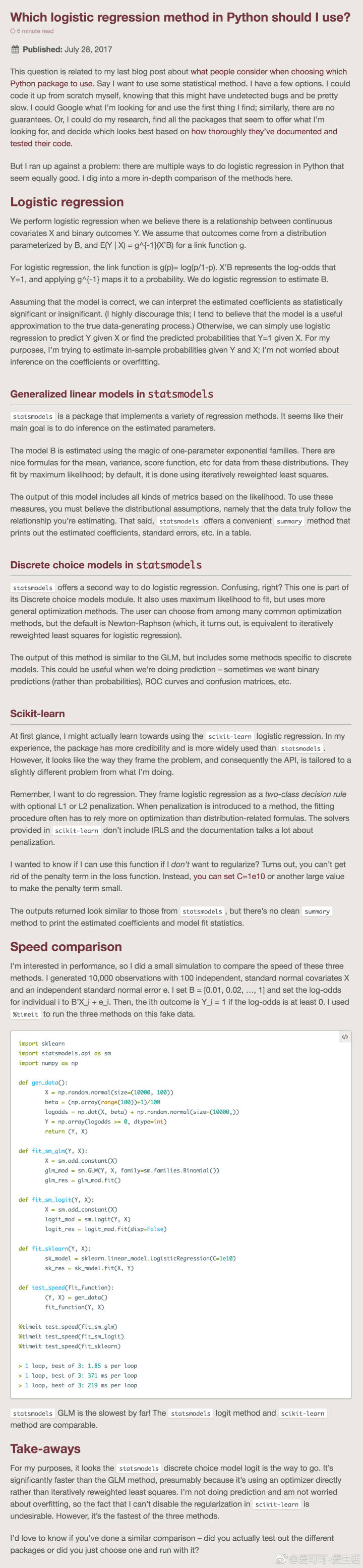
先说第一种方法
首先借鉴文章链接:https://blog.csdn.net/zj360202/article/details/78688070?utm_source=blogxgwz0
解释的比较清楚,但是一定要注意一点就是,截距项,我就是在这个地方出的问题,因为我觉得不重要,就没加
#!/usr/bin/env # -*- coding:utf-8 -*- import pandas as pd import statsmodels.api as sm import pylab as pl import numpy as np from pandas import DataFrame, Series from sklearn.cross_validation import train_test_split from sklearn.linear_model import LogisticRegression from sklearn import metrics from collections import OrderedDict data = { 'y': [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1], 'x': [i for i in range(1, 21)], } df = DataFrame(OrderedDict(data)) df["intercept"] = 1.0 # 截距项,很重要的呦,我就错在这里了 print(df) print("==================") print(len(df)) print(df.columns.values) print(df[df.columns[1:]]) logit = sm.Logit(df['y'], df[df.columns[1:]]) # result = logit.fit() # res = result.summary2() print(res)
这么写我觉得更好,因为上面那么写执行第二遍的时候总是报错:
statsmodels.tools.sm_exceptions.PerfectSeparationError: Perfect separation detected, results not available
我改成x, y变量自己是自己的,就莫名其妙的好了
obj = TwoDimensionalLogisticRegressionModel() data_x = obj.SelectVariableSql( UserID, ProjID, QuesID, xVariable, DatabaseName, TableName, CasesCondition) data_y = obj.SelectVariableSql( UserID, ProjID, QuesID, yVariable, DatabaseName, TableName, CasesCondition) if len(data_x) != len(data_y): raise MyCustomError(retcode=4011) obj.close() df_X = DataFrame(OrderedDict(data_x)) df_Y = DataFrame(OrderedDict(data_y)) df_X["intercept"] = 1.0 # 截距项,很重要的呦,我就错在这里了 logit = sm.Logit(df_Y, df_X) result = logit.fit() res = result.summary() data = [j for j in [i for i in str(res).split(' ')][-3].split(' ') if j != ''][1:] return data
允许二分数值虚拟变量的使用,修改后
obj = TwoDimensionalLogisticRegressionModel() data_x = obj.SelectVariableSql( UserID, ProjID, QuesID, xVariable, DatabaseName, TableName, CasesCondition) data_y = obj.SelectVariableSql( UserID, ProjID, QuesID, yVariable, DatabaseName, TableName, CasesCondition) if len(data_x) != len(data_y): raise MyCustomError(retcode=4011) obj.close() df_X = DataFrame(data_x) df_Y = DataFrame(data_y) # 因变量,0, 1 df_X["intercept"] = 1.0 # 截距项,很重要的呦,我就错在这里了 YColumnList = list(df_Y[yVariable].values) setYColumnList = list(set(YColumnList)) if len(setYColumnList) > 2 or len(setYColumnList) < 2: raise MyCustomError(retcode=4015) else: if len(setYColumnList) == 2 and [0,1] != [int(i) for i in setYColumnList]: newYcolumnsList = [] for i in YColumnList: if i == setYColumnList[0]: newYcolumnsList.append(0) else: newYcolumnsList.append(1) df_Y = DataFrame({yVariable:newYcolumnsList}) logit = sm.Logit(df_Y, df_X) result = logit.fit() res = result.summary() data = [j for j in [i for i in str(res).split(' ')][-3].split(' ') if j != ''] return data[1:]
再次更新后
