1.容器指的是“可以容纳其他对象的对象”,这种说法对吗?
对。
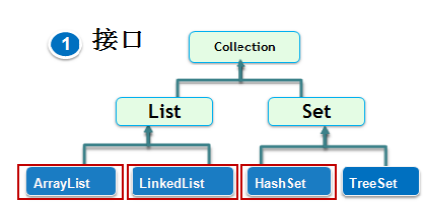
2.Collection/Set/List的联系跟区别?
(1)Collection是Java集合顶级接口,存储一组不唯一,无序的对象;
(2)List接口和Set接口是Collections接口有两个子接口;
(3)List 接口存储一组不唯一,有序(插入顺序)的对象;
Set 接口存储一组唯一,无序的对象;
(4) Collection,List,Set的架构关系图:
3.Set和List的特点跟区别?
(1)List:
1) 是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引来访问List中的无素
,这类似于Java的数组。
2)凡是可以操作索引的方法都是List接口特有方法。
(2)Set:
1)接口存储一组唯一,无序的对象(存入和取出的顺序不一定一致)。
2)操作数据的方法与List类似,Set接口不存在与索引相关的方法。
4.【上机】练习Collection接口中常用的方法
add(Object obj):添加,存储的是对象的引用;
size():容器中元素的实际个数;
remove(Object obj):删除一个元素;
removeAll(Collection c):删除与集合c中的元素相同的元素;
retainAll(Collection c): 只保留当前集合(调用此方法的集合)与集合c(此方法的参数)中相同的元素;
contains(Object obj):判断集合中是否存在元素obj;
isEmpty():判断集合是否为空;
Iterator():生成此集合的迭代器;
5.【上机】下面的代码,效果一致吗? 分析说明之。
Collection c = new HashSet();
代码1:c2.addAll(c)是把【集合c中的元素】添加到集合c2里;
Collection c2 = new HashSet();
Apple a = new Apple();
c.add(a);
c2.addAll(c);
//增加另一个容器中所有的元素!
代码2:c2.add(c)是把【集合c】当作一个元素添加到集合c2里;
Collection c = new HashSet();
Collection c2 = new HashSet();
Apple a = new Apple();
c.add(a);
c2.add(c);
6.想取两个容器中元素的交集,使用哪个方法?
retainAll(Collection c): 只保留当前集合(调用此方法的集合)与集合c(此方法的参数)中相同的元素。
7.说明isEmpty的作用,并说明下面代码有问题吗?
isEmpty():判断集合是否为空,也就是集合中实际元素个数是否为0,由此得知调用此方法时集合是存在的(
如果集合都不存在,也就谈不上为空与否了)。要区分集合为空和集合不存在的含义是不同的。
下列代码Collection c = null,c没有指向任何集合,即集合并不真实存在,调用isEmpty()方法会出现空指针异常。
Collection c = null;
System.out.println(c.isEmpty());
8.我想定义一个数组。该数组既可以放:Dog对象、也可以放Cat对象、还可以放
Integer对象,怎么定义?
代码示例:
Object[] objArr=new Object[5];
objArr[0]=56;
objArr[1]=123;
objArr[2]="Hello world";
objArr[3]=newDog();
objArr[4]=newCat();
9.List接口中增加了一些与顺序相关的操作方法,下面两个方法的作用是什么?
add(int index, E element) :把元素element添加到索引为index的位置;
get(int index):得到索引为index的元素。
10.ArrayList底层使用什么来实现的? LinkedList是用什么实现的?
见下题。
11.说出ArrayLIst、LinkedList、Vector的区别。
ArrayLIst、LinkedList两者都实现了List接口,都具有List中元素有序、不唯一的特点。
ArrayList实现了长度可变的数组,在内存中分配连续空间。遍历元素和随机访问元素的效率比较高;

LinkedList采用链表存储方式。插入、删除元素时效率比较高

Vector和ArrayList的区别联系:见294题。
12.我有一些数据,需要频繁的查询,插入和删除操作非常少,并且没有线程之间的共
享,使用List下面的哪个实现类好一些?
ArrayList。ArrayList实现了长度可变的数组,在内存中分配连续空间。遍历元素和随机访问元素的效率比较高。
13.【上机】针对List中新增的有关顺序的方法,每个都进行测试。并且使用debug
来帮助我们理解程序运行。
add(int index, Object obj):在指定索引位置(index)添加元素obj;
addAll(int index,Collections c):在指定索引位置(index)添加集合c中所有元素;
remove(int index):删除索引位置为index的元素;
set(int index, Object obj):使用元素obj替代指定索引位置上的元素;
get(int index):获取指定索引位置上的元素;
subList(int beginIndex,int endIndex):得到个List对象包含指定索引区间里元素。
14.定义Computer类,使用价格排序。(使用Comparable接口)
(1)定义Computer类,实现Comparable接口:
publicclass Computer implementsComparable {
privatedouble price;//私有属性;
//构造方法;
public Computer(double price) {
super();
this.price = price;
}
//实现Comparable接口中的compareTo方法;
@Override
publicint compareTo(Object o) {
Computer c=(Computer)o;
if(this.price>c.price){
return 1;
}elseif(this.price<c.price){
return -1;
}else{
return 0;
}
}
//重写toString()方法;
@Override
public String toString() {
return"Computer [price=" + price + "]";
}
}
(2)加入TreeSet;
import java.util.Iterator;
import java.util.TreeSet;
publicclass Test {
publicstaticvoid main(String[] args) {
//创建TreeSet;
TreeSet<Computer> treeSet=new TreeSet<Computer>();
//创建Computer对象;
Computer computer1=new Computer(3000);
Computer computer2=new Computer(2650);
Computer computer3=new Computer(5878.8);
Computer computer4=new Computer(6000.78);
//将Computer对象加入到treeSet中;
treeSet.add(computer1);
treeSet.add(computer2);
treeSet.add(computer3);
treeSet.add(computer4);
//为treeSet创建迭代器;
Iterator<Computer> it=treeSet.iterator();
//遍历treeSet
while(it.hasNext()){
System.out.println(it.next());
}
}
}
结果:实现价格排序;
Computer [price=2650.0]
Computer [price=3000.0]
Computer [price=5878.8]
Computer [price=6000.78]
15.equals返回true,hashcode一定相等吗?
是的
16.HashSet和TreeSet的区别
HashSet:
(1)存储结构:采用Hashtable哈希表存储结构
(2)优缺点:
优点:添加速度快,查询速度快,删除速度快
缺点:无序
TreeSet
(1)存储结构: 采用二叉树的存储结构
(2) 优缺点:
优点:有序(排序后的升序)查询速度比List快
(按照内容查询)
缺点:查询速度没有HashSet快
17.使用HashSet存储自定义对象,为什么需要重写hashCode()和equals()?
HashSet存储用的哈希表结构,哈希表需要用到hashCode()和equals()方法:
hashCode()产生hash值以计算内存位置;
当hash值相同时要调用equals()方法进行比较。
如果不重写,调用的是Object的hashcode,而Object的hashCode实际上是地址。系统类已经覆盖了hashCode方法。
所以HashSet存储自定义对象的化要重写hashCode()和equals()方法,目的是告诉程序去除重复元素的策略。
18.使用TreeSet存储多个学生数据,实现按照不同属性值进行排序?
(1)创建一个Student类, 实现Comparable接口;
publicclass Student implementsComparable {
//私有属性;
privateint id;
privateint score;
//getter和setter方法;
publicint getScore() {
return score;
}
publicvoid setScore(int score) {
this.score = score;
}
publicint getId() {
return id;
}
publicvoid setId(int id) {
this.id = id;
}
//构造方法;
public Student(){
}
public Student(int id, int score) {
super();
this.id = id;
this.score = score;
}
@Override
public String toString() {
return"Person [id=" + id + ", score=" + score + "]";
}
//实现compareTo方法,这里是用id比较;
publicint compareTo(Object obj){
Student other=(Student)obj;
int result=this.id-other.id;
return result;
}
}
(2)加入TreeSet;
publicclass Test2 {
publicstaticvoid main(String[] args) {
/*
参看下面创建TreeSet时有两种方法:
代码1:使用无参构造方法TreeSet(),当 Student对象添加进去后,排序时的比较策略用的是Student内部实现的
compareTo方法(内部比较器,此例中按照学生id排序)。
代码2:使用有参构造方法new TreeSet(scoreComp);那么参数scoreComp是什么呢?它表示的是一个外部比较器的对
象。在什么情形下使用呢?当用TreeSet实现排序时,我们不想用Student的内部比较器(也就是说不想用id排序),
想用学生score排序?那怎么办呢?有同学说,把内部比较器改一下呗,改成用score排序的。但改来改去是不是不够
灵活呢?我们有另外一种方法。还记得外部比较器吗?Student的内部比较器我们可以不改,再为Student类定义一个
外部比较器(见以下代码中“定义外部比较器”的部分),定义外部比较器要实现Comparator接口中的compare
(Object obj1,Object obj2)(如果忘记了就往前翻翻吧),在这个方法中实现用分数(score)比较。
以此类推,如果你想用其它属性比较(如年龄,姓名等),可以继续定义相应的外部比较器,使
用方法参见代码2.
