案例:在阅读文章时,推荐相似的文章.
这个案例简单粗暴,尤其是我看小说的时候,闹书荒的时候,真的很希望有这样的功能.(PS:我现在就职于某小说公司)
那么,如何衡量文章之间的相似度?
在开始讲之前,先提一下elasticsearch.
elasticsearch所使用的索引方式被称为倒排索引.将文档拆分成一个一个的词,然后记录该词出现在哪篇文档的哪个位置.具体解释请参照维基百科.
而在这里,我们将使用和倒排索引类似的方法--词袋模型.
我们有如下一句话.
“Carlos calls the sport futbol. Emily calls the sport soccer.”
| 1 | 2 | 0 | 2 | 2 | 0 | 1 | 0 | 1 | 1 | ... |
| carlos | the | tree | calls | sport | cat | futbal | dog | soccer | emily | ... |
我们忽略单词顺序,将其放入一个语料库中.
假设,我有2篇文章已经进行了统计,如下:
1 0 0 0 5 3 0 0 1 0 0 0 0
3 0 0 0 2 0 0 1 0 1 0 0 0
那么,如何判断2篇文章的相似度?
我们使用向量点乘的方式,计算该值.
1*3 + 0*0 + 0*0 ... + 5*2 + ... = 13
我们计算出相似度为13.
我们再计算下面这一篇:
1 0 0 0 5 3 0 0 1 0 0 0 0
0 0 1 0 0 0 9 0 0 6 0 4 0
0 + 0 + 0 .... = 0
发现相似度为0.
问题:
如果我们把文章扩展2倍,看看会发生什么问题.
原来:
1 0 0 0 5 3 0 0 1 0 0 0 0
3 0 0 0 2 0 0 1 0 1 0 0 0
相似度=13
扩展2倍:
2 0 0 0 10 6 0 0 2 0 0 0 0
6 0 0 0 4 0 0 2 0 2 0 0 2
相似度=52
我们仅仅是将篇幅扩展了2倍而已,然而相似度却变了.我们可以发现,对于越长的文章,这个效果越明显.
那么,应该怎样去解决这个问题?
向量归一化
使用向量归一化,可以将不同长度文章放在同等地位,就不会出现上面的问题了.
计算向量范数:
计算元素平分总和,取其平方根.
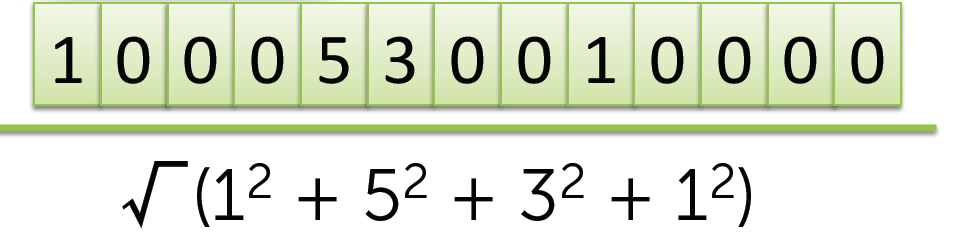
区分常用词和生僻词,并增加生僻词的重要性:
常用词比如说:“the”, “player”, “field”, “goal”
生僻词比如说:“futbol”, “Messi”
为什么要增加生僻词的重要性呢?
很容易理解,通常来说,生僻词更能描述这篇文字的独特之处.
那我们应该如何去做:
在语料库中比较少见的词称为生僻词,增加这些词的权重,等价于强调那些仅在部分文档中出现的词.
同时,对每个单词,根据其出现在语料库中的文档数,减少权重.
我们将其称为局部常见和全局罕见.我们要找的,就是某种局部出现率和全局罕有率的平衡.
TF-IDF(词频--逆向文件频率法):
TF,即统计单词出现次数.
IDF,则是用来根据它来减小这个数的权重.
下面是IDF的计算方法:
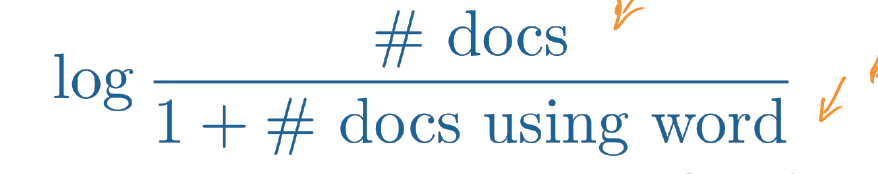
为什么使用这个计算公式?
如公式所示:
当docs using word越大时,公式越接近log1 = 0
当docs using word越小时,公式越接近logLARGE -> large
假如: 在64篇文档中,单词the在63篇文档出现1000次,Messi在3篇文档出现5次.以2为底.
the: log(64/1+63) = 0
Messi: log(64/1+3) = 4
然后tf * idf
the: 1000 * 0 = 0
Messi: 4 * 5 = 20
我们需要一个函数:
定义一个距离,用来衡量相似度.
1. 我们可以计算本文章和其他文章的相似度,返回一个最优结果.

2. 我们可以计算本文章和其他文章的相似度,返回k个最相关的结果(k-近邻搜索).

end
课程:机器学习基础:案例研究(华盛顿大学)
视频链接: https://www.coursera.org/learn/ml-foundations/lecture/EPR3S/clustering-documents-task-overview
week4 Algorithms for retrieval and measuring similarity of documents