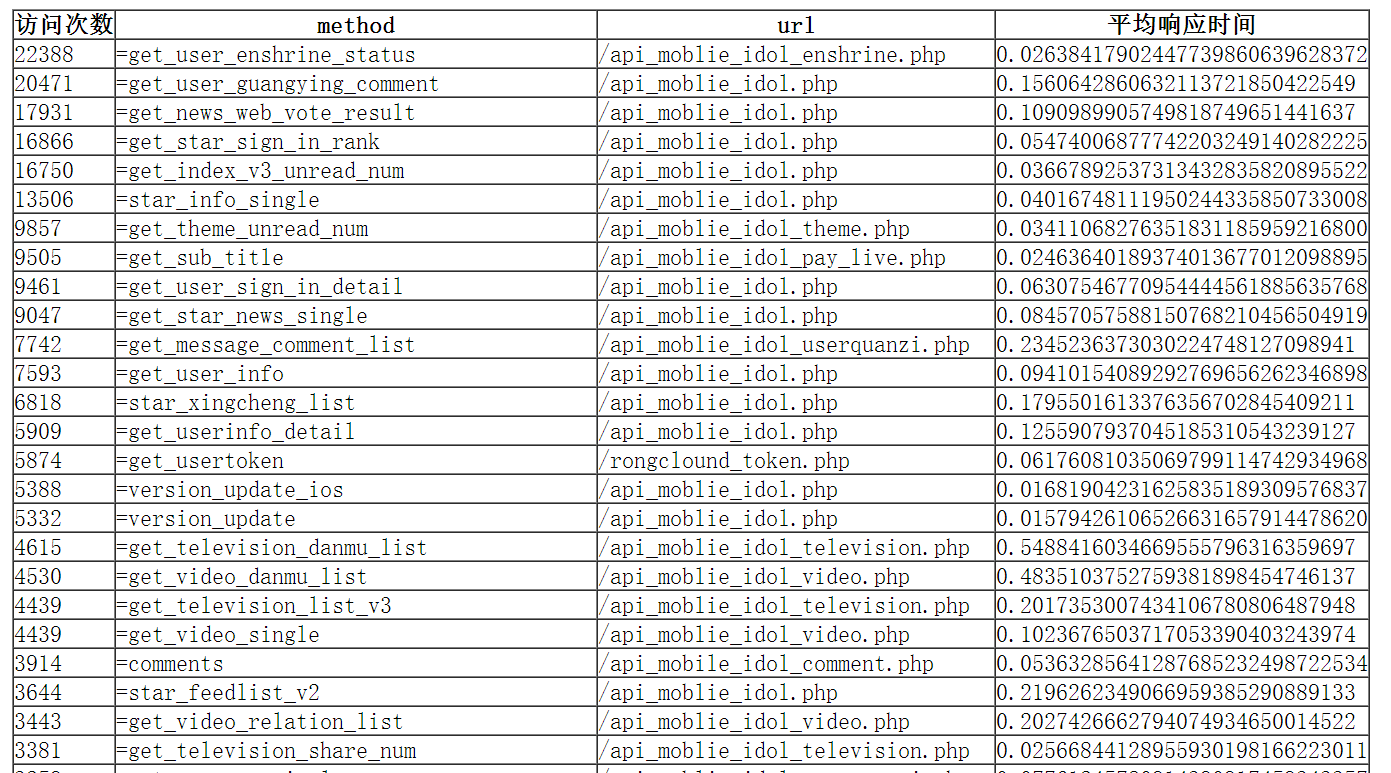
# 公司网站反映很慢,可能是一些页面的访问方法或者页面引起,通过程序统计nginx访问日志的页面和具体的action方法访问次数以及平均响应时间可以为程序开发的同事提供参考定位具体的代码

# 默认的nginx日志
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
现在加上响应时间,方便统计
log_format access '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" "$http_host" "$upstream_response_time" "$request_time"' ;
发现统计出来的响应时间$upstream_response_time无法参与计算,于是去掉引号,变为如下,方便计算:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for" "$http_host" $upstream_response_time $request_time';
不需要去掉双引号也可以,用python处理一下去掉两边的双引号即可,如下:
_time = _time.lstrip('"').rstrip('"')
具体的python代码
#encoding=utf-8 from decimal import Decimal # 找到日志中的top n,日志格式如下 # 192.168.5.46 - - [01/Dec/2017:09:47:21 +0800] "GET /api_moblie_idol.php?action=get_user_guangying_comment&app_platform=android&channelId=S007&starid=6730&version=164&unique_id=A73308A15313C8E34B518CA515288A13&messageid=5a20ae347a11737a288b4738>ui_cid=03908d9fa39c8de124aa01688109b26c&page=7&type=latest HTTP/1.0" 200 70 "-" "-" "223.89.74.82" "data.android.idol001.com" 0.050 0.052 # 统计访问网站php页面和方法的次数,并且生成响应时间 def log_analysis(log_file, dpath, topn = 10): path=log_file shandle = open(path, 'r') count = 1 log_dict = {} log_dict2 = {} total_time = 0.0 while True:
# 最好加上strip()碰到换行就无法识别了 line = shandle.readline().strip() # 如果到了文件末尾就终止 if line == '': break nodes = line.split() # 192.168.9.187 - - [30/Nov/2017:18:28:35 +0800] "GET /api_moblie_idol.phpnique_id=5ACE6943 HTTP/1.0" 200 13950 "-" "idol/5900 (iPhone; iOS 10.3.2; Scale/3.00)" "171.221.169.54" "data.idol001.com" "0.144" "0.144" _url, _time = nodes[6], nodes[-2] # 使用?分割页面,获取url,通过action和&分割出action动作 _tmp = _url.split('action') if len(_tmp) != 2: continue _url = _url.split('?')