HashSet
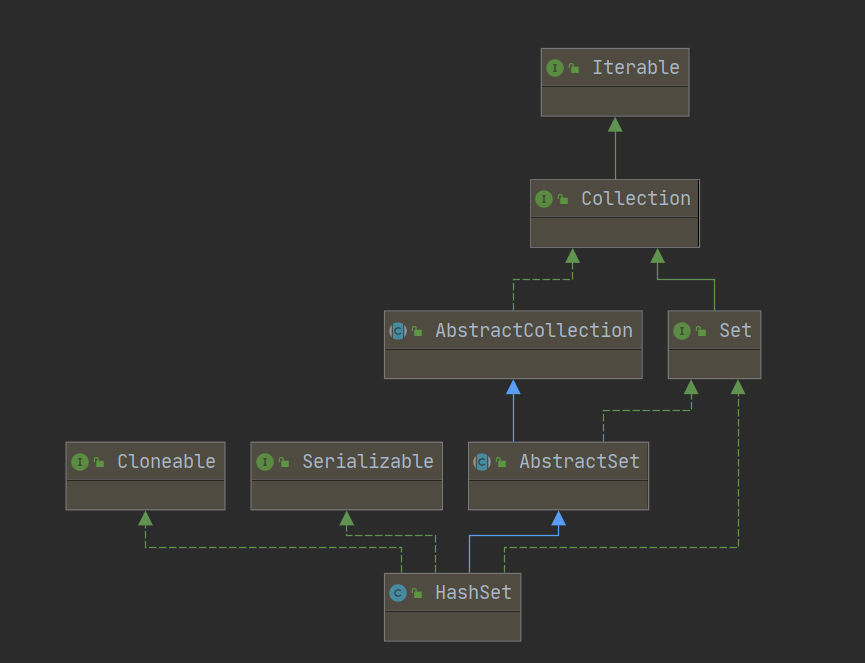
日常开发中,如果我们想要过滤重复的元素,通常使用HashSet来实现。HashSet的继承关系如下所示:
成员变量
//底层是由HashMap实现
private transient HashMap<E,Object> map;
// 虚拟value
private static final Object PRESENT = new Object();
可以看出,HashSet底层其实是由HashMap实现的。由于只需要在key中保存元素,索引采用虚拟对象PRESENT来充当VALUE从而实现HashMap中的键值对。
构造函数
HashSet常用构造方法有四种,其底层都是借助于HashMap的构造方法进行实现的。
//调用HashMap的无参构造
public HashSet() {
map = new HashMap<>();
}
// 给定初始容量
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
// 给定初始容量和加载因子
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
// 根据已有集合元素来构造HashSet
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
add方法
public boolean add(E e) {
//底层调用的HashMap的put方法
return map.put(e, PRESENT)==null;
}
HashSet的add方法底层调用的是HashMap的put方法,根据上篇文章
中对HashMap的源码分析可知,当put方法返回null时,表明在当前这个hashMap中之前不存在该key-value键值对;当hashMap之前存在相同的key时,在添加完毕之后会返回该key所对应的旧值oldValue。因而HashSet的add方法根据HashMap的put方法的返回值来进行去重。
remove方法
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
底层调用HashMap的remove方法进行实现,该方法会返回删除key对应的value,由于所有的value都是PRESENT这个虚拟对象,所以利用这个来进行判断是否删除成功。
其他方法
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public void clear() {
map.clear();
}
LinkedHashSet
如果我们想要元素即唯一又有序,此时LinkedHashSet登场。LinkedHashSet的继承关系如下所示:
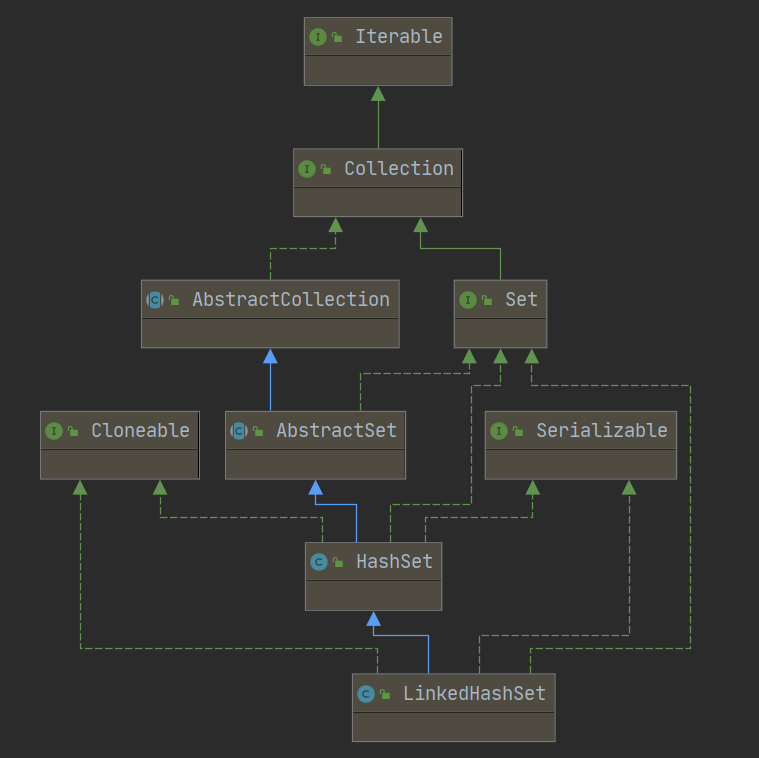
可以看出其继承了HashSet,其构造方法如下所示:
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
可以看出,其构造方法最终都调用了父类HashSet的这个构造方法:
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
因而,LinkedHashSet其底层最后还是由LinkedHashMap实现的。了解了LinkedHashMap的源码之后,LinkedHashSet也就迎刃而解。
总结
HashSet底层借助于HashMap实现,存入的元素实际上是HashMap中的key,value都是相同的虚拟对象PRESENT;LinkedHashSet借助于LinkedHashMap底层实现;HashSet是无序的,因为HashMap中的key是无序的;HashSet中允许存在一个null元素,因为HashMap允许一个key为null;- 非线程安全;
- 没有
get方法;