层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能, 它使你能在一个轴上拥有多个(两个以上)索引级别。
抽象点说,它使你能以低维度形式处理高维度数据。
先看个Series例子:

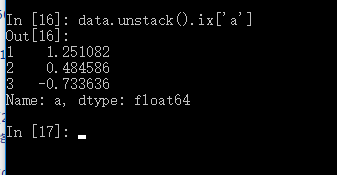
对于一个层次化索引的对象, 选取数据子集的操作很简单:


有时甚至还可以在“内层”中进行选取:

根据层次化索引进行数据重塑
层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。比如,这段数据可以通过其unstack
方法被重新安排到一个DataFrame中:

unstack的逆运算是stack:

DataFrame的分层



In [18]: frame = DataFrame(np.arange(12).reshape((4,3)), index=[list('aabb'), [1, 2, 1, 2]], columns= [['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']]) In [19]: frame Out[19]: Ohio Colorado Green Red Green a 1 0 1 2 2 3 4 5 b 1 6 7 8 2 9 10 11 In [20]:
各层也可以有名字(可以是字符串, 也可以是别的python对象)。如果指定了名称,它们就会显示在控制台输出中(不要将索引名称跟
轴标签混为一谈!):

由于有了分部的列索引, 因此可以轻松选取列分组:

DataFrame 重排分级顺序
有时, 你需要重新调整某条轴上各级别的顺序, 或根据指定级别上的值对数据进行排序。swaplevel接受两个级别编号或名称,
并返回一个互换了级别的新对象(但数据不会发生变化):

而sortlevel 则根据单个级别中的值对数据进行排序(稳定的)。交换级别时, 常常也会用到sortlevel, 这样最终结构就是有序的了

注意:在层次化索引的对象上, 如果索引是按字典方式从外到内排序(即调用sortlevel(0)或sort——index()的结果), 数据
选取操作的性能要好很多。
根据级别汇总统计

使用DataFrame的列

frame = DataFrame({"a":range(7), 'b': range(7, 0, -1), 'c':["one", "one", "one", "two", "two", "two", "two"], "d":[0, 1, 2, 0, 1, 2, 3]})
rest_index 的功能跟set_index刚好相反, 层次化索引的级别会被转移到列里面:
