一. 正则表达式
1. 常见的正则表达式字符
[] 匹配字符集 grep "bl[lo]g" oldboy.txt 表示字符‘l’或者‘o’都可匹配
* 重复前面字符任意次 grep "bl*g" oldboy.txt
.* 表示任意多个字符
[^] 表示非 grep "【^oldboy】" oldboy.txt 匹配文档中不是“oldboy”当中的任意字符
a{n,m} 重复字符a 最少n次,最多m次
a{,m} 重复字符a 最少0次,最多m次 #有些版本这个不支持了
a{n,} 重复字符a 最少n次
a{n} 重复字符a n次
注意:
实际使用中要在大括号前加转义字符 例如:grep "490{2,3}328" oldboy.txt 如果用egrep不用加转义字符
2. 扩展的正则表达式:grep -E或者egrep
a+ : 重复字符a 一次以上 grep -E "490+480" oldboy.txt; 等价于a{1,}
a? : 重复字符a 0次或者1次 等价于a{,1}或者a{0,1}
| :用或的方式查找多个符合条件的字符 注意这里的符号“|” 前后不能有空格,个人理解等价于[]
() : 小括号内表示把多个字符当做一组进行查找,相当于一个字符
例子1.

例子2

二. sed常见用法
常用选项:
-n:取消默认输出,只有经过sed特殊处理的那一行(或者动作)才会被列出来
-e:进行多项编辑,即对输入行应用多条sed命令时使用
-f:指定sed脚本的文件名,直接将sed的动作写在一个档案内,-f filename可以执行filename内的sed动作
-r:可支持扩展正则表达式
-i:直接修改读取的文件内容,而不是由屏幕输出

插入
sed -i '1 i oldboy' aa.txt
sed -i:表示直接编辑修改读取的文件内容 1:表示在第一行插入 i:表示插入 oldboy是插入内容
多点编辑 (sed -e)
sed -e '1,10d' -e 's/My/Your/g' datafile
直接编辑文件内容 (sed -i)
如果只用-e只是把输出的内容做了更改,并不会修改文件中的内容,要修改必须加-i 参数
例如:
sed -i -e '2 i character_set_server=uft8' -e '3 i binlog_format=row' /etc/my.cnf
优化1:消除空格,使用i是在目前的上一行插入数据 sed -i -e '2 i character_set_server=uft8' -e '2 i binlog_format=row' /etc/my.cnf 说明sed是从前到后按命令分步执行的。
优化2:消除空格,使用a是在目前的下一行插入数据,这个使用了转义字符 来换行,这样就不用多点编辑选项-e了
sed -ir "/[mysqld]/ a character_set_server=utf8 binlog_format=row" /etc/mysql/my.cnf
三. sed实战
以网卡eth0的输出信息为例,取出10.0.0.7这个IP地址
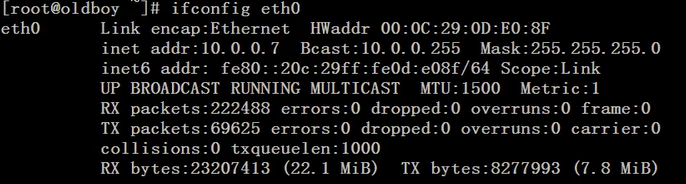
1. sed过滤第二行
ifconfig eth0 |sed -n '/inet addr/p'
或者 ifconfig eth0 | sed -n '2p'
特别要注意后面的p必须在单引号内,p就是输出的意思,n是取消默认输出。输出信息为

2. 用sed的参数sg进行全局替换,格式为sed 's###g'
s#ddd#kkk#g 就是把ddd替换为kkk,如果不写kkk那就是替换为空,要想取出10.0.0.7,需要把它前面和后面的字符都替换为空
1)替换10.0.0.7前面的字符,口诀就是以什么开头,以挨着目标前面的字符结尾
一般是以任意字符开头 ^.* 以addr:结尾,这个例子中也可写成以r:结尾,因为这里r:也是唯一的。写到命令中就是 sed 's#^.*addr:##g' (其实也可以不要^字符)

2)然后,干掉后面的字符,
需要再来一个替换,严格上来讲,要以2个空格Bc开头,任意字符结尾,这里直接用Bc开头也行,sed 's# Bc.*$##g' (这里末尾可不用$)

3. 用sed完全匹配ip地址,用()限定ip地址组,它的作用是相当于一个字符
ifconfig eth0 | sed -rn 's#^.*inet addr:(.*) Bcast.*$#1#gp'
说明:
1. -r(regexp-extended),sed -nr 这样小括号前就不需要用转义字符了
2. sed中1表示命令中的从左边数第一个小括号()的输出内容,同理 2 表示第2个小括号内容,当然这里只有1个小括号,就不存在2的情况了
3. ( ) 在替换命令中是“组”的用法(正则表达式中也是这样),后面可以用1 2 等来分别引用前面括起来的部分。
4. 补充例子
我利用该指令的格式为:sed 's#old#new#g' file 但是利用该格式并不能实现完全匹配替换。例如我要替换文本中的“the”字符串,但是文本内的“other”中间部分也被替换了。如何解决?
sed 's#<old>#new#g' file
这个是匹配单词一样的东西
意思就是限制它的宽度 去掉左右两边之一的那个“>" 符号就相当于放宽那边不限制