*/
/*
代码1:
Set treeSet=new TreeSet();
*/
/*
代码2:
ScoreComp scoreComp=new ScoreComp();//定义一个外部比较器的对象;
Set treeSet=new TreeSet(scoreComp);//把外部比较器对象作为TreeSet构造方法的参数;
*/
Student p1=new Student(1,78);
Student p2=new Student(2,67);
Student p3=new Student(3,96);
Student p4=new Student(4,87);
treeSet.add(p3);
treeSet.add(p4);
treeSet.add(p1);
treeSet.add(p2);
Iterator it=treeSet.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
//定义外部比较器;
class ScoreComp implementsComparator{
publicint compare(Object obj1,Object obj2){
Student p1=(Student)obj1;
Student p2=(Student)obj2;
int result=p1.getScore()-p2.getScore();//用学生分数排序;
return result;
}
}
19.【上机】说明Comparable接口作用。并定义一个学生类,使用分数来比较大小。
自定义类如Student,Product,Person等虽然不是同一类事物,但是都有比较的权利,都可以实现比较的功能。既然
是同一功能(比较),就定义一个接口吧,把方法定义在接口里,由各个类去具体实现。
实现Comparable接口的类需要实现compareTo方法,根据该方法可以根据具体的排序规则对容器中的对象进行排序。
publicclass Student implementsComparable{
privateintid;
private String sex;
private String name;
privateint score;
privateintage;
public Student() {
}
public Student(int id, String sex, String name, int score, int age) {
this.id = id;
this.sex = sex;
this.name = name;
this.score = score;
this.age = age;
}
publicint compareTo(Object o) {
Student s = (Student)o;
returnthis.score-s.score;
}
}
20.Map中,key能否重复?如果重复,会有什么现象?
key:无序,唯一;
添加重复的key不报错,会把之前重复的key覆盖了。
21.Set和Map的集合类名称相似,有没有内在的联系?
HashMap和HashSet这些集合类采用的是哈希表结构,需要用到hashCode哈希码和equals方法。
22.【上机】综合使用List、Map容器存放如下数据, 并从map中取出“李四”。
姓名:张三 年龄:18 体重:90 地址:北京
姓名:李四 年龄:28 体重:50 地址:上海
注:不能使用Javabean封装!
(1)先创建Person类;
publicclass Person {
//私有属性;
private String name;
privateint age;
privatedouble weight;
private String address;
//getter和setter方法(略);
//构造方法;
public Person(String name, int age, double weight, String address) {
super();
this.name = name;
this.age = age;
this.weight = weight;
this.address = address;
}
@Override
public String toString() {
return"Person [name=" + name + ", age=" + age + ", weight=" + weight + ", address=" +
address + "]";
}
}
(2)用List存放数据:
List<Person> personList=new ArrayList<Person>();
Person p1=new Person("张三",18,90,"北京");
Person p2=new Person("李四",28,60,"上海");
//把Person对象添加到personList里;
personList.add(p1);
personList.add(p2);
(3)用Map存放数据:
Map<String,Person> map=new HashMap<String,Person>();
//把Person对象添加到map里,用name作为key,Person对象作为value;
map.put(p1.getName(), p1);
map.put(p2.getName(), p2);
//提取名为“李四”的人的信息,用map.get(key)方法,返回的是此key对应的value值;
System.out.println(map.get("李四"));
23.【上机】使用JavaBean封装,完成上个题目的练习。
24.【上机】写出List、Set、Map中使用泛型的例子。
ArrayList<String> aList=new ArrayList<String>();//只能接收String类型的对象;
Set<Integer> set=new HashSet<Integer>();//只能接收Integer类型的对象;
Map<Integer,String> map=new Map<Integer,String>();//只能接收key类型为Integer,value类型为String。
25. 使用泛型有什么好处?
