缓存系列之一:buffer、cache与浏览器缓存
一:缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较快的一方起到一个加速访问速度较慢的一方的作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且硬盘也有大小不一的缓存,甚至是物理服务器的raid 卡有也缓存,都是为了起到加速CPU 访问硬盘数据的目的,因为CPU的速度太快了,CPU需要的数据硬盘往往不能在短时间内满足CPU的需求,因此PCU缓存、内存、Raid 卡以及硬盘缓存就在一定程度上满足了CPU的数据需求,即CPU 从缓存读取数据可以大幅提高CPU的工作效率。
1.1:理解buffer和cache:
buffer:缓冲也叫写缓冲,一般用于写操作,可以将数据先写入内存在写入磁盘,buffer 一般用于写缓冲,用于解决不同介质的速度不一致的缓冲,先将数据临时写入到里自己最近的地方,以提高写入速度。
CPU会把数据线写到内存的磁盘缓冲区,然后就认为数据已经写入完成看,然后内核的线程在后面的时间在写入磁盘,所以服务器突然断电会丢失内存中的部分数据。
cache:缓存也叫读缓存,一般用于读操作,CPU读文件从内存读,如果内存没有就先从硬盘读到内存再读到CPU,将需要频繁读取的数据放在里自己最近的缓存区域,下次读取的时候即可快速读取。
1.2:cache的保存位置:
客户端:浏览器
内存:本地服务器、远程服务器
硬盘:本机硬盘、远程服务器硬盘
速度对比:
客户端浏览器-内存-远程内存-硬盘-远程硬盘
1.3:cache的特性:
1.过期时间
2.强制过期,源网站更新图片后CDN是不会更新的,需要强制是图片缓存过期
3.命中率,即缓存的读取命中率
1.4:将内存的数据保存到硬盘,然后清空内存,可能有些内存的数据是进程死掉无法释放的:
#sync # 将缓冲区中的数据快速写入到硬盘
# cat /proc/sys/vm/drop_caches
0
#1是用来清空最近放问过的文件页面缓存
#2是用来清空文件节点缓存和目录项缓存
#3是用来清空1和2所有内容的缓存。
二:用户层缓存:
2.1:DNS 缓存:
2.1.1:默认为60秒,即60秒之内在访问同一个域名就不在进行DNS解析:
查看chrome浏览器的DNS缓存:
chrome://net-internals/#dns

2.1.2:DNS 预获取,仅在HTML 5中支持,当一个页面中包含多个域名的时候浏览器会先尝试解析域名并进行缓存,之后再使用的时候即可直接只有不需要再进行DNS 解析:
2.2:浏览器缓存:
2.2.1:火狐浏览器的缓存位置:

2.2.2:文件的访问时间、最后修改时间和更改时间:
# stat index.php File: ‘index.php’ Size: 4311 Blocks: 16 IO Block: 4096 regular file Device: fd01h/64769d Inode: 68497957 Links: 1 Access: (0755/-rwxr-xr-x) Uid: ( 497/ nginx) Gid: ( 497/ nginx) Access: 2017-07-21 02:00:03.046492759 +0800 # 最后一次读取的时间 Modify: 2016-04-07 18:32:47.000000000 +0800 # 最后一次更改内容导致block内容发生变化的时间 Change: 2017-01-11 15:55:35.872038074 +0800 # 权限等发生更改导致inode发送变化的时间
2.2.3:缓存协商机制之最后修改时间:系统调用会获取文件的最后修改时间,如果没有发生变化就返回给浏览器304的状态码,表示没有发生变化,然后浏览器就使用的本地的缓存展示资源
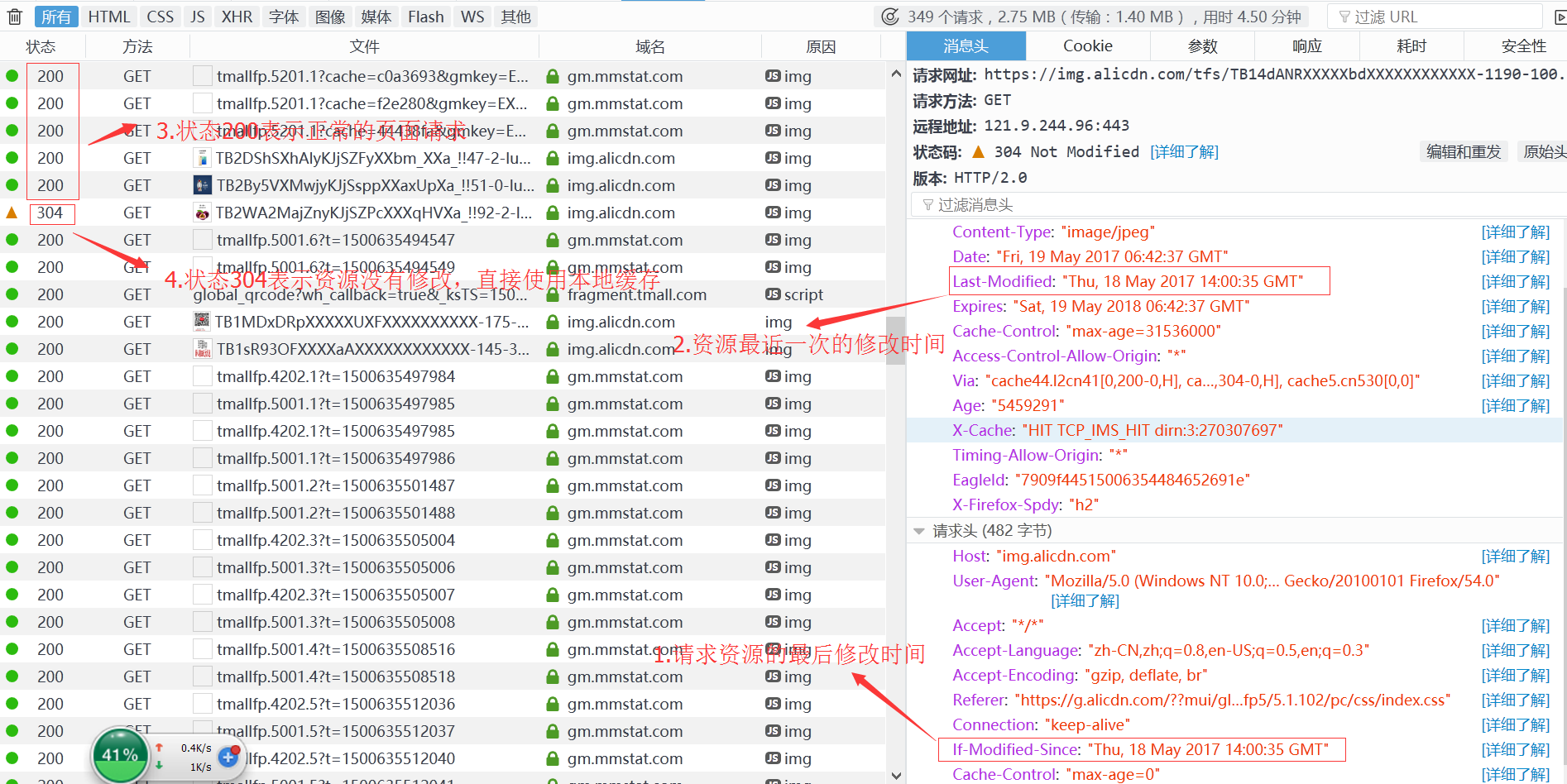
2.2.4:缓存协商之Etag:
浏览器在返回的报文中包含一个etag的标记,然后浏览器将etag保存,再次收到Etag的时候会进行判断,如果Etag没有发生变化就使用本地缓存

2.2.5:缓存协商之过期时间,以上两种都需要发送请求,即不管资源是否过期都要发送请求进行协商,这样会消耗不必要的时间,因此有了缓存的过期时间,即第一次请求资源的时候带一个资源的过期时间,默认为30天,当前这种方式使用的比表较多,但是无法保证客户的时间都是准确并且一致的,因此假如一个最大生存周期,使用用户本地的时间计算缓存数据是否超过多少天,下面的过期时间为2017年,但是缓存的最大生存周期计算为天等于691200秒即2天,过期时间如下:

最大生存周期,单位为秒,根据客户端的时间往后计算是否超出缓存天数
三:关于刷新:
3.1:在浏览器输入地址栏直接按回车:
浏览器的所有没有过期的数据直接使用本地缓存,即没有过期的数据不会发送缓存协商的请求。
3.2:按F5或者浏览器上的刷新按钮:
浏览器会在请求头部附加缓存协商报文,浏览器不能直接使用本地缓存,需要通过验证才可以使用,但是过期时间没有超过日期的缓存不受影响,受影响的是最后修改时间和Etag。
3.3:ctrl+F5或者是按住ctrl+刷新,这是强制刷新,浏览器将发送所有的请求到服务器,不会使用本地缓存
3.4:如何让客户端获取最新的服务器数据资源:
3.4.1:更改资源名称,这样每次都得改,比较麻烦而且容易出错
3.4.2:增加时间戳,新版本的使用较新的时间戳,浏览器发现时间较新就会获取新的资源,例如xxx.js?20170724比xxx.js?20170101新
3.4.3:静态资源使用CDN要加参数,比如URL 可以带参数,带参数的话CND会对该url进行hash计算,当源url资源发送变化(故意的把参数更改,因为静态资源更新了,要求CND也更新)CDN 发现hash值不一样就会进行更新,另外CDN 可以根据后缀名判断加不加参数,即某些后缀的有参数有些后缀没有参数