MapReduce是并发计算处理海量数据的框架;它在hadoop里承担了核心计算框架的角色;并不是所有的大数据处理都要用MapReduce,而是MapReduce是处理海量数据的分布式计算框架
框架解决了:数据的存储(存储在hdsf文件系统里)、作业调度(hadoop集群有很多计算作业)、容错、机器通信等复杂问题
核心思想:分而治之,面对各个海量数据时分解、求解、求合
MapReduce:分:map 把复杂问题分解成若干个简单任务 ;合:reduce
执行流程
从HDFS读入数据,接下来有inPutFormat处理,这是MapReduce的一个类,这个类实现两个功能,一个数据切分,一个记录读取器。数据切分,把大数据块切分成多个小的数据块(spalit),而这些小的数据块作为map的算子要读入的数据源了,map读入数据后做一些逻辑处理,将处理好的数据根据hash算法交个合适的reduce做合并处理
执行流程2
一个map对应一个spalit数据的分片;一个map是一个独立的程序是在计算机上启动一个独立的进程,而进程有自己的独立的内存空间,将数据读进来后存到自己的内存上,这个内存默认大小是100M,当你写到80%时他会把这80M内存空间锁住,然后只能往另外的20%的内存空间去写,而这80%同时是往磁盘里去写,写完这80%内存清空这80%并释放锁,存储磁盘的过程中不是简单的存储,中间还进行一次sort排序;最后磁盘上会产生许多数据块,而这每个数据块都有多种数据,最后通过归并排序将多个数据块的安照数据不同类型做统一的整理,例如每个数据块里有多个100、50、10、5等不同的数字,将所有数据块里的100的数字做整理一块,将50的做整理到一块,10的整理到一块这样的操作,操作的顺序是从大到小。然后reduce机器去取map整理好数据的某一类数据,当取回本机后多个mop相同的数据进行一次合并,最后输出
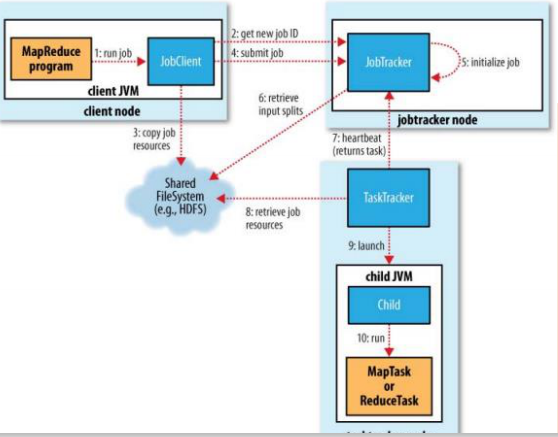
MapReduce的架构实现,两个重要的进程
– JobTracker
• 主进程,负责接收客户作业提交,调度任务到作节点上运行,并提供诸如监控工作节点状态及任务进度等管理功能,一个MapReduce集群有一个jobtracker,一般运行在可靠的硬件上。
• tasktracker是通过周期性的心跳来通知jobtracker其当前的健康状态,每一次心跳包含了可用的map和reduce任务数目、占用的数目以及运行中的任务详细信息。Jobtracker利用一个线程池来同时处理心跳和客户请求TaskTracker
• 由jobtracker指派任务,实例化用户程序,在本地执行任务并周期性地向jobtracker汇报状态。在每一个工作节点上永远只会有一个tasktracker