def TwoDimensionalLogisticRegressionDetail(UserID, ProjID, QuesID, xVariableID, yVariableID, CasesCondition): two_obj = TwoDimensionalLogisticModel() sql_data, xVarName, yVarName = two_obj.showdatas(UserID, ProjID, QuesID, xVariableID, yVariableID, CasesCondition) two_obj.close() df_dropna = DataFrame(sql_data).dropna() df_X = DataFrame() df_Y = DataFrame() # 因变量,0, 1 df_X[xVarName] = df_dropna[xVarName] df_Y[yVarName] = df_dropna[yVarName] df_X["intercept"] = 1.0 # 截距项,很重要的呦,我就错在这里了 YColumnList = list(df_Y[yVarName].values) setYColumnList = list(set(YColumnList)) # print(setYColumnList) if len(setYColumnList) > 2 or len(setYColumnList) < 2: raise MyCustomError(retcode=4015) # else: if len(setYColumnList) == 2 and [0, 1] != [int(i) for i in setYColumnList]: newYcolumnsList = [] for i in YColumnList: if i == setYColumnList[0]: newYcolumnsList.append(0) else: newYcolumnsList.append(1) df_Y = DataFrame({yVarName: newYcolumnsList}) logit = sm.Logit(df_Y, df_X) res = logit.fit() res_all = res.summary() LogLikelihood = [i.strip() for i in str(res_all).split(" ")[6].split(" ") if i][3] # 没找到具体参数, 只能这么分割 index_var = [i.strip() for i in str(res_all).split(" ")[12].split(" ") if i] intercept = [i.strip() for i in str(res_all).split(" ")[13].split(" ") if i] std_err = [index_var[2], intercept[2]] z = [index_var[3], intercept[3]] P_z = [index_var[4], intercept[4]] # 显著性 interval_25 = [index_var[5], intercept[5]] interval_975 = [index_var[6], intercept[6]] Odds_Ratio = [math.e ** i for i in list(res.params)] return { "No_Observations": res.nobs,#No. Observations "Pseudo_R": res.prsquared,# Pseudo R^2 "Log_Likelihood": LogLikelihood, # LogLikelihood "LLNull": res.llnull, "llr_pvalue": res.llr_pvalue, #llr显著性 "coef": list(res.params), # 系数 "std_err": std_err, "Odds_Ratio": Odds_Ratio, "z": z, "P": P_z, #显著性 "interval_25": interval_25, # 区间0.025 "interval_975": interval_975 }
第二种方法,机器学习
参考链接:https://zhuanlan.zhihu.com/p/34217858
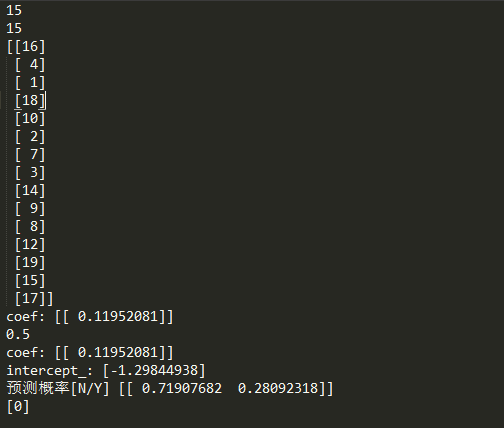
#!/usr/bin/env python # -*- coding:utf-8 -*- from collections import OrderedDict import pandas as pd examDict = { '学习时间': [i for i in range(1, 20)], '通过考试': [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1] } examOrderDict = OrderedDict(examDict) examDF = pd.DataFrame(examOrderDict) # print(examDF.head()) exam_X = examDF.loc[:, "学习时间"] exam_Y = examDF.loc[:, "通过考试"] print(exam_X) # print(exam_Y) from sklearn.cross_validation import train_test_split X_train,X_test,y_train, y_test = train_test_split(exam_X,exam_Y, train_size=0.8) # print(X_train.values) print(len(X_train.values)) X_train = X_train.values.reshape(-1, 1) print(len(X_train)) print(X_train) X_test = X_test.values.reshape(-1, 1) from sklearn.linear_model import LogisticRegression module_1 = LogisticRegression() module_1.fit(X_train, y_train) print("coef:", module_1.coef_) front = module_1.score(X_test,y_test) print(front) print("coef:", module_1.coef_) print("intercept_:", module_1.intercept_) # 预测 pred1 = module_1.predict_proba(3) print("预测概率[N/Y]", pred1) pred2 = module_1.predict(5) print(pred2)
但是,机器学习的这个有问题,就是只抽取了15个值
statsmodels的库链接
Statsmodels:http://www.statsmodels.org/stable/index.html