泛型是JavaSE1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。Java语言引入
泛型的好处是安全简单。
26.【上机】用代码写出遍历List的三种方式
finalintSIZE = list.size();
for (int i = 0; i <SIZE; i++) {
String s = list.get(i);
System.out.print(s+"");
}
System.out.println();
for (String string : list) {
System.out.print(string+"");
}
System.out.println();
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
System.out.print(s+"");
}
}
27.【上机】用代码写出遍历Set的两种方式
1)增强for循环遍历
for (Integer integer : set) {
System.out.print(integer.intValue() + "");
}
2)Iterator 遍历
Iterator<Integer> iterator = set.iterator();
while(iterator.hasNext()){
System.out.print(iterator.next().intValue() + "");
}
28.【上机】用代码写出遍历map的方式
1:得到所有的key
Set<String> set = map.keySet();
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
String key = iterator.next();
System.out.println(key + "--->"+map.get(key));
}
2:得到所有的value
Collection<String> collection = map.values();
for (String string : collection) {
System.out.println("value--->"+string);
}
3:得到所有的key和value
Set<Entry<String, String>> entries = map.entrySet();
Iterator<Entry<String, String>>iterator2 = entries.iterator();
while (iterator2.hasNext()) {
Entry<String, String> entry = iterator2.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "--->"+value);
}
29.采用增强for循环遍历List或者Set,如果List或者Set没有加泛型,能遍历吗?
能。
30.如果我想在遍历时删除元素,采用哪种遍历方式最好?
Iterator接口。Iterator有remove方法可以移除元素。
31.Iterator是一个接口还是类?
Iterator接口。
32.Collection和Collections有什么区别?
Collection是Java提供的集合接口,存储一组不唯一,无序的对象。它有两个子接口List和Set。
Java中还有一个Collections类,专门用来操作集合类 ,它提供一系列静态方法实现对各种集合的搜索、排序、线程
安全化等操作。
33.资源文件有什么作用?
资源文件是用来配置信息的,如数据库信息,键值对信息等。程序里需要有个方法来读取资源文件中的配置信息。如
果没有资源文件,配置信息就得写在代码里;需要修改信息时就不得不修改代码。有了资源文件之后,一旦信息需要
改变,修改资源文件就可以,不用修改代码,更好的保证了代码的封装性。
34.【上机】在src下建立一个资源文件(不包含中文),尝试使用Property类读取里
面的属性。
(1)创建资源文件,我的是fruit.properties; “fruit”可以自定义,后缀名是“properties”。我写的文件内容如下
(水果名对应的水果信息:名称,产地,价钱):
apple=name:apple,place:ShanDong,price:7.00RMB/500g
orange=name:orange,place:GuangDong,price:3.99RMB/500g
banana=name:banana,place:HaiNan,price:2.99RMB/500g
carrot=name:carrot,place:Beijing,price:2.98RMB/500g
(2)代码部分:
publicclass TestProperties {
publicstaticvoid main(String[] args) throws IOException {
File file=new File("fruit.properties");//参数是文件路径;
InputStream is=new FileInputStream(file);//建立此文件的输入流;
Properties p=new Properties();//创建资源文件对象;
p.load(is);//加载资源文件
String fruitInfo=p.getProperty("orange");//getProperty()的参数是资源文件中的key值,可以
输入“apple”,“orange”,“banana”,”carrot”.
System.out.println(fruitInfo);//fruitInfo是通过输入的key值获得的水果信息。
}
}
35.【上机】使用entrySet方法遍历Map。
Set<Entry<String, String>> entries = map.entrySet();
Iterator<Entry<String, String>>iterator2 = entries.iterator();
while (iterator2.hasNext()) {
Entry<String, String> entry = iterator2.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "--->"+value);
}
36.Vector和ArrayList的区别联系
Vector和ArrayList的区别和联系
实现原理相同,功能相同,都是长度可变的数组结构,很多情况下可以互用
两者的主要区别如下
1)Vector是早期JDK接口,ArrayList是替代Vector的新接口
2)Vector线程安全,ArrayList重速度轻安全,线程非安全
3)长度需增长时,Vector默认增长一倍,ArrayList增长50%
37.Hashtable和HashMap的区别联系
实现原理相同,功能相同,底层都是哈希表结构,查询速度快,在很多情况下可以互用
两者的主要区别如下
1)Hashtable是早期JDK提供的接口,HashMap是新版JDK提供的接口
2)Hashtable继承Dictionary类,HashMap实现Map接口
3)Hashtable线程安全,HashMap线程非安全
4)Hashtable不允许null值,HashMap允许null值
38.Java主要容器的选择依据和应用场合
(1) HashTable,Vector类是同步的,而HashMap,ArrayList不是同步的。 因此当在多线程的情况下,应使用
HashTable和 Vector,相反则应使用HashMap,ArrayList.
(2) 除需要排序时使用TreeSet,TreeMap外,都应使用HashSet,HashMap,因为他们 的效率更高。
(3) ArrayList 由数组构建, LinkList由双向链表构建,因此在程序要经常添加,删除元素时速度要快些,最好使用
LinkList,而其他情况下最好使用ArrayList.因 为他提供了更快的随机访问元素的方法。