[0] _method = _tmp[1].split('&')[0] # print 'url:%s, method:%s, time:%s' % (_url,_method,_time) # 如果不是数字就跳出本次循环 if _time == '-': continue try: # {(url,method):count}当做字典的key # 统计url,method的次数 if (_url, _method) not in log_dict: log_dict[(_url, _method)] = 1 else: log_dict[(_url, _method)] = log_dict[(_url, _method)] + 1 # 统计url,method的累计时间 if (_url, _method) not in log_dict2: log_dict2[(_url, _method)] = Decimal(_time) else: log_dict2[(_url, _method)] = Decimal(_time) + Decimal(log_dict2[(_url, _method)]) except Exception,e: continue # print log_dict # print log_dict2 # 关闭文件句柄 shandle.close() # 对字典进行排序 # ('/index', 'post'): 2 rst_list = log_dict.items() # print rst_list for j in range(topn): # 冒泡法根据rst_list中的count排序,找出访问量最大的10个IP for i in range(0,len(rst_list) - 1): if rst_list[i][1] > rst_list[i+1][1]: temp = rst_list[i] rst_list[i] = rst_list[i+1] rst_list[i+1] = temp # 获取 topn 个数 need_list = rst_list[-1:-topn - 1:-1] rt_list = [] for _line, _num in need_list: _tmp_dict = {} _avg_time = Decimal(log_dict2[_line])/Decimal(_num) # print '_avg= %s' % _avg_time _tmp_dict['_num'] = _num _tmp_dict['_avg'] = _avg_time rt_list.append((_line,_tmp_dict)) # print rt_list # 打印出top 10访问日志,并写入网页中 title = 'nginx访问日志' tbody = '' for k,v in rt_list: print v['_num'],k[1],k[0],v['_avg'] tbody += '<tr> <td>%s</td><td>%s</td><td>%s</td><td>%s</td> <tr> ' % (v['_num'],k[1],k[0],v['_avg']) html_tpl = ''' <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>{title}</title> </head> <body> <table border="1" cellspacing="0" cellpadding="0" color='pink'> <thead> <tr cellspacing="0" cellpadding="0"> <th>访问次数</th> <th>method</th> <th>url</th> <th>平均响应时间</th> </tr> </thead> {tbody} </table> </body> </html> ''' html_handle = open(dpath,'w') html_handle.write(html_tpl.format(title = title, tbody = tbody)) html_handle.close() # 函数入口 if __name__ == '__main__': # nginx日志文件 log_file = 'access_android_idol001_com.log' dpath = 'top1000.html' # topn 表示去top多少个 # 不传,默认10个 topn = 1000 log_analysis(log_file,dpath,topn)
最终的效果: